本書の目的
クラウドサーバーでローカル LLM を実行し、生成AIを活用したアプリケーションの内部状態をモニタリングしたときの検証結果です。
- サーバーには Kagoya の VPS を使用しており、スペックは 4 vCPU・メモリ 4GB の汎用的な構成です。LLM を動かすには非力なため、軽量な AI モデルを選定しました
- ローカル LLM のランタイムには「Ollama」を選び、軽量AIモデルには「tinyllama」と「Granite3.2:2b」(IBM製)を使用しています
- オブザーバビリティには「Datadog LLM Observability」を導入し、生成AIを使ったアプリの可観測性を検証しました
一番気になるポイント
ローカルLLMなのできっと、サーバー性能に依存してテキスト生成のパフォーマンスが大幅に遅延します。従って、コンピュートリソースがボトルネックになると思われるので実測してみる。
生成AIチャットアプリ
ユーザーが操作するWEBクライアント画面と、サーバー内部のアーキテクチャ構成を図解します。

アプリ機能
- WEBクライアントは、AIモデルの選択[tinyllama]もしくは[granite]を選べます。プロンプトの入力と生成AIの応答結果を表示する機能のみ
- Ollama呼び出しアプリは、WEBクライアントからのリクエストを/chatエンドポイントで受け取り、LLMプロキシに転送するAPIゲートウェイとして機能します
- LLM プロキシは、ロジックとLLMの中間に位置し、AIモデルに応じてローカルAPIにHTTPリクエストを送信し、指定されたAIモデルとプロンプト応答を取得します
- OllamaとAIモデルは、ローカル環境におけるAIモデル実行基盤として構成されています
なお、Ollama呼び出しアプリとLLMプロキシを分離したのは、ロジックの実装とAIモデルごとの通信を分離することで、コード構成の可読性を高めるためです。
文章要約を実行(tinyllama)
応答時間は約11.6秒でした。ダッシュボードで、どんなモニタリングができるのでしょうか。

APM > Traces
時系列にアプリ実行リクエスト数, エラー数, レイテンシー(13.1秒), HTTPステータス[200]を確認できた。

APM > Traces > Waterfall
関数の遷移とそれぞれにかかる実行時間をみる。Ollama呼び出しから応答までが13.1秒を占めている。

APM > Traces > Waterfall > Infrastructure
13秒間だけだがCPUが80%以上使われ、メモリが1GBから2GBに増加したことが確認できる。

