はじめに
これ以外にやることができたので続きは夏休み明けにやろうかなと思いながらの更新です.
もし何かためになるアドバイス等があれば優しいコメントを残して頂けると幸いですm(_ _)m
コードだけはコチラへ.
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
問題30 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
def load_mecab_data(filename: str) -> list:
"""
mecabの形態素解析の出力をパースする関数
Parameter
----------
filename: str
形態素解析結果を格納したファイル
Return
----------
morph_text: str
パースされたデータ
"""
morph_text = []
with open(filename, 'r') as f:
sentence = []
for line in f:
if line.rstrip('\n') == 'EOS':
if bool(sentence):
morph_text.append(sentence)
sentence = []
else:
split_t = line.split('\t')
split_c = split_t[1].split(',')
sentence.append({'surface': split_t[0], 'base': split_c[6], 'pos': split_c[0], 'pos1': split_c[1]})
return morph_text
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
if __name__ == '__main__':
main()
$ cat neko.txt.mecab
一 名詞,数,*,*,*,*,一,イチ,イチ
EOS
EOS
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
EOS
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
まだ 副詞,助詞類接続,*,*,*,*,まだ,マダ,マダ
無い 形容詞,自立,*,*,形容詞・アウオ段,基本形,無い,ナイ,ナイ
。 記号,句点,*,*,*,*,。,。,。
EOS
EOS
記号,空白,*,*,*,*, , ,
どこ 名詞,代名詞,一般,*,*,*,どこ,ドコ,ドコ
...
EOS
太平 名詞,一般,*,*,*,*,太平,タイヘイ,タイヘイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
死な 動詞,自立,*,*,五段・ナ行,未然形,死ぬ,シナ,シナ
なけれ 助動詞,*,*,*,特殊・ナイ,仮定形,ない,ナケレ,ナケレ
ば 助詞,接続助詞,*,*,*,*,ば,バ,バ
得 動詞,自立,*,*,一段,未然形,得る,エ,エ
られ 動詞,接尾,*,*,一段,未然形,られる,ラレ,ラレ
ぬ 助動詞,*,*,*,特殊・ヌ,基本形,ぬ,ヌ,ヌ
。 記号,句点,*,*,*,*,。,。,。
EOS
南無阿弥陀仏 名詞,一般,*,*,*,*,南無阿弥陀仏,ナムアミダブツ,ナムアミダブツ
南無阿弥陀仏 名詞,一般,*,*,*,*,南無阿弥陀仏,ナムアミダブツ,ナムアミダブツ
。 記号,句点,*,*,*,*,。,。,。
EOS
ありがたい 形容詞,自立,*,*,形容詞・アウオ段,基本形,ありがたい,アリガタイ,アリガタイ
ありがたい 形容詞,自立,*,*,形容詞・アウオ段,基本形,ありがたい,アリガタイ,アリガタイ
。 記号,句点,*,*,*,*,。,。,。
