動作環境
GeForce GTX 1070 (8GB)
ASRock Z170M Pro4S [Intel Z170chipset]
Ubuntu 16.04 LTS desktop amd64
TensorFlow v1.2.1
cuDNN v5.1 for Linux
CUDA v8.0
Python 3.5.2
IPython 6.0.0 -- An enhanced Interactive Python.
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609
GNU bash, version 4.3.48(1)-release (x86_64-pc-linux-gnu)
学習コードv0.1 http://qiita.com/7of9/items/5819f36e78cc4290614e
http://qiita.com/7of9/items/208507343e7534de4698
の続き。
概要
This article is related to ADDA (light scattering simulator based on the discrete dipole approximation).
- TFRecordsを読込んで学習する
- input: 5 nodes
- output: 6 nodes
- サンプル数: 223,872
- 学習データ: ADDAにより計算した値
- #input
- x,y,z: dipole position
- refractive index: real and imaginary part
- #output
- initial values for linear equation solution for (x,y,z),(real,imaginary)
5次元関数の補間を学習させようとしている。
(5次元の回帰問題というのだろうか?)
変更点
refractive indexの分割を21(real part) x 21(imaginary part)に増やした。
- サンプル数: 4,113,648
より細かい補間ができるだろうかという思惑。
group_run_adda_170819.py
import subprocess as sb
import numpy as np
import sys
# on Python 3.5.2
# codingrule: PEP8
RUN_PARAM = "-store_int_field -grid 26"
# RUN_PARAM = "-store_int_field" # for test
# real part of refractive index (linear scale)
R_RANGE = 0.05 # linear
R_NUM = 21
R_CENTER = 1.45
mrs = np.linspace(R_CENTER - R_RANGE, R_CENTER + R_RANGE, R_NUM)
# imaginary part of refractive index (logarithmic scale)
I_RANGE = 1 # linear
I_NUM = 21
I_CENTER = -4
mis = 10**np.linspace(I_CENTER - I_RANGE, I_CENTER + I_RANGE, I_NUM)
# debug
#print(mrs)
#print(mis)
#sys.exit()
for amr in mrs:
for ami in mis:
print(amr, ami)
cmd = "./adda -m %f %f %s" % (amr, ami, RUN_PARAM)
print(cmd)
sb.run(cmd.split(), stdout=sb.DEVNULL)
上記の結果ファイルをTFRecords化して、combined_IntField-Y_170819.tfrecordsというファイルに合成した。
学習コード v0.2
http://qiita.com/7of9/items/174f9956098127bade54
において事前計算した出力層の(mean, stddev)を用いて、出力層の標準化を行っている。
learn_mr_mi_170819.py
import numpy as np
import tensorflow as tf
import tensorflow.contrib.slim as slim
import sys
"""
v0.2 Aug. 26, 2017
- set (mean, stddev) obtained from [calc_mean_std_170826b.py]
v0.1 Aug. 19, 2017
- (mean, stddev) is fixed to (1.0, 0.0)
- change [IN_FILE] to those with _170819 prefix
+ 21 Re{m}, 21 Im{m} centered with m=1.45 + 0.0001i
=== branched from [learn_mr_mi_170722.py] ===
v0.14 Aug. 12, 2017
- multiply step by 10
- learn with six output nodes
v0.13 Aug. 12, 2017
- standardize output with (mean, stddev)
+ read_and_decode() handles standardization
+ add standardize_data()
v0.12 Aug. 08, 2017
- handles only one output
- delete dropout
- add dropout
v0.3 - v0.11 Jul. 22 - Aug. 08, 2017
- play around with network parameters
+ batch size
+ learning rate
+ hidden layer nodes' numbers
v0.2 Jul. 22, 2017
- increase step from [30000] to [90000]
- change [capacity]
v0.1 Jul. 22, 2017
- increase network structure from [7,7,7] to [100,100,100]
- increase dimension of [input_ph], [output_ph]
- alter read_and_decode() to treat 5 input-, 6 output- nodes
- alter [IN_FILE] to the symbolic linked file
:reference: [learnExr_170504.py] to expand dimensions to [input:3,output:6]
=== branched from [learn_sineCurve_170708.py] ===
v0.6 Jul. 09, 2017