APM > Traces > Waterfall > Processes
Ollama Runner がCPU全体の73%をしめて実行されている。

LLM Observbility > Overview
サマリーは、エラー率, 平均応答時間, トークン(コスト), 時系列で実行数ほかを見ることができる。

LLM Observbility > Traces
生成AIのInputプロンプトとOutputプロンプトが列挙される。

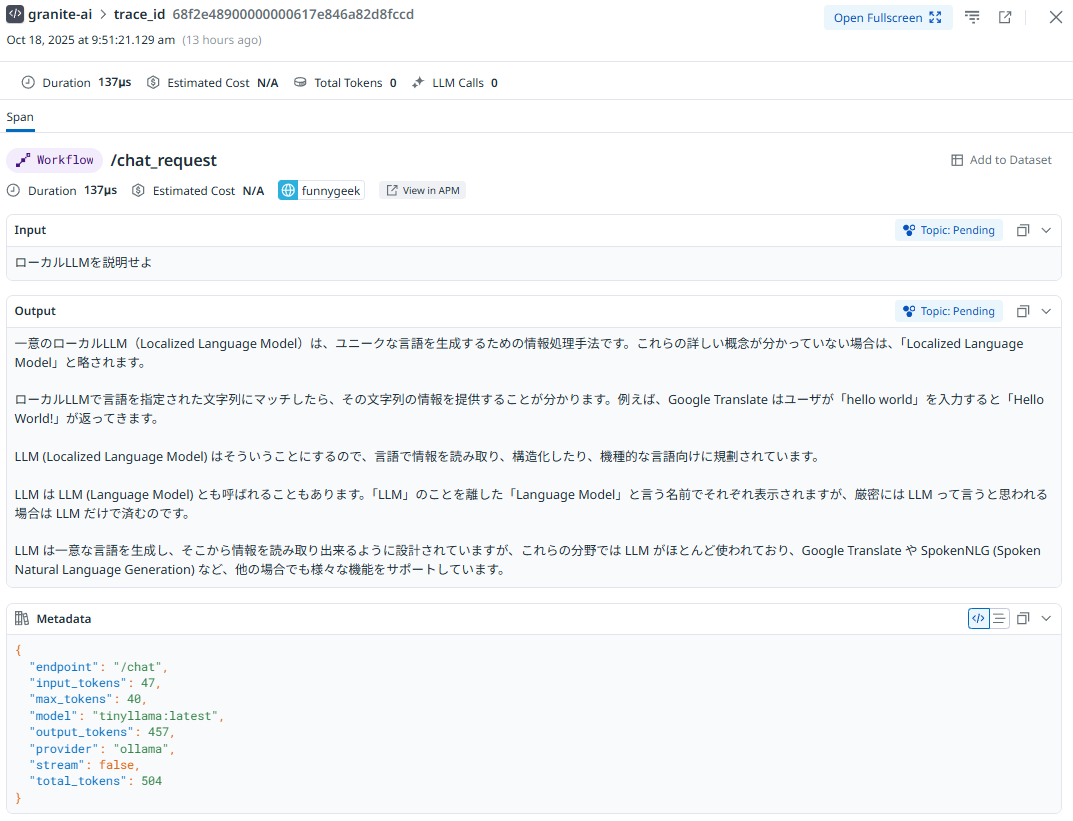
正常なテキスト生成
質問や指示のInputテキストと、生成されたテキストの内容を閲覧できる(できてしまう)
エラー検出
タイムアウト(30秒)のためエラーし、Outputプロンプト取得に失敗している
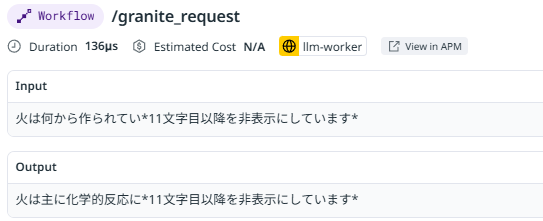
Input/Outputプロンプトをマスクする?
ユーザーが入力した質問や応答をIT管理者が閲覧できてしまう。LLMアプリ開発時のハルシネーション等テキスト生成の品質向上のためには役に立つが、ユーザーが入力した質問には秘密情報も含まれる可能性がある。LLM Observability SDK ではDatadogダッシュボード(Intake Server)に送信する情報を隠すこともできた。11文字目以降を非表示にしています。
Pythonコードの場合は LLMObs.annotate( input_data=mask_text(prompt, 10), の部分で最初の10文字のみ表示し、残りはマスクすることができた。これで本番アプリでも、第三者の情報を制限することができそうだ。
# プロンプトを非表示にする
def mask_text(text, visible):
if not text:
return ""
return text[:visible] + "*11文字目以降を非表示にしています*" if len(text) > visible else text
# Datadog に記録
def log_llmobs(name, prompt, output, metadata, metrics=None, error=None):
with LLMObs.workflow(name=name) as span:
LLMObs.annotate(
input_data=mask_text(prompt, 10),
output_data=mask_text(output, 10),
metadata=metadata,
metrics=metrics or {}
)
文章要約を実行(Granite3.2:2b)
応答時間は1回目約29.6秒, 2回目7.2秒でした。この違いが生じる原因を調査できるか探ります。

APM > Traces > Waterfall > Infrastructure
生成AIアプリを呼び出すと、メモリ利用量が2GBから3GBに増加している。2回目はメモリ使用量3GBのままなので、教科書通りAIモデルをメモリにロードしている時間と判断できそうだ。