EOS
EOS
問題31 動詞
動詞の表層形をすべて抽出せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def extract_surface_form_verb(morph_text: list) -> set:
"""
形態素解析結果のリストから動詞の表層形を抽出する関数
Parameter
----------
morph_text: list
形態素解析結果のリスト
Return
----------
動詞の表層形の集合
"""
return set([morph['surface'] for sentence in morph_text for morph in sentence if morph['pos'] == '動詞'])
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
surface_form_verbs = extract_surface_form_verb(morph_text)
# 全部
print(surface_form_verbs)
print('----------')
# 取れた数
print(len(surface_form_verbs))
print('----------')
# 先頭20個
print(list(surface_form_verbs)[0:20])
if __name__ == '__main__':
main()
{'仕損じ', '作ろ', '成っ', '切り落す', '習っ', ... '撚', 'おき', '舐め', 'さておい', '押し倒し'}
----------
3893
----------
['仕損じ', '作ろ', '成っ', '切り落す', '習っ', 'かか', '結っ', '捕まる', '纏まる', '流行っ', 'れよ', 'がっ', '食わせれ', '焦れる', '始まら', '動か', '供える', '限る', '載っ', 'そそのかさ']
問題32 動詞の原形
動詞の原形をすべて抽出せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def extract_base_form_verb(morph_text: list) -> set:
"""
形態素解析結果のリストから動詞の原形を抽出する関数
Parameter
----------
morph_text: list
形態素解析結果のリスト
Return
----------
動詞の原形の集合
"""
return set([morph['base'] for sentence in morph_text for morph in sentence if morph['pos'] == '動詞'])
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
base_form_verbs = extract_base_form_verb(morph_text)
# 全部
print(base_form_verbs)
print('----------')
# 取れた数
print(len(base_form_verbs))
print('----------')
# 先頭20個
print(list(base_form_verbs)[0:20])
if __name__ == '__main__':
main()
{'縛り付ける', 'ぬすむ', 'こむ', '奢る', '小突く', ... '洒落る', '有する', '迷い込む', '受け合う', '隠す'}
----------
2300
----------