- modify for PEP8
- print prediction after learning
v0.5 Jul. 09, 2017
- fix bug > [Attempting to use uninitialized value hidden/hidden_1/weights]
v0.4 Jul. 09, 2017
- fix bug > stops only for one epoch
+ set [num_epochs=None] for string_input_producer()
- change parameters for shuffle_batch()
- implement training
v0.3 Jul. 09, 2017
- fix warning > use tf.local_variables_initializer() instead of
initialize_local_variables()
- fix warning > use tf.global_variables_initializer() instead of
initialize_all_variables()
v0.2 Jul. 08, 2017
- fix bug > OutOfRangeError (current size 0)
+ use [tf.initialize_local_variables()]
v0.1 Jul. 08, 2017
- only read [.tfrecords]
+ add inputs_xy()
+ add read_and_decode()
"""
# codingrule: PEP8
#IN_FILE = 'LN-IntField-Y_170722.tfrecords'
IN_FILE = 'LN-IntField-Y_170819.tfrecords'
def standardize_data(ax, mean, stddev):
return (ax - mean) / stddev
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'xpos_raw': tf.FixedLenFeature([], tf.string),
'ypos_raw': tf.FixedLenFeature([], tf.string),
'zpos_raw': tf.FixedLenFeature([], tf.string),
'mr_raw': tf.FixedLenFeature([], tf.string),
'mi_raw': tf.FixedLenFeature([], tf.string),
'exr_raw': tf.FixedLenFeature([], tf.string),
'exi_raw': tf.FixedLenFeature([], tf.string),
'eyr_raw': tf.FixedLenFeature([], tf.string),
'eyi_raw': tf.FixedLenFeature([], tf.string),
'ezr_raw': tf.FixedLenFeature([], tf.string),
'ezi_raw': tf.FixedLenFeature([], tf.string),
})
xpos_raw = tf.decode_raw(features['xpos_raw'], tf.float32)
ypos_raw = tf.decode_raw(features['ypos_raw'], tf.float32)
zpos_raw = tf.decode_raw(features['zpos_raw'], tf.float32)
mr_raw = tf.decode_raw(features['mr_raw'], tf.float32)
mi_raw = tf.decode_raw(features['mi_raw'], tf.float32)
exr_raw = tf.decode_raw(features['exr_raw'], tf.float32)
exi_raw = tf.decode_raw(features['exi_raw'], tf.float32)
eyr_raw = tf.decode_raw(features['eyr_raw'], tf.float32)
eyi_raw = tf.decode_raw(features['eyi_raw'], tf.float32)
ezr_raw = tf.decode_raw(features['ezr_raw'], tf.float32)
ezi_raw = tf.decode_raw(features['ezi_raw'], tf.float32)
xpos_org = tf.reshape(xpos_raw, [1])
ypos_org = tf.reshape(ypos_raw, [1])
zpos_org = tf.reshape(zpos_raw, [1])
mr_org = tf.reshape(mr_raw, [1])
mi_org = tf.reshape(mi_raw, [1])
exr_org = tf.reshape(exr_raw, [1])
exi_org = tf.reshape(exi_raw, [1])
eyr_org = tf.reshape(eyr_raw, [1])
eyi_org = tf.reshape(eyi_raw, [1])
ezr_org = tf.reshape(ezr_raw, [1])
ezi_org = tf.reshape(ezi_raw, [1])
# input
wrk = [xpos_org[0], ypos_org[0], zpos_org[0], mr_org[0], mi_org[0]]
inputs = tf.stack(wrk)
# for standardization
# obtained from [calc_mean_std_170826b.py]
means = (0.000000, 0.000000, -0.020458, 0.015096, 0.000000, 0.000000)
stddevs = (0.135288, 0.108794, 0.803743, 0.617177, 0.201634, 0.325543)
# --- w/o standardization
# out_exr = exr_org[0]
# --- w/ standardization
out_exr = standardize_data(exr_org[0], means[0], stddevs[0])
out_exi = standardize_data(exi_org[0], means[1], stddevs[1])
out_eyr = standardize_data(eyr_org[0], means[2], stddevs[2])
out_eyi = standardize_data(eyi_org[0], means[3], stddevs[3])
out_ezr = standardize_data(ezr_org[0], means[4], stddevs[4])
