1.tsukumoの良い品をお安く買いたい
という理由で作った。
2.使い方
ソースコード(サイト下部)をコンパイルして、
batファイルで起動できるようにする。(と便利)
batファイル、classファイルを同一ディレクトリに入れる。
そのディレクトリに、URL.txtを作る。
URL.txtに調べたい製品のURLを入力する
URL.txtの例
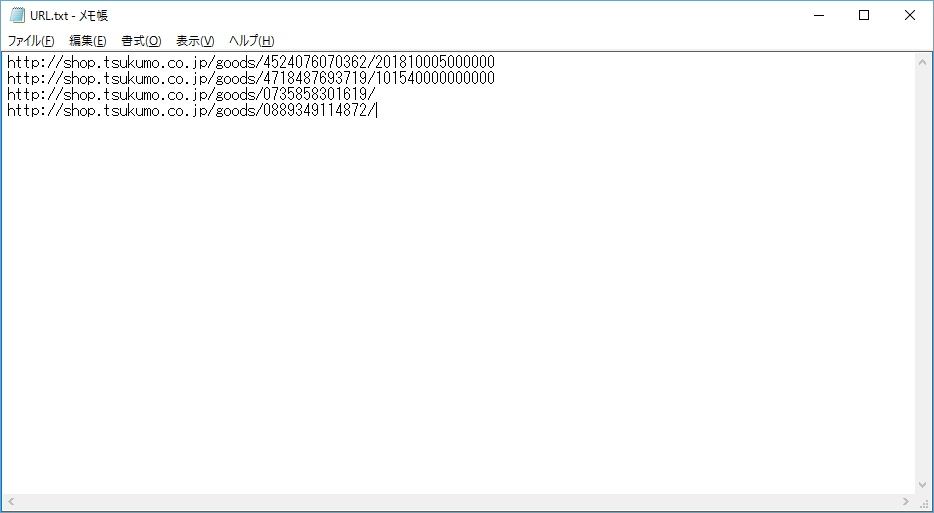
URL.txtを保存し、batファイルを実行。
batファイル実行後 商品は4個書いている。
ファイルが半端なくできているので、なんとかしたい。
(1つ言うと、商品を増やさなければこれ以上は増えない(当たり前か・・・))
CSVに価格が出る。
CSVには情報が上書きされていくので、
batファイルを実行させただけデータが溜まる。
↓こんな感じ
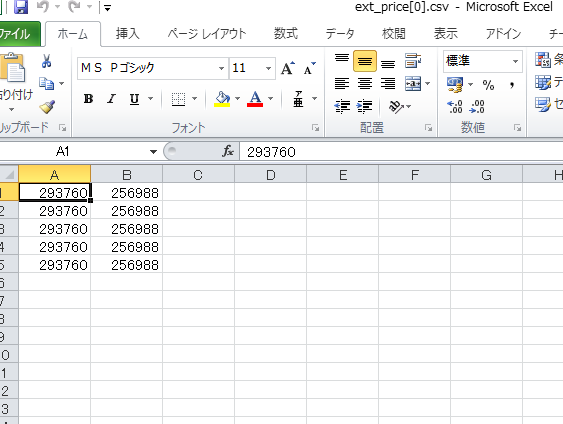
実験台をQuadroの高いやつでやってるからこうなってる。
値段が2個あるのは、
ウェブ価格、ズバリ価格。
2つ以上の値段が大きく違う場合は
セット販売の値段も入っているから。
↓その例
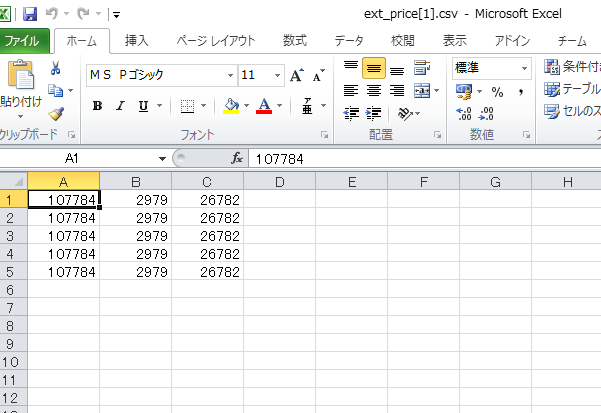
商品は HTC Vive
抱き合わせは ニンジャマスクとスタンドセットのようだ。
3.総括
一応できた としか言えない。
ファイルがめちゃくちゃたくさんできるなど、課題は山積み。
try、catch分の囲みが気持ち悪い(ソース参照)
変数もガバガバ (ソース参照)
ただ1つ言わせてもらうと、処理をブロックでまとめれたことで、
保守性は上がったし、変数の使い捨てが結構できたので、ブロック内での変数の意味がわかればそれで良しとする所があった。
(個人的な感想です。 万人には共通するものではないかもしれません。)
4.おまちかね(待ってない)ソースコード
スパゲッティのtry catch文
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class watson{
public static void main(String args[]){
File r_file = new File("URL.txt"); // しりたいURLファイル読み込み
FileReader u_fil = null;
BufferedReader u_bfi = null;
String urline;
int mono=0;
try { //urlファイルの読み込み
u_fil = new FileReader(r_file);
} catch (FileNotFoundException e2) {
e2.printStackTrace();
}
u_bfi = new BufferedReader(u_fil);
try { //urlファイルのEOFの行まで読み込み 126行目で終了
while ((urline = u_bfi.readLine()) != null) { //こいつのtryは125行目まである
try{
URL url = new URL(urline);
URLConnection connection = url.openConnection();
connection.setDoInput(true);
InputStream inStream = connection.getInputStream();
BufferedReader input = new BufferedReader(new InputStreamReader(inStream,"utf-8"));
File file1 = new File("ext_item["+mono+"].txt"); // 保存先
FileOutputStream out1 = new FileOutputStream(file1, false);
int item;
while((item = input.read()) != -1){
out1.write(item);
}
out1.close();
}
catch (Exception e){
System.exit(-1);
}
//txt 値段抽出
try{
StringBuffer sb1;
File file_re1 = new File("ext_item["+mono+"].txt");
BufferedReader br_re1 = new BufferedReader(new FileReader(file_re1));
File file_ex1 = new File("ext_price["+mono+"].txt");
FileWriter file_wr1 = new FileWriter(file_ex1);
String str_1;
while((str_1 = br_re1.readLine()) != null){
sb1=new StringBuffer(str_1);
int moji1=str_1.indexOf("¥");
if(moji1 != -1){
str_1=str_1.substring(moji1+6);
int moji2=str_1.indexOf("</span>");
if(moji2 != -1){
str_1=str_1.substring(0,moji2);