['縛り付ける', 'ぬすむ', 'こむ', '奢る', '小突く', '被る', '構える', '開け放つ', '包む', 'むく', '糺す', '引越す', '出す', 'しごく', '詰める', '罵る', '余す', 'だく', 'まごつく', '競う']
問題33 サ変名詞
サ変接続の名詞をすべて抽出せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def extract_sahen_noun(morph_text: list) -> set:
"""
形態素解析結果のリストからサ変接続の名詞を抽出する関数
Parameter
----------
morph_text: list
形態素解析結果のリスト
Return
----------
sahen_nouns: set
サ変接続名詞の集合
"""
sahen_nouns = []
for sentence in morph_text:
for morph in sentence:
if morph['pos'] == '名詞' and morph['pos1'] == 'サ変接続':
sahen_nouns.append(morph['surface'])
return set(sahen_nouns)
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
sahen_nouns = extract_sahen_noun(morph_text)
# 全部
print(sahen_nouns)
print('----------')
# 取れた数
print(len(sahen_nouns))
print('----------')
# 先頭20個
print(list(sahen_nouns)[0:20])
if __name__ == '__main__':
main()
{'現前', '混雑', '意識', '披瀝', '消費', ... '感謝', '意味', '生息', '分界', '送籍'}
----------
1280
----------
['現前', '混雑', '意識', '披瀝', '消費', '分別', '存', '記', '脱却', '伝染', '照準', '連勝', '超絶', '祈念', '賛', '開陳', '交替', 'ぼんやり', '戦勝', '罵倒']
問題34 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def extract_noun_phrase_with_no(morph_text: list) -> set:
"""
形態素解析結果のリストから「AのB」という形の名詞句を抽出する関数
Parameter
----------
morph_text: list
形態素解析結果のリスト
Return
----------
noun_phrases: set
「AのB」という形の句の集合
"""
noun_phrases = []
for sentence in morph_text:
for idx, morph in enumerate(sentence):
try:
if morph['pos'] == '名詞' and sentence[idx+1]['surface'] == 'の' and sentence[idx+2]['pos'] == '名詞':
noun_phrases.append(morph['surface'] + sentence[idx+1]['surface'] + sentence[idx+2]['surface'])
except IndexError:
pass
return set(noun_phrases)