out_ezi = standardize_data(ezi_org[0], means[5], stddevs[5])
# --- six outputs
wrk = [out_exr, out_exi,
out_eyr, out_eyi,
out_ezr, out_ezi]
# --- single output
# wrk = [out_ezi]
#
outputs = tf.stack(wrk)
return inputs, outputs
def inputs_xy():
filename = IN_FILE
filequeue = tf.train.string_input_producer(
[filename], num_epochs=None)
in_org, out_org = read_and_decode(filequeue)
return in_org, out_org
in_orgs, out_orgs = inputs_xy()
batch_size = 2 # [2]
# Ref: cifar10_input.py
min_fraction_of_examples_in_queue = 0.2 # 0.4
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = 4113648 # 223872 or 9328
min_queue_examples = int(NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN *
min_fraction_of_examples_in_queue)
cpcty = min_queue_examples + 3 * batch_size
in_batch, out_batch = tf.train.shuffle_batch([in_orgs, out_orgs],
batch_size,
capacity=cpcty,
min_after_dequeue=batch_size)
input_ph = tf.placeholder("float", [None, 5])
output_ph = tf.placeholder("float", [None, 6]) # [6]
#output_ph = tf.placeholder("float", [None, 1]) # [6]
# network
hiddens = slim.stack(input_ph, slim.fully_connected, [30, 100, 100],
activation_fn=tf.nn.sigmoid, scope="hidden")
# --- six outputs
prediction = slim.fully_connected(hiddens, 6,
activation_fn=None, scope="output")
# --- only one output
# prediction = slim.fully_connected(hiddens, 1,
# activation_fn=None, scope="output")
loss = tf.contrib.losses.mean_squared_error(prediction, output_ph)
train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer())
init_op = [tf.global_variables_initializer(), tf.local_variables_initializer()]
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for idx in range(30000000): # 3000000
inpbt, outbt = sess.run([in_batch, out_batch])
# print(outbt) # debug
_, t_loss = sess.run([train_op, loss],
feed_dict={input_ph: inpbt, output_ph: outbt})
if (idx + 1) % 100 == 0:
print("%d,%f" % (idx+1, t_loss))
# sys.stdout.flush() # not good for Matplotlib drawing
finally:
coord.request_stop()
# output the model
model_variables = slim.get_model_variables()
res = sess.run(model_variables)
np.save('model_variables_170722.npy', res)
coord.join(threads)
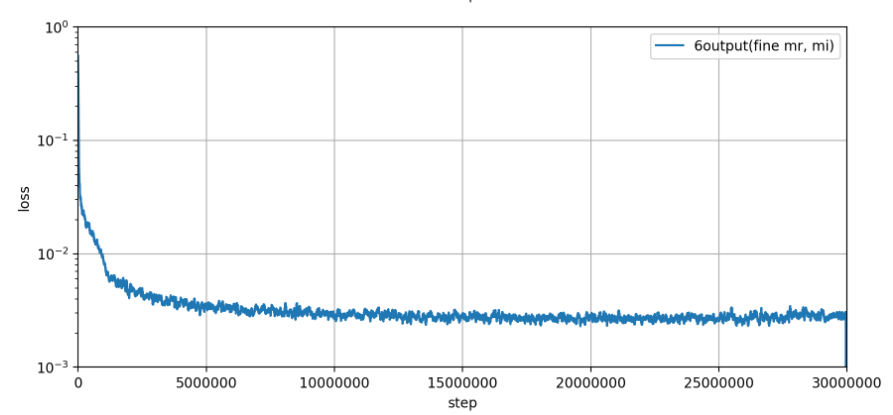
lossの経過
線形方程式の初期値の計算
上記の学習したネットワークを用いて線形方程式の初期値を計算した。
データの標準化を行っているため、EXR, EXIなどそれぞれに対して(mean, stddev)を用いて、元のスケールに戻している。
replace_by_NN_outputStdzd_170826.py
import numpy as np
import tensorflow as tf
import tensorflow.contrib.slim as slim
import sys
import os
import math
"""
v0.1 Aug. 26, 2017
- change (mean, stddev) to those calculated from the TFRecords file
=== branched from [replace_by_NN_outputStdzd_170826.py] ===
v0.1 Aug. 12, 2017
- take [standardized output-node-data] into account
+ calculate original value using (mean, stddev)
+ add calc_inverse_standardized()
=== branched from [replace_by_NN_170729.py] ===
v0.4 Aug. 05, 2017
- remove os.remove() and use open(OUT_FILE, 'wb+')
v0.3 Jul. 29, 2017
- replace [exr, exi, eyr, eyi, ezr, ezi]
- add convolution calculations
+ calc_sigmoid()
+ add calc_conv()
v0.2 Jul. 29, 2017
- add calc_e2()
v0.1 Jul. 29, 2017
- read and output IntField-Y file without modification
"""