再検証
しばらくするとメモリが1GB近くまで解放され、再度、生成AIを呼び出し同じ傾向であることを確認できた。
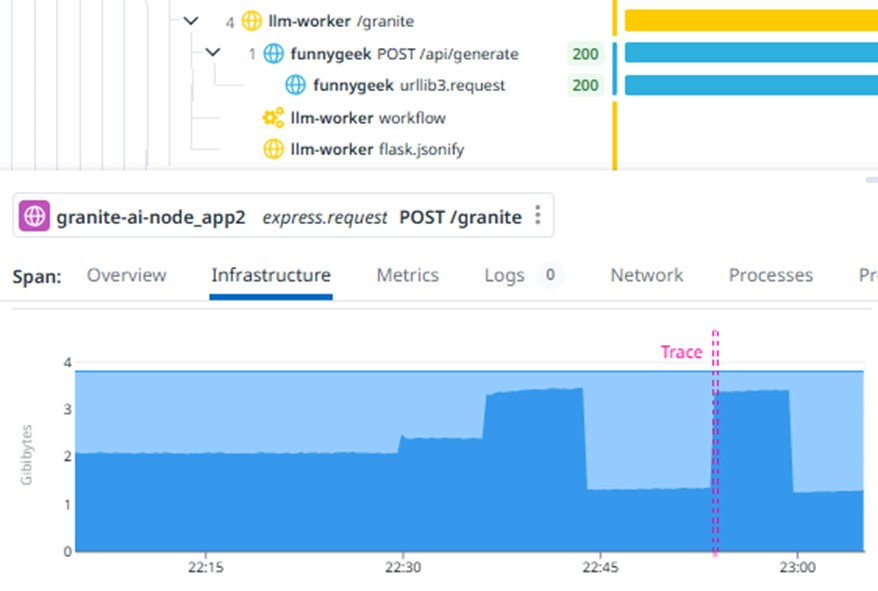
End to End の可視化
情報システムの内部状態を可視化する