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
noun_phrases = extract_noun_phrase_with_no(morph_text)
# 全部
print(noun_phrases)
print('----------')
# 取れた数
print(len(noun_phrases))
print('----------')
# 先頭20個
print(list(noun_phrases)[0:20])
if __name__ == '__main__':
main()
{'天下の公民', '顔の真中', '主人の我儘', '襖の影', '事の非', ... '憫然の至り', 'こっちの方', '君の心', '寺院の壁', '度の願'}
----------
4924
----------
['天下の公民', '顔の真中', '主人の我儘', '襖の影', '事の非', '屋根の瓦', '巴里の大学', '唐桟の半纏', 'ツァイシングの黄金', '上の地位', '彼の顔面', '人間の歴史', '衰弱の一族', '台所の十', '元のよう', '作家の頭', '床の間の方', 'いそのビール', '起の方', '一物の上']
問題35 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def extract_compound_noun(morph_text: list) -> set:
"""
形態素解析結果のリストから名詞の連接を抽出する関数
Parameter
----------
morph_text: list
形態素解析結果のリスト
Return
----------
compound_nouns: set
連接名詞の集合
"""
compound_nouns = []
compound_noun = ''
for sentence in morph_text:
for morph in sentence:
if morph['pos'] == '名詞':
compound_noun += morph['surface']
else:
if compound_noun != '':
compound_nouns.append(compound_noun)
compound_noun = ''
# 最後にもし残っていたら
if compound_noun != '':
compound_nouns.append(compound_noun)
return set(compound_nouns)
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
compound_nouns = extract_compound_noun(morph_text)
# 全部
print(compound_nouns)
print('----------')
# 取れた数
print(len(compound_nouns))
print('----------')
# 先頭20個
print(list(compound_nouns)[0:20])
if __name__ == '__main__':
main()
{'ハハハハじじい', '乱暴者', '気色', '感慨', '空也餅引掛所', ... '欅', '彼等', '慚愧', '幅一尺', '嘴'}
----------
11302
----------
['ハハハハじじい', '乱暴者', '気色', '感慨', '空也餅引掛所', '毎日事務', '金子善兵衛方', '二枚かけ', '三尺', '太人中', '午睡', '増減', '吾輩自ら余瀾', '国賊', '物色', '三冊', '赤裸', '安全', '訓義', '覚']
