目的
LSTMに、サイン波を複数のGPUを使って学習させる。
※コードはgithubにありますが、間違えもあるはずです。なにかあれば教えてくれるとすごくありがたいです。
LSTMについて
LSTMとは時系列のデータを扱うRNN(再起的ニューラルネットワーク)の一種で、普通のRNNだと起こる勾配が爆発・消失する問題がないので、よく使われています。

Many2Many LSTM
ここで作るのは以下の図の5番目のLSTMです。
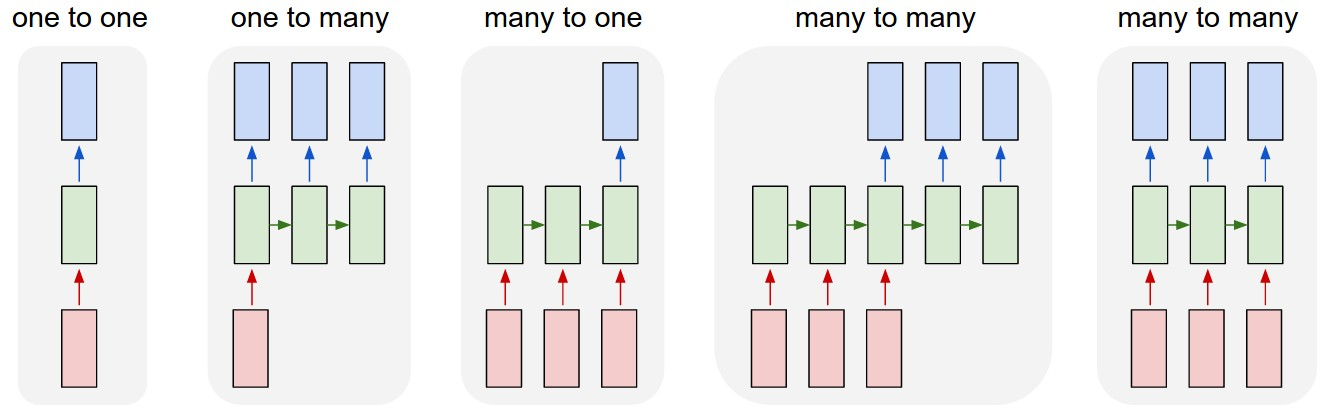
Model
n_unitsは下記の図のxたちの次元を示します。
大きければ、大きいほど学習するパラメータの数が増えます。
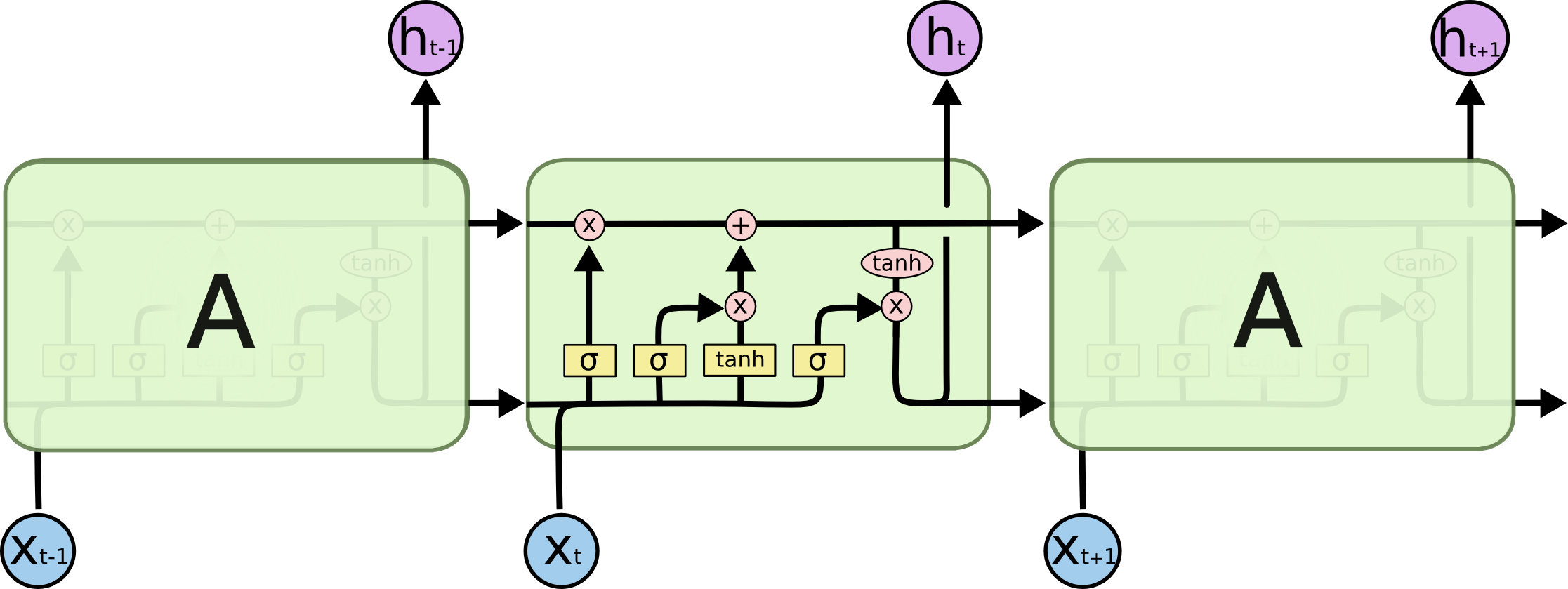
each line carries an entire vector, from the output of one node to the inputs of others.
本記事で使ったコードはここのものを参考にしました
→https://qiita.com/chachay/items/052406176c55dd5b9a6a
ただいろいろ修正・改変しているところがあるので注意してください。
class LSTM(Chain):
n_input = 1
n_output = 1
n_units = 5 #大きければ、大きいほど学習するパラメータの数が増える。
def __init__(self):
super(LSTM, self).__init__(
l1 = L.Linear(self.n_input, self.n_units),
l2 = L.LSTM(self.n_units, self.n_units),
l3 = L.Linear(self.n_units, self.n_output),
)
def reset_state(self):
self.l2.reset_state()
def __call__(self, x):
h1 = self.l1(x)
h2 = self.l2(h1)
return self.l3(h2)
データ
import numpy as np
import matplotlib.pyplot as plt
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import report, training, Chain, cuda, datasets, iterators, optimizers, Variable, function
from chainer.training import extensions
from chainer.datasets import tuple_dataset
import cupy
import six
# データ作成
N_data = 1000
N_Loop = 3
t = np.linspace(0., 2*np.pi*N_Loop, num=N_data)
X = 0.8*np.sin(2.0*t)
# データセット
N_train = int(N_data*0.8)
N_test = int(N_data*0.2)
tmp_DataSet_X= np.array(X).astype(np.float32)
x_train, x_test = np.array(tmp_DataSet_X[:N_train]),np.array(tmp_DataSet_X[N_train:])