Datadog LLM Observability 情報一覧
今回検証できた情報を確認する。
LLM応答の指標
OpenAIなどクラウドサービスのLLMでは自動評価されるが、ローカルLLMでは非対応。ただし、独自ロジックでコーディングは可能。
| 指標 | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| quality | 応答の正確性(×) | ローカルLLMでは非対応 |
| security | 機密情報の漏洩検出(×) | 〃 同上 |
| hallucination | ハルシネーション検出(×) | 〃 同上 |
| toxicity | 有害的表現の検出(×) | 〃 同上 |
| bias | バイアス検出(×) | 〃 同上 |
| failure_to_answer | 未回答の検出(×) | 〃 同上 |
| topic_relevance | 関連性の低い応答(×) | 〃 同上 |
パフォーマンス・運用のためのメトリックス
| メトリクス | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| latency | プロンプト応答時間(〇) | |
| token_usage | トークン数(〇) | |
| error_rate | エラー率(〇) | |
| cost_estimation | モデル利用コスト(〇) |
トレース情報
| 項目名 | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| prompt | プロンプトInput(〇) | |
| response | プロンプトOutput(〇) | |
| model | AIモデル名(〇) | |
| endpoint | 呼び出されたAPI(〇) | |
| request_id | リクエストID | |
| user_session | セッション単位のトレース分析 |
セキュリティ・プライバシー
| 項目名 | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| PII_detection | 個人情報(PII)の検出 | |
| prompt_injection | 悪意あるプロンプト操作の検出 | |
| safety_score | 応答の安全性スコア |
LLM Observability 以外の情報一覧
ローカルLLMアプリは、サーバーの性能パフォーマンスや、ユーザーのリクエスト数などの情報も大切。
顧客体験・WEBクライアント(RUM)
| 項目名 | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| page_load_time | ページ読み込み時間(〇) | |
| user_action_trace | ユーザー操作のトレース(〇) | |
| error_tracking | JSエラーなど(〇) | |
| geo_location | ユーザーのアクセス元(〇) | |
| device/browser_info | デバイスやブラウザ情報(〇) |
バックエンド・アプリケーション(APM)
APIゲートウェイやLLMプロキシを対象とするAPM
| 項目名 | 内容(検証できたか) | 未検証の理由 |
|---|---|---|
| service_latency | アプリの応答時間(〇) | |
| error_rate | エラー率(〇) | |
| trace | APMとLLMのトレース相関(〇) | |
| throughput | 単位時間あたりの処理量 |
コードサンプル
WEBクライアント
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>ローカルLLMチャット</title>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/font-awesome/4.7.0/css/font-awesome.min.css">
<style>
body { font-family: sans-serif; padding: 2em; }
#response { margin-top: 1em; white-space: pre-line; }
textarea {
width: 60%;
height: 100px;
font-size: 16px;
}
button {
margin-top: 0.5em;
padding: 0.5em 1em;
font-size: 16px;
}
#loader {
margin-top: 1em;
display: none;
}
select {
margin-top: 1em;
font-size: 16px;
}
</style>
</head>
<body>
<h1>ローカルLLMチャット</h1>
<p>Datadog LLM Observability, 4vCPUサーバー、メモリ4GBなので遅いです</p>
<label for="modelSelect">使用するモデル:</label>
<select id="modelSelect">
<option value="/chat">tinyllama(POST)/chat</option>
<option value="/granite">granite3.2:2b /granite</option>
</select><br><br>
<textarea id="messageInput" placeholder="質問を入力 (Shift+Enterで改行)"></textarea><br>
<button onclick="sendMessage()">AIに聞く</button>
<div id="loader"><i class="fa fa-cog fa-spin fa-3x fa-fw"></i></div>
<div id="response"></div>
<div id="meta" style="margin-top: 1em; font-size: 0.9em; color: #555;"></div>
<script>
const messageInput = document.getElementById('messageInput');
const modelSelect = document.getElementById('modelSelect');
const responseDiv = document.getElementById('response');
const loader = document.getElementById('loader');
const metaDiv = document.getElementById('meta');
messageInput.addEventListener('keydown', function (e) {
if (e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
sendMessage();
}
});
async function sendMessage() {
const message = messageInput.value.trim();
const endpoint = modelSelect.value;
if (!message) {
responseDiv.textContent = 'メッセージを入力してください。';
return;
}
responseDiv.textContent = '';
metaDiv.textContent = '';
loader.style.display = 'block';
const startTime = Date.now();
const url = `https://ドメイン名${endpoint}`;
try {
const res = await fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
const data = await res.json();
responseDiv.textContent = data.reply || '返答がありませんでした。';
metaDiv.textContent = `応答時間: ${Date.now() - startTime}ms`;
} catch (err) {
responseDiv.textContent = 'エラーが発生しました。';
console.error(err);
} finally {
loader.style.display = 'none';
}
}
</script>
</body>
</html>
APIゲートウェイ
const tracer = require('dd-trace').init({
tags: {
host: 'ome',
env: 'prod',
service: 'granite-ai-node_app2',
version: '0.0.3',
application: 'granite-ai'
}
});
const express = require('express');
const axios = require('axios');
const app = express();
const port = 3000;
app.use(express.json());
// [/chat] → Python proxy(非ストリーミング)
app.post('/chat', async (req, res) => {
const userMessage = req.body.message || '';
if (!userMessage) {
return res.status(400).json({ error: 'No message provided' });
