「Pythonによる AI・機械学習・深層学習アプリのつくり方」を読みました。
本の後半である第4章と第6章で作り方が解説されているアプリを紹介します。
ここに載せるのはあくまで一部で、主に自分の興味があったものだけです。
ちなみに第1章、第2章は機械学習入門の話、第3章はOpenCVを用いた画像、動画の処理の内容、第5章はTensorflowとKerasの説明と画像認識の話でした。
第4章 自然言語処理
主なキーワード
- 形態素解析
- MeCab
- mecab-ipadic-NEologd
- Word2Vec
- Doc2Vec
- マルコフ連鎖
MeCabによる形態素解析
形態素解析は文章を単語に分割する技術であり、自然言語処理に欠かせない技術です。
形態素解析の定番ツールが「MeCab」です。
「メイが恋ダンスを踊っている」という文章を形態素解析した例が以下です。
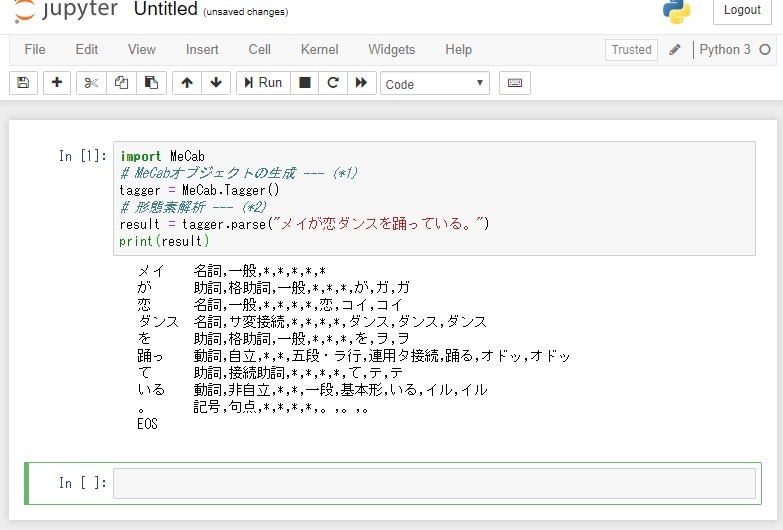
MeCabの単語辞書の一つに「mecab-ipadic-NEologd」があり、これを使えば新しい単語に対応した解析が行えます。
例えば上の例の「恋ダンス」という単語をちゃんと一つの固有名詞として認識できるようになります。
単語の意味のベクトル化
形態素解析によって文章を各単語に分割した後は各単語をベクトル化します。
ベクトル化によって単語の意味や類似度の計算が可能になります。
(例)「王」-「男」+「女」=「女王」
本書ではWikipediaの全文章をダウンロードして元データとし、「Word2Vec」にて単語のベクトル化を行います。
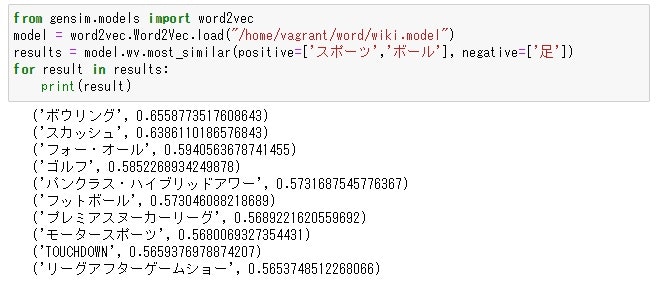
私は以下の計算から足を使わない球技を調べてみました。
「スポーツ」+「ボール」-「足」=?
マルコフ連鎖による自動作文
マルコフ連鎖とは、未来の状態が現在の状態のみで決まるという性質を持つ確率過程のことです。
これを利用することで既存の文章を利用し、自動で文章を生成することができます。
以下では犬や熊について少し語ってみました。

この手法では入力された単語の品詞に注目し、その単語を始点に応答文を作成します。
上のように文章の意図を認識せず、オウム返しのような返答が多いです。
会話を続けると多少は上手く会話できるようになりますが、自然な会話をするにはアルゴリズムの見直しが必要でしょう。
第6章 機械学習で業務を効率化しよう
主なキーワード
- TF-IDF
- Webサーバー
- Web API
- Flask
- Flickr API
- 画像の水増し
ニュース記事の自動ジャンル分け
大量のニュース記事とそれがどのジャンルなのかの情報を教師データとして与え、機械学習を利用して未知の文章のジャンル判定を行います。
文章を判定するために、「TF-IDF」というツールを用いて文章をベクトルデータに変換します。
使用するデータは「livedoorコーパス」で、ジャンル(提供媒体)ごとに分類されたニュース記事が用意されています。
このデータを用いることで、入力した文章を「スポーツ」「IT」「映画」「ライフ」の4カテゴリのいづれかに分類します。
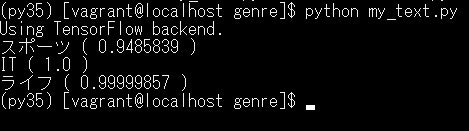
以下の3つの文章をジャンル分けしてみます。

