はじめましてなので
某中堅企業でエンジニアやってます。ふと、自習したことをQiitaに纏めていこうと思い立ちました。
とりあえず勉強中の機械学習について纏めてみます。(心折れたら書きやすい別テーマで休憩)
ちなみに言語は主にPythonを使う予定です。
※9/25追記 次:「データ前処理編」
ご注意!
- 理論よりも、とりあえず触って理解するやり方が好きなので、色々と雑です。
- さらに文盲ということで、分かりづらい文章になると思ってます。
- そんな訳で読んでてツッコミたくなる内容は多々あると思いますが、ご了承頂きたく!
※優しいツッコミは大歓迎です
3行でまとめ
- Twitterのデータを使って機械学習をお勉強してみます。
- 今回は使うデータ・環境準備の話で終わり。
- 次回はツイートのクラスタリング・類似度の算出をするつもり。
データセット
勉強開始当初、参考書やチュートリアルで出てくる「iris(アヤメ)」や「Titanic(タイタニック号の生存/死亡者)」をそのまま使って色々してみたんですが、データへの興味の無さからか全然頭に入って来ず…。
心機一転、分析して面白そうなTwitterのデータを使うことにしました。
また、より自分の興味をそそるように(?)、今回は「Perfume」に関するツイートに絞ることにしてます。
(注:のっち派です)
ちなみに「Perfume」が含まれるツイートを取得して眺めて見たところ、思ってたより件数が少なく(250件/1h位)、ボットらしきツイートを除外するとさらに少ないことが分かりました。
ツイート非公開のファンが多いからかなぁと勝手に思ってます。
(非公開のツイートも、ユーザ名無しで公開してくれないかな…ムリか…)
ということでデータ数が若干少ないので、今後は比較のためにもアーティストを増やしていこうかと思います。
(候補:CAPSULE、サカナクション・・・)
機械学習で具体的に何をするかは…動かしながら考え中です。
データの準備方法
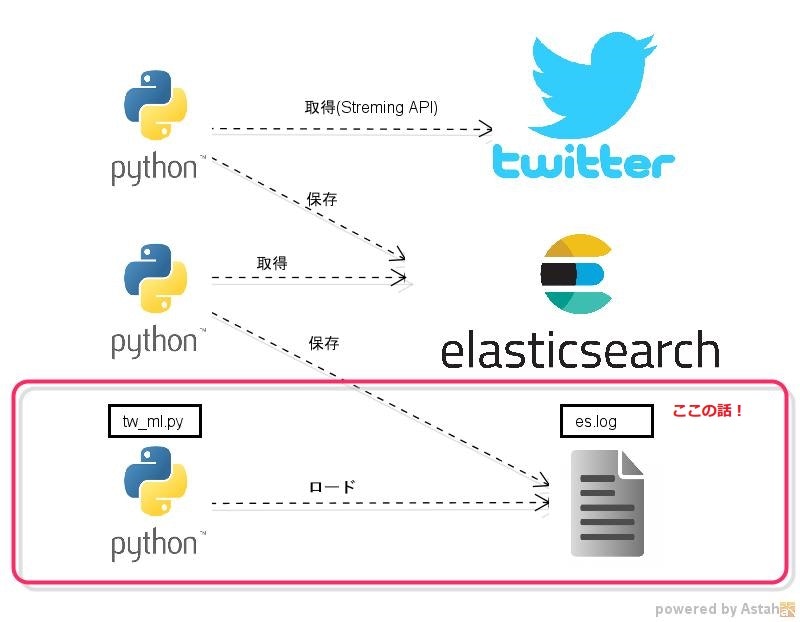
StremingAPIを使ってPerfumeに関するツイートを収集、Elasticsearchで蓄積する環境を構築済みです。
今回は勉強スピードアップの為、Elasticsearchから一部のデータをファイルに保存(es.log)し、ローカルのスクリプト(tw_ml.py)で機械学習他、ゴニョゴニョしてみようと思います。
以下のような感じ。
データのフォーマットは以下のようになっています。
(保存時、辞書型なのでユニコードオブジェクトには「u」とか付いてます)
[{u'_score': 1.0, u'_type': u'raw', u'_id': u'AVZkL6ZevipIIzTJxrL7', u'_source': {u'retweeted_status': u'True', u'text': u'Perfume\u306e\u597d\u304d\u306a\u6b4c', u'user': u'xxxxxxxxxx', u'date': u'2016-08-07T08:45:27', u'retweet_count': u'0', u'geo': u'None', u'favorite_count': u'0'}, u'_index': u'tweet'}]
Pythonからes.logの読み込みはcodecsでopenして、astを使って辞書に戻して使います。
とりあえず265件ですが、データ量が足りないと思ったらElasticsearchから再度取得して増やすつもり。
import codecs
import ast
with codecs.open("es.log", "r", "utf-8") as f:
es_dict = ast.literal_eval(f.read())
print "doc:%d" % len(es_dict) # doc:265
環境、主なライブラリ等
-
スクリプト実行環境
-
Windows7 64bit
-
Python2.7
-
主なPythonライブラリ
-
numpy 1.11.1
-
scipy 0.12.0
-
scikit-learn 0.16.0
-
mecab-python 0.996
ちなみにMecabは日本語の形態素解析に使うのですが、辞書には「mecab-ipadic-neologd」を使ってます。
コレ使わないと「かしゆか」「あーちゃん」「のっち」すら単語とみなしてくれなかった…笑
※ただ、mecab-ipadic-neologd使っても「のっち」はカタカナで「ノッチ」!デンジャラス!!
MECAB_OPT = "-Ochasen -d C:\\tmp\\mecab-ipadic-neologd\\"
t = mc.Tagger(MECAB_OPT)
では早速…
と思いましたが、長くなったので本題の機械学習については次回以降にします!笑
とりあえずツイートのクラスタリング・類似度の算出を試してみる予定です。