# on
# Ubuntu 16.04 LTS
# TensorFlow v1.2.1
# Python 3.5.2
# IPython 6.0.0 -- An enhanced Interactive Python.
def calc_sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
def calc_conv(src, weight, bias, applyActFnc):
wgt = weight.shape
conv = [0.0] * bias.size
# weight
for idx2 in range(wgt[1]):
tmp_vec = weight[:, idx2] * src[:]
conv[idx2] = tmp_vec.sum()
# bias
for idx2 in range(wgt[1]):
conv[idx2] = conv[idx2] + bias[idx2]
# activation function
if applyActFnc:
for idx2 in range(wgt[1]):
conv[idx2] = calc_sigmoid(conv[idx2])
return conv # return list
def calc_e2(xr, xi, yr, yi, zr, zi):
xx = xr*xr + xi*xi
yy = yr*yr + yi*yi
zz = zr*zr + zi*zi
return (xx + yy + zz)
def calc_inverse_standardized(aval, mean, stddev):
return (aval * stddev + mean)
def calc_original(exr, exi, eyr, eyi, ezr, ezi):
# for standardization
# obtained from [calc_mean_std_170812.py]
means = (0.000000, 0.000000, -0.020458, 0.015096, 0.000000, 0.000000)
stddevs = (0.135288, 0.108794, 0.803743, 0.617177, 0.201634, 0.325543)
exr = calc_inverse_standardized(exr, means[0], stddevs[0])
exi = calc_inverse_standardized(exi, means[1], stddevs[1])
eyr = calc_inverse_standardized(eyr, means[2], stddevs[2])
eyi = calc_inverse_standardized(eyi, means[3], stddevs[3])
ezr = calc_inverse_standardized(ezr, means[4], stddevs[4])
ezi = calc_inverse_standardized(ezi, means[5], stddevs[5])
return exr, exi, eyr, eyi, ezr, ezi
INP_FILE = 'LN-IntField-Y.in'
OUT_FILE = 'IntField-Y.out_170729'
NETWORK_FILE = 'LN-model_variables_170722.npy'
HEADER_TXT = 'x y z |E|^2 Ex.r Ex.i Ey.r Ey.i Ez.r Ez.i'
dat = np.genfromtxt(INP_FILE, delimiter=' ',
skip_header=1) # skip header line
model_var = np.load(NETWORK_FILE)
# TODO: 0m > runtime parameter for real(m) and imag(m)
amr = 1.45
ami = 0.0001
with open(OUT_FILE, 'wb+') as fhndl:
# line 1
hdr = np.array(HEADER_TXT).reshape(1,)
np.savetxt(fhndl, hdr, delimiter=' ', fmt='%s')