このように90%以上の高精度で分類できています。
次にどのジャンルになるか判断に迷うような文章でトライしてみます。

一つ目の文章は「日経xTECH」から取ってきたIT系の記事で二つ目の文章は「セキララ ゼクシィ」から取ってきたライフ系の記事です。
結果は以下のようになりました。
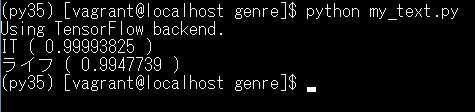
99%の精度で正確にジャンル分けしており、なかなか優秀です。
Webで使える文章ジャンル判定アプリ
上の「ニュース自動ジャンル分けツール」をWeb上で実装します。
Webサーバーの作成にフレームワークのFlaskを利用します。
以下のようにHTMLでWebページを作成します。
テキストボックスにジャンル判定したい文章を書いてボタンを押すと、APIサーバーに送信して結果を表示します。
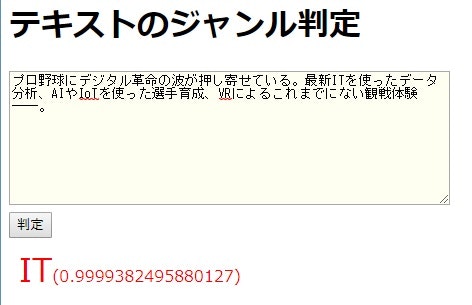
料理の写真からカロリーを調べるツール
画像分析を利用し、料理の写真からカロリーを計算するプログラムです。
ただし、判定する料理は寿司、サラダ、麻婆豆腐の3種類のみです。
写真共有サイトのFlickrから料理写真をダウンロードします。
Flickr APIを使用するにはFlickr APIのページにアクセスし、「Key」と「Secret」という2つの文字列を取得します。
「マグロ寿司」、「サラダ」、「麻婆豆腐」のキーワードで検索した画像を300枚ずつダウンロードします。
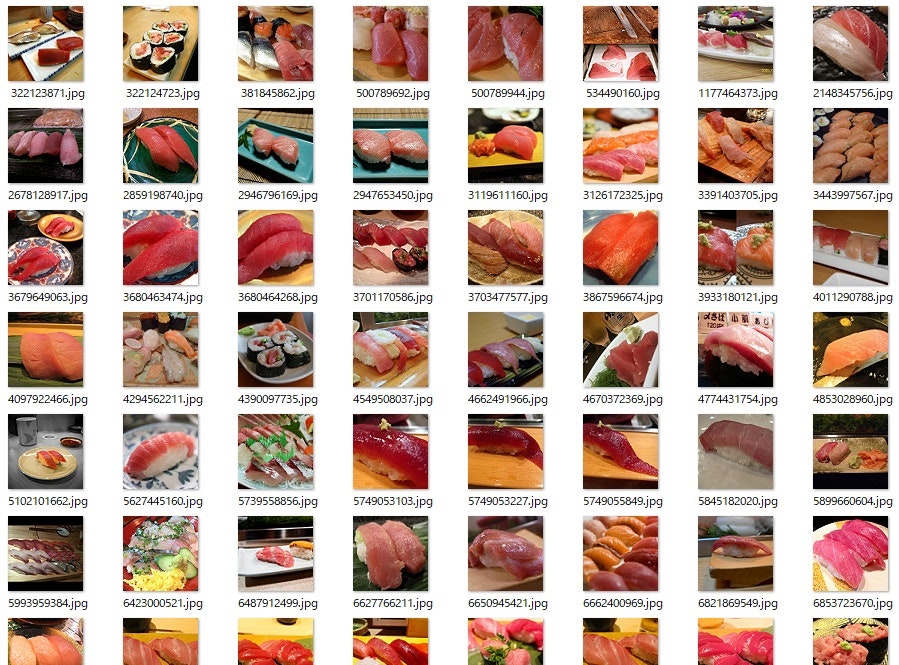
以下は「マグロ寿司」で検索してダウンロードした画像の一部です。
全体的に赤っぽいですが、一部マグロと関係の無い画像が混じっています。

関係の無い画像や質の悪い画像は手作業で削除し、300枚から100枚に減らします。
この画像データのスクリーニングの作業が画像判定の精度に大きく影響します。
そして以下のようにマグロの画像だけ抽出しました。サラダや麻婆豆腐も同様に抽出します。
CNNで画像データの学習を行い、画像判定を行った結果が以下です。

正解率36.6%と、あまり上手くいっていません。
次に精度向上のためにデータの水増しを行います。
写真の回転・反転を行うのですが、人間の目には同じでもコンピュータにはまったく異なる画像として認識されます。
データを240枚から5760枚に水増しをしてからCNNで学習させた結果が以下です。

正解率38.3%となり、データ水増し前とあまり変わりませんでした。
ちなみに本書内ではデータ水増し前で77%、水増し後で85%となっています。
正解率が低い大きな原因は画像データにあり、データセットの改善が必要と書かれていました。
画像データのスクリーニングで手抜きしたつもりはないのですが、なかなか難しいですね。
まとめ
良かったところ
- 機械学習や深層学習を実際のアプリにどのように組み込めばよいか分かった
- 色々作れて面白かった
悪かったところ
- 実際にデプロイしてWebアプリとして完成させるまでの説明が無い
- GitHubで公開されているサンプルプログラムにミスが多く、そのままでは動かないことが多い
私自身は初心者なので環境構築やエラーに悩むことが多かったですが、やはり実際にモノが作れると面白いです。
もっと詳しい説明やエラーの対処については以下にまとめています。