train = tuple_dataset.TupleDataset(x_train)
test = tuple_dataset.TupleDataset(x_test)
plt.scatter(range(0,len(x_train)), x_train,c="red")
plt.scatter(range(0,len(x_test)), x_test, c="blue")
plt.show()
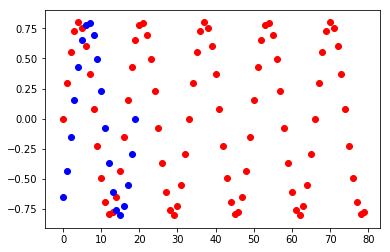
学習の流れ
Chainer trainer for LSTM
https://docs.chainer.org/en/stable/guides/trainer.html より
ニューラルネットワークを学習させたいときは、パラメータを何度も更新するトレーニングループを実行する必要があります。
典型的なトレーニングループは以下の手順で構成されています。
- 訓練データセットの反復
- 抽出ミニバッチの前処理
- ニューラルネットワークのforward/backward計算
- パラメータの更新
- 検証データセットで現パラメータの評価
- ログ記録と表示
GPUを複数有効活用したいときは、2〜4の工程を並列に行うことになるのでここを自分で書く必要があります。
参考にした記事はCPUで学習させていたので、GPUでも走るようにちょっとコードを変えました。
複数のGPUで走るらせるには、LSTM_std_updaterとLSTM_prl_updaterにupdaterを分ける必要がありました。
これはChainerでそもそもStandardUpdaterとParallelUpdaterを分けているためしょうがないかと思います。
残りのコードはgithubから取ってください。
class LSTM_std_updater(training.StandardUpdater):
def __init__(self, train_iter, optimizer, device):
super().__init__(train_iter, optimizer, device=device)
self.seq_length = train_iter.seq_length
def update_core(self):
loss = 0
train_iter = self.get_iterator('main')
optimizer = self.get_optimizer('main')
for i in range(self.seq_length):
batch = train_iter.__next__()
x, t = self.converter(batch, self.device)
loss += optimizer.target(chainer.Variable(x.reshape((-1, 1))), chainer.Variable(t.reshape((-1, 1))))
optimizer.target.zerograds()
loss.backward()
loss.unchain_backward()
optimizer.update()
class LSTM_prl_updater(training.ParallelUpdater):
def __init__(self, train_iter, optimizer, devices):