file_wr1.write(str_1+"\r\n");
}
}
}
br_re1.close();
file_wr1.close();
}
catch(FileNotFoundException e){
System.exit(-1);
}
catch(IOException e){
System.exit(-1);
}
//txt 値段抽出 終了
//コンマの消去とCSV化
FileReader rem_con_F = null;
BufferedReader rem_con_B = null;
String rem_con_s;
String regex = ","; //見つける文字列
Pattern p;
Matcher m;
rem_con_F = new FileReader("ext_price["+mono+"].txt");
rem_con_B = new BufferedReader(rem_con_F);
File rem_con_EXT = new File("ext_price["+mono+"].csv");
PrintWriter rem_con_pw = new PrintWriter(new BufferedWriter(new FileWriter(rem_con_EXT,true)));
while ((rem_con_s = rem_con_B.readLine()) != null) {
p = Pattern.compile(regex);
m = p.matcher(rem_con_s);
rem_con_s=m.replaceAll("");
rem_con_pw.print(rem_con_s+",");
}
rem_con_pw.println(); //改行
rem_con_B.close();
rem_con_pw.close();
mono++;
}//1連の処理終わり
}//urlファイルのEOFの行まで読み込み
//コンマの消去とCSV化 おわり 総処理終わり
catch (IOException e1) {
e1.printStackTrace();
}
System.out.println("Done!");
}
}
コメントの指摘であった「Jsoup」を使うとこうなる
上のソースコードは136行あったのに、
下のソースコードは68行しかないです。
半分になって、とてもスッキリです
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
class watsonX{
public static void main(String args[]){
File r_file = new File("URL.txt"); // しりたいURLファイル読み込み
FileReader u_fil = null;
BufferedReader u_bfi = null;
String urline;
int mono=0;
try { //urlファイルの読み込み
u_fil = new FileReader(r_file);
} catch (FileNotFoundException e2) {
e2.printStackTrace();
}
u_bfi = new BufferedReader(u_fil);
String regex = ","; //見つける文字列
Pattern p;
Matcher m;
try { //urlファイルのEOFの行まで読み込み 126行目で終了
File file = new File("EXT.csv");
PrintWriter pw = new PrintWriter(new BufferedWriter(new FileWriter(file,true)));
while ((urline = u_bfi.readLine()) != null) { //こいつのtryは125行目まである
String price; //値段
Document doc = Jsoup.connect(urline).get();
Elements es = doc.select("span.price");
for (Element e : es){
price=e.text(); //値段を格納
p = Pattern.compile(regex);
m = p.matcher(price);
price=m.replaceAll("");
price=price.substring(1, price.length());
System.out.println(price);
pw.print(price+",");
}
pw.println("");
}//1連の処理終わり
pw.close();
}//urlファイルのEOFの行まで読み込み
//コンマの消去とCSV化 おわり 総処理終わり
catch (IOException e) {
e.printStackTrace();
}
System.out.println("Done!");
}
}
5.作者からのコメント
悪用はいけませんよ? ^^
サーバーへの負荷がかかって、
使えなくなったらどうしようもないですから。
タスクスケジューラを使って1日1回確認するなどすると、
便利かもしれません。(やってはないし、やり方わからないし。)
以上です。
拙作を最後まで見てくださって
ありがとうございました。