画像クローラーを題材にしてRabbitMQの有効活用方法を考える
複雑なシステムの中で普遍的で処理順序も保証されなくても問題ない処理をRabbitMQワーカーとして実装する
- 画像クローラーを実装する場合、オリジナルソース(URL)取得ロジックとパーサー処理、画像URL抽出フィルター処理、画像URLダウンロード処理などにわかれると思います。その中で画像URLダウンロード処理に関しては、処理順序が保証される必要もなく普遍的な処理なのでワーカーとして実装できそうです。
複数のシステムの中で共通的な機能をRabbitMQワーカーとして実装する
- 画像クローラーと一口に言ってもTwitterのStreamingから画像のリンクを抽出してクローリングするとか、Pixivからクロールして画像ダウンロードするとか様々だと思います。ただその複数のシステムを実装する必要がある場合、画像URLをダウンロードする機能は共通的な処理になります。画像URLをダウンロードする処理をRabbitMQワーカーとして実装しておけば、たとえTwitter画像クローラーをRubyで実装し、Pixiv画像クローラーをJavaで実装したとしても、画像URLダウンロードする処理実装はひとつで済みます。
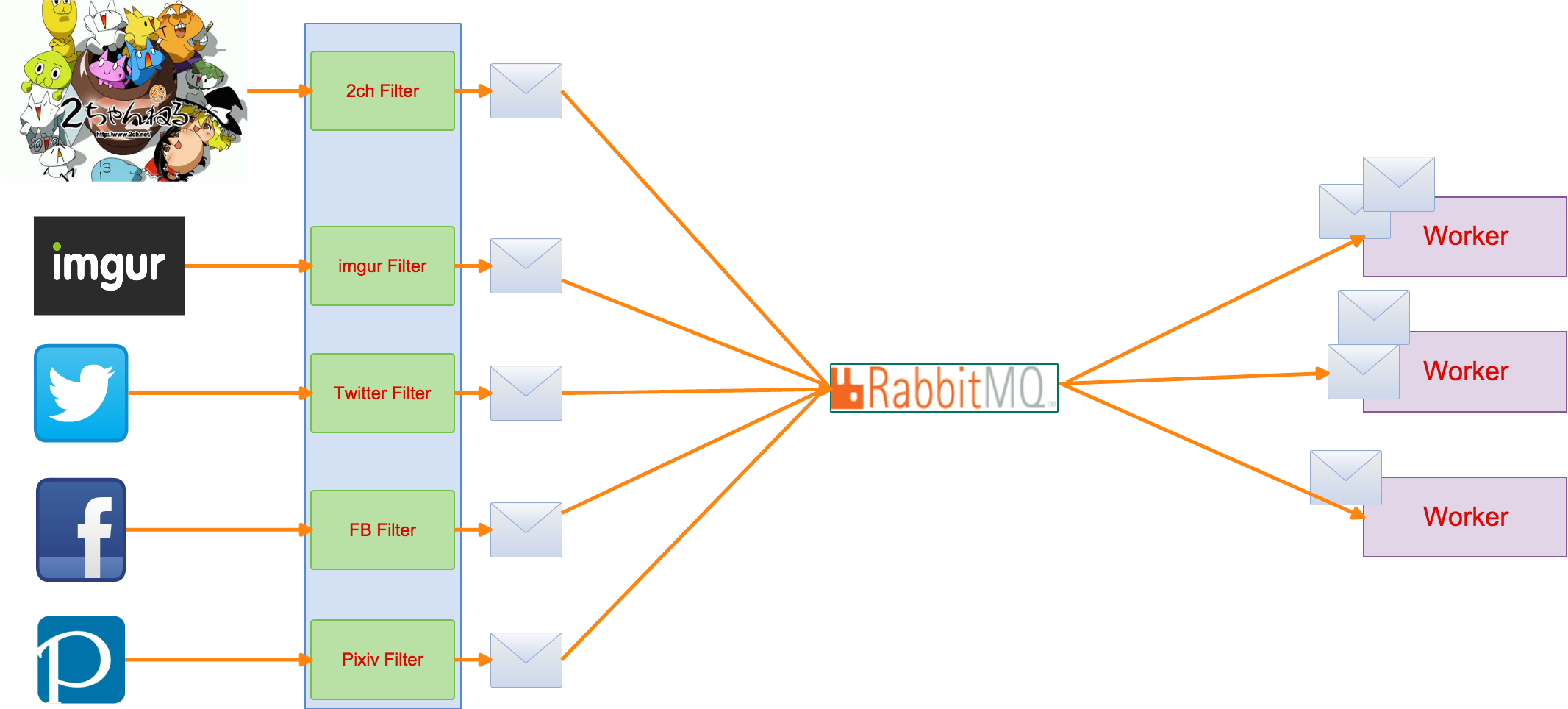
・・というわけでRabbitMQを活用した画像クローラーシステムの概要図は以下になります。
RabbitMQ+画像クローラーシステム
メッセージ構成
| Property | Value | Sample |
|---|---|---|
| Name | ネームスペース | development.download_url |
| Body | [URL][SPACE][ダウンロードパス] | http://i.imgur.com/rqFZVhq.jpg /Users/Siori/code/git_akb428/amqp_rabbitmq_ruby_util_box/private |
Nameを指定することでメッセージの切り分けが可能になります。
環境名(dev/staging/prod)+機能名 や データベース名+テーブル名 のようなイメージでNameを決めると綺麗にメッセージが分けられます。
メッセージ送信部
- 2ch imgur twitter Facebook Pixiv それぞれのクローラーを作成し画像URLが抽出できた段階でRabbitMQにメッセージを送信します。
image_link_send_queue.rb
require "bunny"
download_parent_path = 'ワーカーに画像を保存させたいフォルダを指定'
# extract_image_link 関数を対象のSNSごとに実装する Twitter::extract_image_link とか Pixiv::extract_image_link とか
link_list = extract_image_link(url)
namespace = 'メッセージのNameを指定'
conn = Bunny.new
conn.start
ch = conn.create_channel
q = ch.queue(namespace)
link_list.each do |link|
body = link + ' ' + download_parent_path
ch.default_exchange.publish(body, :routing_key => q.name)
puts " [x] Send #{body}"
end
conn.close
2chのHTMLパーサー+フィルター+メッセージ送信の実装は以下にあります
https://github.com/AKB428/megaris
メッセージ受信部(worker)
ワーカーは予測される負荷(ダウンロード数)に応じて複数のプロセスを任意で立ち上げておきます。
このシステムのメリットはワーカー処理実装は1つで済むことです。