super().__init__(train_iter, optimizer, devices=devices)
self.seq_length = train_iter.seq_length
def update_core(self):
losses = [0 for i in self._models]
train_iter = self.get_iterator('main')
optimizer = self.get_optimizer('main')
for i in range(self.seq_length):
batch = train_iter.__next__()
#ここから並列計算用の処理
n = len(self._models)
xt_list = {}
for i, key in enumerate(six.iterkeys(self._models)):
xt_list[key] = self.converter(
batch[i::n], self._devices[key])
for model in six.itervalues(self._models):
model.cleargrads()
_losses = []
for model_key, model in six.iteritems(self._models):
x, t = xt_list[model_key]
loss_func = self.loss_func or model
with function.force_backprop_mode():
dev_id = self._devices[model_key]
dev_id = dev_id if 0 <= dev_id else None
with cuda.get_device_from_id(dev_id):
_loss = loss_func(x, t)
_losses.append(_loss)
losses = [sum(x) for x in zip(losses, _losses)]
optimizer.target.zerograds()
for loss in losses:
loss.backward()
loss.unchain_backward()
optimizer.update()
結果
上記のデータで学習させた結果です。
初期データ(N_data*0.1個)を用いてt+1を予測
予測したt+1を用いてt+2を予測
予測を用いて予測するの繰り返し
model_cpu = run_LSTM(gpu0=-1, batchsize=10, seqlen=10, epoch=10000)
plot_test(model_cpu)
model_1gpu = run_LSTM(gpu0=0,batchsize=10,seqlen=10, epoch=10000)
plot_test(model_1gpu)
model_2gpu = run_LSTM(gpu0=0,gpu1=1,batchsize=10,seqlen=10, epoch=10000)
plot_test(model_2gpu)
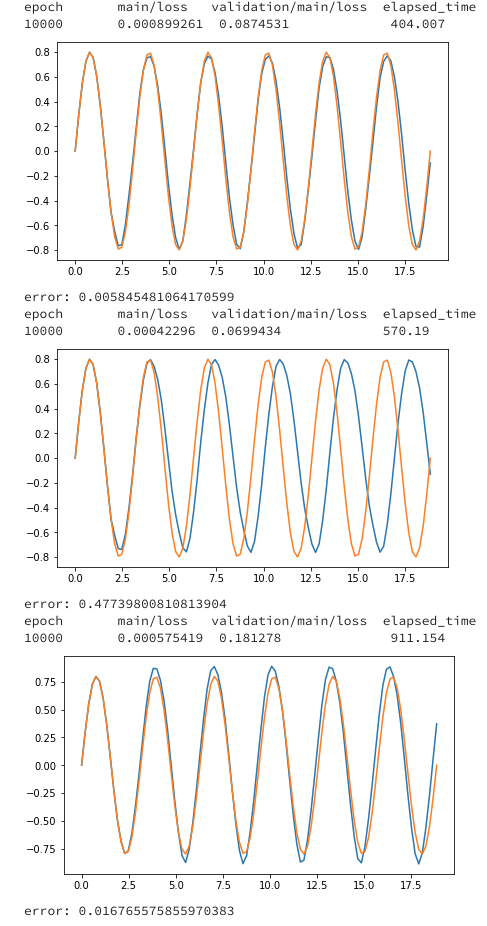
GPUのほうが遅いのは、ハイパーパラメータの設定で、batchsizeやLSTMのn_unitsが小さくなっているため、GPUを活かせてないことが原因にあるかと思います。