問題36 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
def word_count(morph_text: list, order_type: bool) -> list:
"""
形態素解析結果のリストから単語とその頻度を算出して返す関数
Parameters
----------
morph_text: list
形態素解析結果のリスト
order_type: bool
昇順か降順のフラグ(T: 降順,F: 昇順)
Return
----------
word_count_list: list[tuple]
連接名詞の集合
"""
word_count_list = {}
for sentence in morph_text:
for morph in sentence:
if morph['surface'] in word_count_list:
word_count_list[morph['surface']] += 1
else:
word_count_list[morph['surface']] = 1
return sorted(word_count_list.items(), key = lambda x: x[1], reverse = order_type)
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
word_count_list = word_count(morph_text, True)
# 全部
print(word_count_list)
print('----------')
# 取れた数
print(len(word_count_list))
print('----------')
# 先頭20個
print(word_count_list[0:20])
if __name__ == '__main__':
main()
[('の', 9194), ('。', 7486), ('て', 6868), ('、', 6772), ('は', 6420), ... ('あせっ', 1), ('拷問', 1), ('ぎりご', 1), ('切り落し', 1), ('韲', 1)]
----------
13584
----------
[('の', 9194), ('。', 7486), ('て', 6868), ('、', 6772), ('は', 6420), ('に', 6243), ('を', 6071), ('と', 5508), ('が', 5337), ('た', 3988), ('で', 3806), ('「', 3231), ('」', 3225), ('も', 2479), ('ない', 2390), ('だ', 2363), ('し', 2322), ('から', 2032), ('ある', 1728), ('な', 1613)]
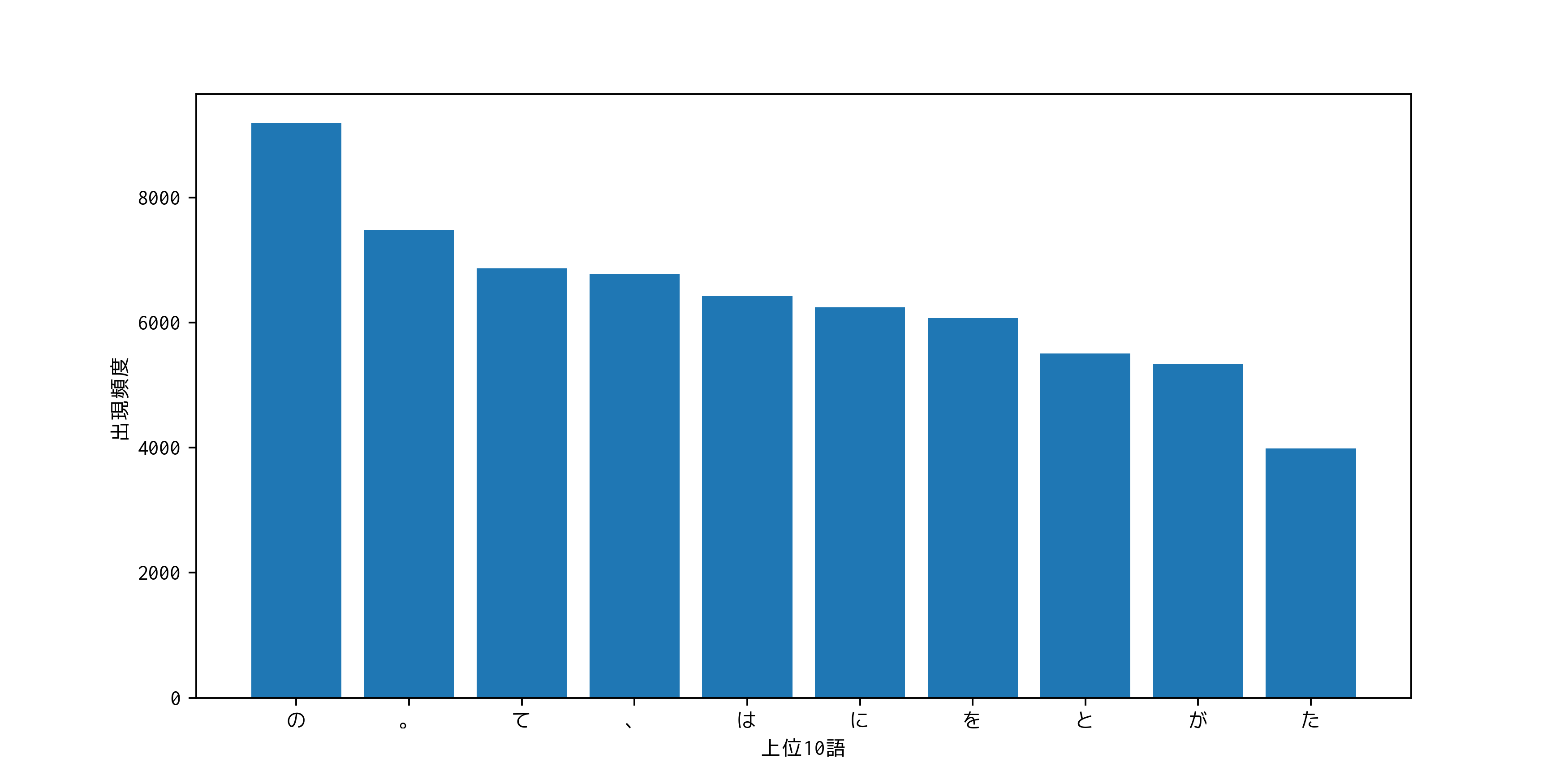
問題37 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
def word_count(morph_text: list, order_type: bool) -> list:
"""
省略
"""
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
word_count_list = word_count(morph_text, True)
top10 = word_count_list[0:10]
plt.figure(figsize=(10,5),dpi=350)
plt.xlabel('上位10語')
plt.ylabel('出現頻度')