# line 2 ..
for aline in dat:
ax, ay, az = aline[0:3]
# e2 = aline[3]
exr, exi = aline[4:6]
eyr, eyi = aline[6:8]
ezr, ezi = aline[8:10]
# input layer (5 nodes)
inlist = (ax, ay, az, amr, ami)
# hidden layer 1
cnv = calc_conv(inlist, model_var[0], model_var[1], applyActFnc=True)
# hidden layer 2
cnv = calc_conv(cnv, model_var[2], model_var[3], applyActFnc=True)
# hidden layer 3
cnv = calc_conv(cnv, model_var[4], model_var[5], applyActFnc=True)
# output layer
cnv = calc_conv(cnv, model_var[6], model_var[7], applyActFnc=False)
# print(exr, exi, eyr, eyi, ezr, ezi)
# print(cnv)
# sys.exit()
exr, exi = cnv[0:2]
eyr, eyi = cnv[2:4]
ezr, ezi = cnv[4:6]
# from [standardized] to [original]
res = calc_original(exr, exi, eyr, eyi, ezr, ezi)
exr, exi, eyr, eyi, ezr, ezi = res
e2 = calc_e2(exr, exi, eyr, eyi, ezr, ezi)
res = ax, ay, az, e2, exr, exi, eyr, eyi, ezr, ezi
np.savetxt(fhndl, np.c_[res], delimiter=' ', fmt='%.10f')
相対誤差のヒストグラム
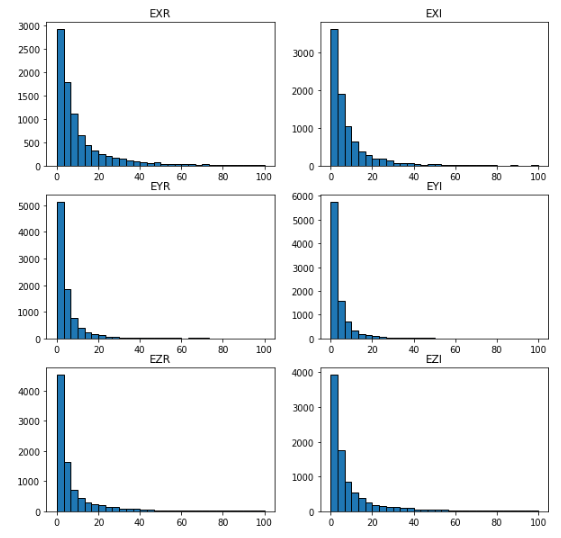
http://qiita.com/7of9/items/208507343e7534de4698
の結果と比べて、多少良くなった程度。
学習結果を用いた計算
$ ./adda -m 1.45 0.0001 -grid 26 -init_field read REPLACE_NN_170826/IntField-Y.out_170729
all data is saved in 'run871_sphere_g26_m1.45'
box dimensions: 26x26x26
lambda: 6.283185307 Dipoles/lambda: 14.5
Required relative residual norm: 1e-05
Total number of occupied dipoles: 9328
Memory usage for MatVec matrices: 5.3 MB
Calculating Green's function (Dmatrix)
Fourier transform of Dmatrix......
Initializing FFTW3
Total memory usage: 9.0 MB
here we go, calc Y
CoupleConstant:0.005318998739+1.990081942e-05i
x_0 = from file REPLACE_NN_170826/IntField-Y.out_170729
RE_000 = 8.0828143016E-02
RE_001 = 4.3796013930E-02 +
RE_002 = 2.7686389796E-02 +
RE_003 = 2.1238342921E-02 +
RE_004 = 1.8964691425E-02 +
RE_005 = 1.1018056726E-02 +
RE_006 = 7.4916243907E-03 +
RE_007 = 5.1772530690E-03 +
RE_008 = 4.8785371425E-03 +
RE_009 = 4.9802238776E-03 -
RE_010 = 5.2504416165E-03 -
RE_011 = 4.2690002571E-03 +
RE_012 = 3.1685278923E-03 +
RE_013 = 2.6174264799E-03 +
RE_014 = 2.6016756154E-03 +
RE_015 = 2.3584510031E-03 +
RE_016 = 1.7003888586E-03 +
RE_017 = 1.3990280249E-03 +
RE_018 = 9.8604780346E-04 +
RE_019 = 8.8669068492E-04 +
RE_020 = 7.7118120643E-04 +
RE_021 = 6.8573683918E-04 +
RE_022 = 6.5492219149E-04 +
RE_023 = 6.3707956187E-04 +
RE_024 = 4.8914436732E-04 +
RE_025 = 5.1093105008E-04 -
RE_026 = 2.4089044336E-04 +
RE_027 = 1.4910854990E-04 +
RE_028 = 1.5072484988E-04 -
RE_029 = 1.4244188684E-04 +
RE_030 = 6.9779271921E-05 +
RE_031 = 4.8513630338E-05 +
RE_032 = 3.9759334275E-05 +
RE_033 = 3.0250660195E-05 +
RE_034 = 3.0624109893E-05 -
RE_035 = 2.3808688545E-05 +
RE_036 = 1.3645831438E-05 +
RE_037 = 1.5681243479E-05 -
RE_038 = 1.6215261182E-05 -
RE_039 = 5.0420645604E-06 +
Cext = 357.7376669
Qext = 3.556240432
Cabs = 0.2646840443
Qabs = 0.0026312021
- 初期誤差
- 前回: 1.1570404113E-01
- 今回: 8.0828143016E-02
初期誤差は前回の半分になった。改善している。
しかしながら、iterationの回数(39)に変化はなかった。