}
try {
const response = await axios.post('http://localhost:5002/chat', {
message: userMessage
}, {
headers: {
'Content-Type': 'application/json'
}
});
res.json(response.data);
} catch (error) {
console.error('Python proxy error (/chat):', error.response?.data || error.message);
res.status(500).json({
error: 'Error communicating with Python proxy',
detail: error.response?.data || error.message
});
}
});
// サーバー起動
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});
LLM プロキシ
from flask import Flask, request, Response, jsonify
from ddtrace.llmobs import LLMObs
from ddtrace import patch_all, patch
import requests
import json
import os
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
# Datadog 初期化
LLMObs.enable(
ml_app="granite-ai",
service="llm-worker"
)
patch_all()
patch(flask=True)
app = Flask(__name__)
# モデル設定辞書(ルートとモデルの紐付け)
MODEL_CONFIG = {
"/chat": {
"model": "tinyllama:latest",
"max_tokens": 40,
"stream": False
},
"/granite": {
"model": "granite3.2:2b",
"max_tokens": 40,
"stream": False
}
}
# メタデータ生成
def build_metadata(model, stream, endpoint, max_tokens):
return {
"model": model,
"stream": stream,
"provider": "ollama",
"endpoint": endpoint,
"max_tokens": max_tokens
}
# Datadog LLM Observability メトリクス生成
def build_metrics(result):
input_tokens = result.get("prompt_eval_count", 0)
output_tokens = result.get("eval_count", 0)
return {
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens,
"quality": 0, # 0: 問題なし, 1: 品質低下(例:意味不明、誤答など)
"security": 0 # 0: 安全, 1: 機密漏洩や不適切な内容の可能性あり
}
# プロンプトを非表示にする
def mask_text(text, visible):
if not text:
return ""
return text[:visible] + "*11文字目以降を非表示にしています*" if len(text) > visible else text
# Datadog に記録
def log_llmobs(name, prompt, output, metadata, metrics=None, error=None):
with LLMObs.workflow(name=name) as span:
if error:
span.set_tag("error", True)
metadata["error"] = error
output = f"[ERROR] {error}"
LLMObs.annotate(
input_data=mask_text(prompt, 10),
output_data=mask_text(output, 10),
metadata=metadata,
metrics=metrics or {}
)
# Ollama API 呼び出し
def call_ollama_api(model, prompt, max_tokens=128, stream=False):
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": model,
"prompt": prompt,
"max_tokens": max_tokens,
"stream": stream
},
stream=stream
)
if response.status_code != 200:
raise Exception(handle_response_error(response))
return response
# エラー整形
def handle_response_error(response):
try:
error_info = response.json().get("error", "")
return error_info or response.text
except Exception:
return response.text
# 共通エンドポイント処理(非ストリーミング)
def handle_non_streaming(endpoint, prompt, config):
model = config["model"]
max_tokens = config["max_tokens"]
stream = config["stream"]
metadata = build_metadata(model, stream, endpoint, max_tokens)
try:
response = call_ollama_api(model, prompt, max_tokens, stream)
result = response.json()
output = result.get("response", "") or "[WARN] Model returned empty response."
metrics = build_metrics(result)
metadata.update(metrics)
log_llmobs(f"{endpoint}_request", prompt, output, metadata, metrics)
return jsonify({
"reply": output,
"eval_count": metrics["output_tokens"],
"prompt_eval_count": metrics["input_tokens"],
"duration_ms": result.get("eval_duration", 0)
})
except Exception as e:
log_llmobs(f"{endpoint}_error", prompt, "", metadata, error=str(e))
return jsonify({ "error": str(e), "prompt": prompt, "output": "" }), 500
# POSTリクエストからプロンプトを安全に抽出
def extract_prompt():
data = request.get_json(silent=True) or {}
return data.get("message") or data.get("prompt") or "質問はなんですか?"
# ルーティング定義(すべてPOSTに統一)
for route, config in MODEL_CONFIG.items():
app.add_url_rule(
route,
route,
lambda route=route, config=config: handle_non_streaming(route, extract_prompt(), config),
methods=["POST"]
)
# アプリ起動
if __name__ == '__main__':
app.run(port=5002)
まとめ:DatadogによるローカルLLMアプリの可観測性を検証
本検証では、Kagoya VPS 上に構築した軽量なローカル LLM 実行環境(Ollama + tinyllama / Granite3.2:2b)を用いて、生成AIアプリのパフォーマンスと可観測性を Datadog で可視化して、以下の知見が得られました:
- 初回リクエストはモデルロードの影響で遅延(最大29秒)、2回目以降は高速化(7秒前後)
- CPU使用率は最大80%以上、メモリは最大3GBまで増加
- Datadog APM ではレイテンシ、エラー率、プロセス負荷を可視化
- LLM Observability ではプロンプトの入出力、トークン数、応答時間、コストを確認可能
- PIIマスキングやプロンプトの匿名化もコードで制御可能
一方で、Datadog の「Managed Evaluations(品質・セキュリティ評価)」はクラウドLLM向けであり、ローカルLLMでは非対応でした。ただし、アプリ側で評価ロジックを実装すれば、カスタムメトリクスとして送信可能です。
今回の検証を通じて、ローカルLLMでも十分に可観測性を確保できること、そしてDatadog を活用すれば生成AIアプリの内部挙動をエンドツーエンドで把握できることが確認できました。