plt.bar(range(0, len([el[1] for el in top10])), [el[1] for el in top10], tick_label=[el[0] for el in top10])
plt.savefig('37_result.png')
if __name__ == '__main__':
main()
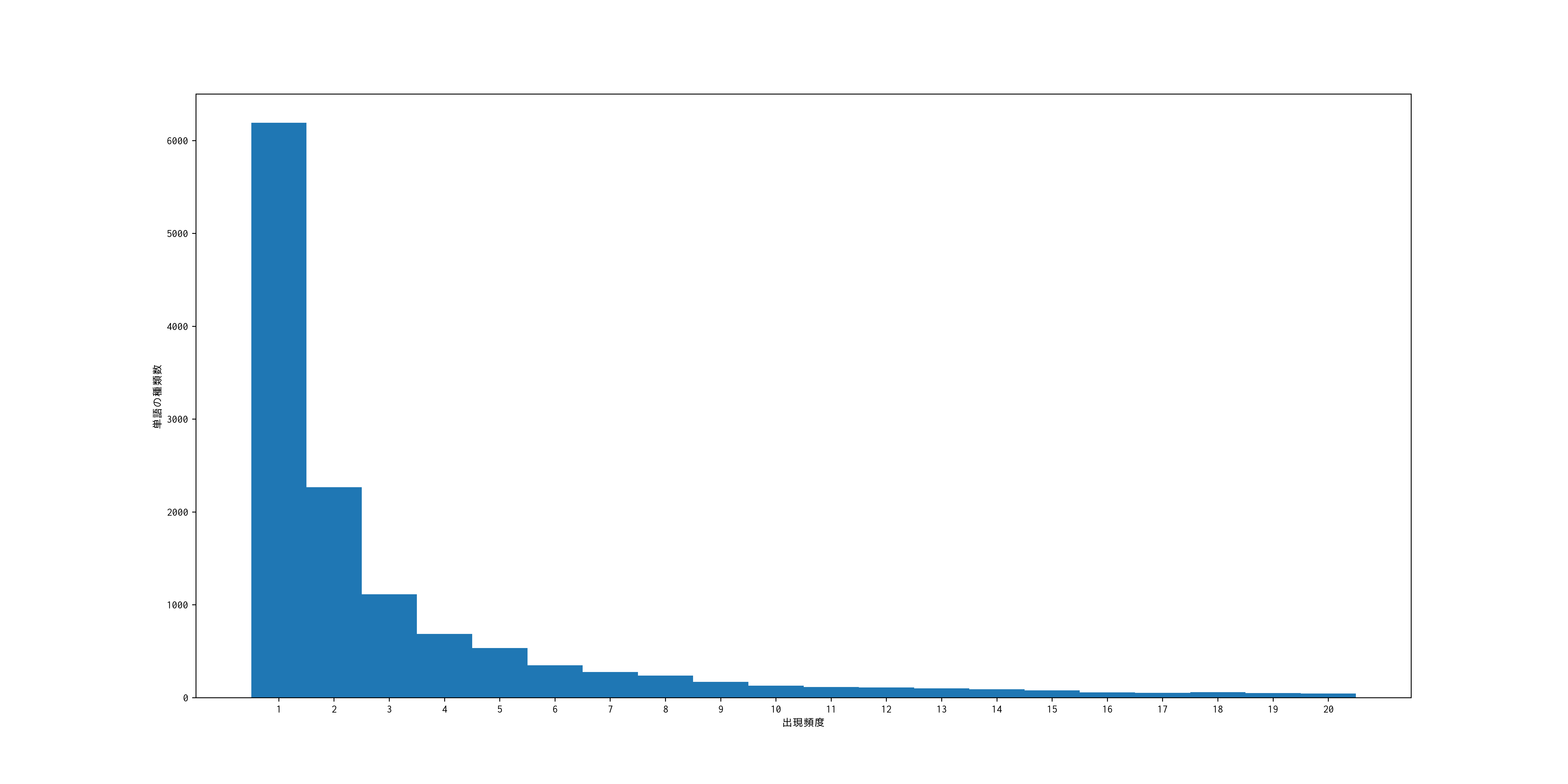
問題38 ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
def word_count(morph_text: list, order_type: bool) -> list:
"""
省略
"""
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
word_count_list = word_count(morph_text, False)
cnt = -1
word_type_count_list = []
for t in word_count_list:
if cnt == t[1]:
word_type_count_list[-1][1] += 1
else:
word_type_count_list.append([t[1], 1])
cnt = t[1]
plt.figure(figsize=(20,10),dpi=350)
plt.xlabel('出現頻度')
plt.ylabel('単語の種類数')
plt.xticks(rotation=0)
plt.bar(range(0, len([el[1] for el in word_type_count_list][:20])), [el[1] for el in word_type_count_list][:20], tick_label=[el[0] for el in word_type_count_list][:20], width=1)
plt.savefig('38_result.png')
if __name__ == '__main__':
main()
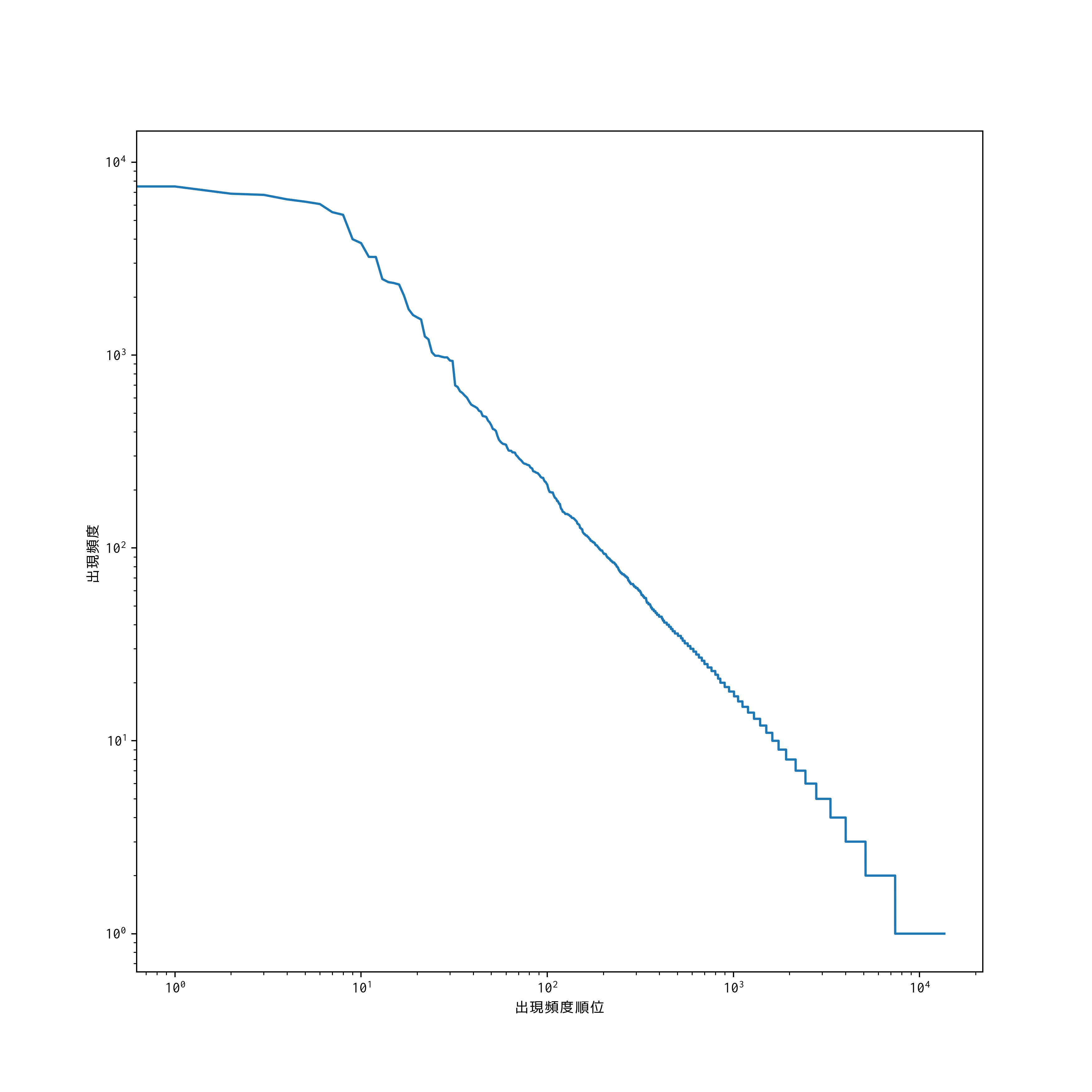
問題39 Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
#!/usr/local/bin python3
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
def word_count(morph_text: list, order_type: bool) -> list:
"""
省略
"""
def load_mecab_data(filename: str) -> list:
"""
省略
"""
def main():
in_filepath = './neko.txt.mecab'
morph_text = load_mecab_data(in_filepath)
word_count_list = word_count(morph_text, True)
frequency = [el[1] for el in word_count_list]
plt.figure(figsize=(10,10),dpi=350)
plt.xscale('log')
plt.yscale('log')
plt.xlabel('出現頻度順位')
plt.ylabel('出現頻度')
plt.plot(range(len(frequency)), frequency)
plt.savefig('39_result.png')
if __name__ == '__main__':
main()