receive_object_strage_queue.rb
#RabbitMQモジュールを指定
require "bunny"
require './lib/download.rb'
conn = Bunny.new
conn.start
ch = conn.create_channel
#Nameを指定
q = ch.queue("development.download_url")
puts " [*] Waiting for messages in #{q.name}. To exit press CTRL+C"
while(true) do
q.subscribe(:block => true) do |delivery_info, properties, body|
puts " [x] Received #{body}"
body_list = body.split(' ')
url = body_list[0]
opt = {
'dest_folder' => body_list[1].nil? ? './' : body_list[1]
}
puts url
p opt
download_path = download(url, opt)
puts " [x] Download #{download_path}"
end
end
lib/download.rb
require 'uri'
require 'httpclient'
require 'pathname'
def download(url, opt)
http_client = HTTPClient.new
header = nil
query = nil
dest_file = File.join('./', File.basename(url))
if opt.has_key?('dest_folder')
conf_dest = File.expand_path(opt['dest_folder'])
dest_file = File.join(conf_dest, File.basename(url))
FileUtils.mkdir_p(conf_dest) unless File.exist?(conf_dest)
end
http_client.receive_timeout = 60 * 10
if opt.has_key?('receive_timeout')
http_client.receive_timeout = opt['receive_timeout']
end
open(dest_file, 'wb') do |file|
http_client.get_content(URI.parse(URI.encode(url)), query, header) do |chunk|
file.write chunk
end
end
dest_file
end
メッセージパッキング
今回はデバッグを考慮してメッセージを構造化しませんでしたが、メッセージ・キューでメッセージを送る場合はオブジェクトをシリアライズした形で格納するのがスタンダードなのでJSON形式か、MessagePackを使用してメッセージのやりとりをするのがベターです。
RabbitMQを使うメリット
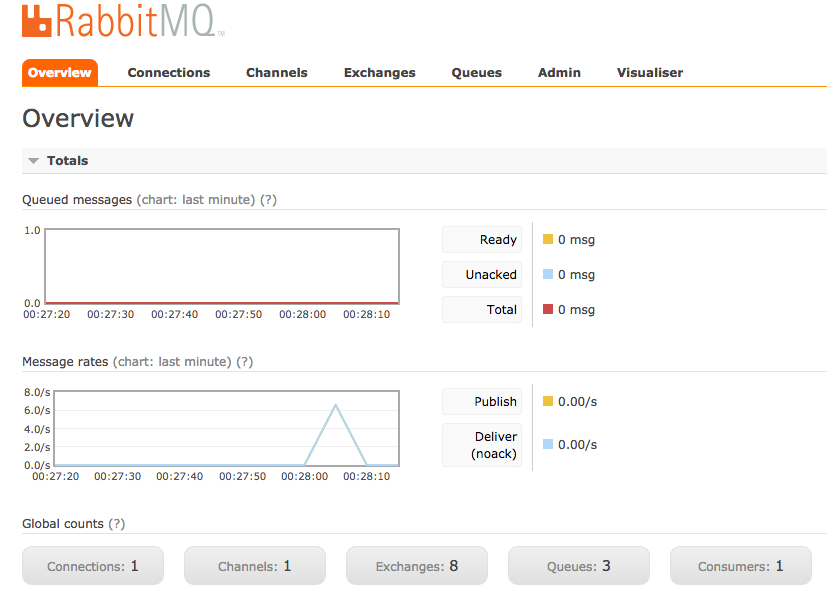
RabbitMQはデフォルトで高機能な管理WEBモニタがついているのでワーカーの負荷などもわりと簡単に視覚的に把握できるので便利だと思います。
(Apache Kafkaはアドオンを追加しないと管理画面は使えない)
RabbitMQは天下のErlangで実装してある
・・ので安定してそう。
RabbitMQのErlang processesは100万ぐらい生成できるようです(MacBookAir mem8Gのデフォルト設定)
メッセージ・キュー、その他の製品の選択肢
最近はApache Kafkaが流行ってるのでRabbitMQの代替として検討してみる価値はあると思います。