今回はSVDの話です。次元が増えすぎると機械学習がうまくいきませんっていう話でしたよね(次元の呪い)。そこで、SVDで次元圧縮しましょう!ってことです。
前回分はこちら↓↓
http://qiita.com/ru_pe129/items/e42183569ef52681a350
主成分分析の解説があまりにも雑だったので、すこし付け加えました。
…SVMと勘違いしてました。少なくとも授業ではやってません。
今までは全訳っぽくなっていたので、少しテイストを変えてゆるい感じで書きます。
2.2.3.2 Singular Value Decomposition
SVD(Singular Value Decomposition) はMatrix Facorizationの手法を実現したものであり、PCA(主成分分析)にも関係がある。SVDのキーポイントは、「concepts」や各「concept」の強さを表現できるような低次元の特徴空間が計算可能かどうか判断すること(????)。SVDは低次元空間で意味的conceptを抽出しやすいため、LSI(Latent Semantic analysis 潜在的意味解析)の基礎として使われている。(LSIは自然言語処理で使われている技法) ここでいうconceptというのは、複数のアイテムが持っている特徴をまとめて表現しているもののことを指すのだろう。
では、アルゴリズムの説明に移る。
ある与えられた行列Aについて、常にAは以下の形で分解することができる。
A = U\lambdaV^{T}
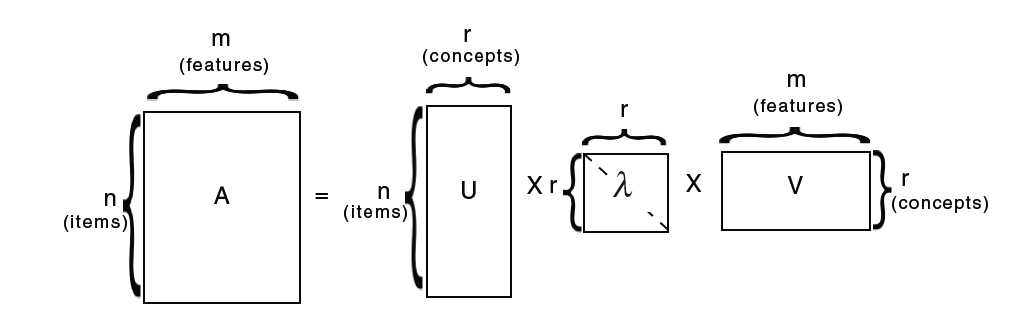
Aはn×m行列(n個のアイテムにm個の特徴)、Uはn×r行列(n個のアイテムにr個のconcept)、λはn×nの対角行列(各成分は各conceptの強さ)、Vはm×r行列(r個のconceptにm個の特徴)を表している。
λの対角成分は常に正の値をとり、成分が降順に並んでいる。また、Uはitem-to-conceptの類似度を表す行列、Vはterm-to-conceptを示す行列であると解釈する。n≠mの場合、つまりAが正方行列でない場合、
T=AA^{T} と D=A^{T}A
を考える。Uの列はTの固有ベクトル、Vの列はDの固有ベクトルであるとし、λの各成分は両者に共通する0以外の固有値の平方根となる。つまり、まずTとDを求めTとDの固有値と固有ベクトルを求めるのである。
λに含まれる固有値は降順になっているため、上位k個の固有値(k個の大きい固有値)を得るだけで、もとの行列Aを推測することが出来る。つまり、上位k個の切り取られたAは以下のように表すことが出来る。
A _{k}= U_{k}\lambda_{k}V_{k}^{T}
A_kはランクがkであり、Aにもっとも近い行列であると言える。ここで、近いというのはAとA_kの成分の二乗誤差の和が最小になるという意味である。(成分の数が違うのにどうやって二乗誤差を求めるのだろうか…)こうして得られたSVDはk次元空間において意味構造を示すものであり、元の次元数のときよりもノイズを減らしたものであると言える。
SVDの利点は、新しいデータを加えた時に計算済みの要素について再計算しなくてよい点である。このアイデアがonline におけるSVDに拡張され、Netflix Prizeで成功を収めたことで現在は一般的に受け入れられている。Simon Funkという人がブログで公開したSVDに関する手法がNetflix Prizeでは転換点となり、SVDのアルゴリズムの改善も進んだ。(気になる方はNetflix PrizeやSimon Funkでググってください!)
SVDに似た手法として、 Matrix Factorization(MF) や Non-Negative Matrix Factorization(NNMF) などがある。元の行列をユーザーの特徴を記述する行列とアイテムの特徴を記述する行列の二つの行列に分解することで次元削減を行うというのがMFとNNMFの基本的な考えである。MFは欠損値の扱いがSVDより優れているが、SVDで0の値を持つ要素をアイテムの平均スコアで入れ替えることによって欠損値の扱いについては改善できる。SVDやMFの抱える問題点は、計算が複雑であるがゆえにデータを更新した際に再計算が非常に大変であるという点だ。この問題点を解決するためにRegularized Karnel Matrix Factorizationと呼ばれる手法が提案されている。、MFやSVDについてはChapter5でNetflix Prizeに関連する話として詳しく述べられている。
2.2.4 Denoising
欠損値や外れ値といったノイズの低減はデータマイニングにおいては非常に大切な処理である。本章では一般的な意味として、ノイズを「データマイニング、分析、解釈に悪影響を及ぼす好ましくない人工的なノイズ」として定義する。RSにおいては自然発生するノイズと悪意のあるノイズの二つに分けられる。前者はユーザーの自然な行動によって生まれたノイズを指し、後者は推薦結果に偏りを与えるために意図的に加えられたノイズを指す。意図的なノイズが推薦システムに対して悪影響を及ぼすのは明らかだが、自然発生したノイズについても無視できないと研究によって結論付けられている。自然発生したノイズについては、複雑な計算によって解決するよりもデータの前処理を用いる方が正しい修正が可能であるということも結論付けられている。
今回は短くなりましたが、きりが良いのでこれで終わりです。
次回は分類器の話です。年内に3章まで終わるといいのですが…