iOSDC2017に以下のタイトルで登壇しました。
iOSと人工知能(AI) -GPU並列演算の仕組みと機械学習-
スライドはこちらです。
(Speaker Deck) iOSと人工知能(AI) -GPU並列演算の仕組みと機械学習-
発表の動画はこちらです。
(YouTube) iOSDC Japan 2017 09/17 Track C 15:10 / iOSと人工知能(AI) -GPU並列演算の仕組みと機械学習- / Yukinaga Azuma(我妻幸長)
内容は4章仕立てで、人工知能概要の解説から、AppleのMetalテクノロジーによるGPUを用いた独自AIの実装までお話ししました。
以下は発表原稿の全文になります。スライドを前提にした解説の箇所があるのはご容赦ください。
プロローグ
ご紹介を有難うございました、我妻と申します。
本日は、iOSと人工知能、GPU並列演算の仕組みと機械学習というタイトルで、iOSアプリの中のAIについてお話しいたします。
それではまず自己紹介から始めたいと思います。
現在エンジニア及びR&D、そしてプログラミング講師をしております。
経歴ですが、大学の研究員やメーカー勤務、プログラミング講師、ベンチャー勤務などを経て現在はフリーランスです。
現在、オンライン動画教育プラットフォームUdemyでAI関連の講座を開講しています。
みんなのAI講座、実践データサイエンス&機械学習という2つの講座で、受講生の数が8000人を突破しました。
好きな言葉ですが、”未来を予測する最良の方法は、それを発明すること”というアラン=ケイの言葉です。
それではここで、本日の発表の流れを説明したいと思います。
全部で4章仕立てでお送りります。

第1章、人工知能とは、では人工知能全般の解説を行います。
第2章、iOSの中のAIでは、実際にiOSでどのようにAIが関わっているか概観を把握していただくために、iOSの中で使われているAI関連のFrameworkの簡単な解説を行います。
第3章、MetalによるGPU並列演算では、iOSにおいて人工知能開発に有用な、Metalを用いたGPU並列演算の解説及びちょっとした実験のお話をします。
第4章、MetalによるAIの実装では、ニューラルネットワークを用いた人工生命や、生物の群れを再現した群知能のデモを行います。
第1章

それでは、早速1章に入ります。
ここでは、人工知能の概要、機械学習とは何か、ニューラルネットワークとは何かについて解説します。
そして、Swiftで実際にニューラルネットワークとバックプパゲーションの仕組みを構築し、人工知能が学習していく過程のデモを行います。
それでは最初に、人工知能とは何か、についてお話をしていきます。人工知能の定義は人によって様々ですが、大まかに言って生物の知能を模倣する技術、と言えるかと思います。
しかしながら、近年はニューラルネットワークベースの機械学習が注目を浴びていることもあり、それを狭い意味で人工知能と呼ぶ方も多いです。
さて、AIには強いAIと弱いAIという概念があります。
強いAIは生物、特にヒトの知能に迫るAIのことです。
例えば、ドラえもんや鉄腕アトム、スターウォーズのC-3POなどの想像上のAIは強いAIにあたります。
弱いAIは限定的な問題解決や推論行うためのAIです。
例えば、チェスや将棋のAI、画像認識などは弱いAIにあたります。
現在地球上で実現されているのは、この弱いAIのみで、強いAIは実現されていません。
ヒトの脳を再現することは例えスーパーコンピュータでもできないわけですが、第4章では極めてシンプルな人工生命を、人工知能を使って動作させることにトライします。
そして、この弱いAIですが、現在このような分野で用いられています。
画像認識や画像処理では物体認識や画像生成、
音声や会話認識の分野では音声認識や会話エンジン、
文章の認識や文章の作成の分野ではチャットロボットや小説の執筆など、
機械制御の分野では、自動運転や産業用ロボットなど、
作曲、絵画などのアートの分野では自動作曲や画風の模倣などが行われています。
他にも様々な分野で人工知能は用いられています。
それでは、人工知能にはどのような種類があるのか、いくつかリストアップしていきます。
まず、機械学習です。
現在、人工知能といえば機械学習のことを指すほどメジャーになっています。
まるでヒトのように、コンピュータが経験及び学習を行います。
そして、遺伝的アルゴリズムです。生物の遺伝子を模倣し、アルゴリズムが突然変異、及び交配を行います。
また、群知能というものもあります。
これは生物の群れを模倣したもので、シンプルなルールに則って行動する個体の集合体が、集団として高度な振る舞いをします。
この群知能に関しては、後ほどデモを行います。
その他にも、ファジイ制御やエキスパートシステムなど、人工知能と呼ばれる仕組みは数多くあります。
それでは、ここからは機械学習のお話をします。
先ほどお話しした通り、機械学習は人工知能の一分野であり、コンピュータプログラムが経験、学習を行います。
近年Appleが特に力を入れている分野の一つであり、後ほど紹介しますが、様々なFrameworkがiOS向けに提供されてきています。
機械学習といえばニューラルネットワークベースのものを指すことも多いのですが、実は機械学習には様々なアルゴリズムがあります。
例えば、サポートベクターマシン、これは多次元における超平面を用います。この超平面を訓練し、データ群の分類を行います。
また、決定木は枝分かれでデータを分類します。ツリー構造を訓練することで、データの適切な予測ができるようになります。
ニューラルネットワークは脳の神経細胞ネットワークを模倣したものですが、ディープラーニングの成功により大きな注目を集めています。
これに関しては後ほど詳しく解説します。
他にも、機械学習にはアンサンブル学習やK近傍法など様々なアルゴリズムがあります。
それでは、ここからニューラルネットワークによる機械学習のお話をしていきます。
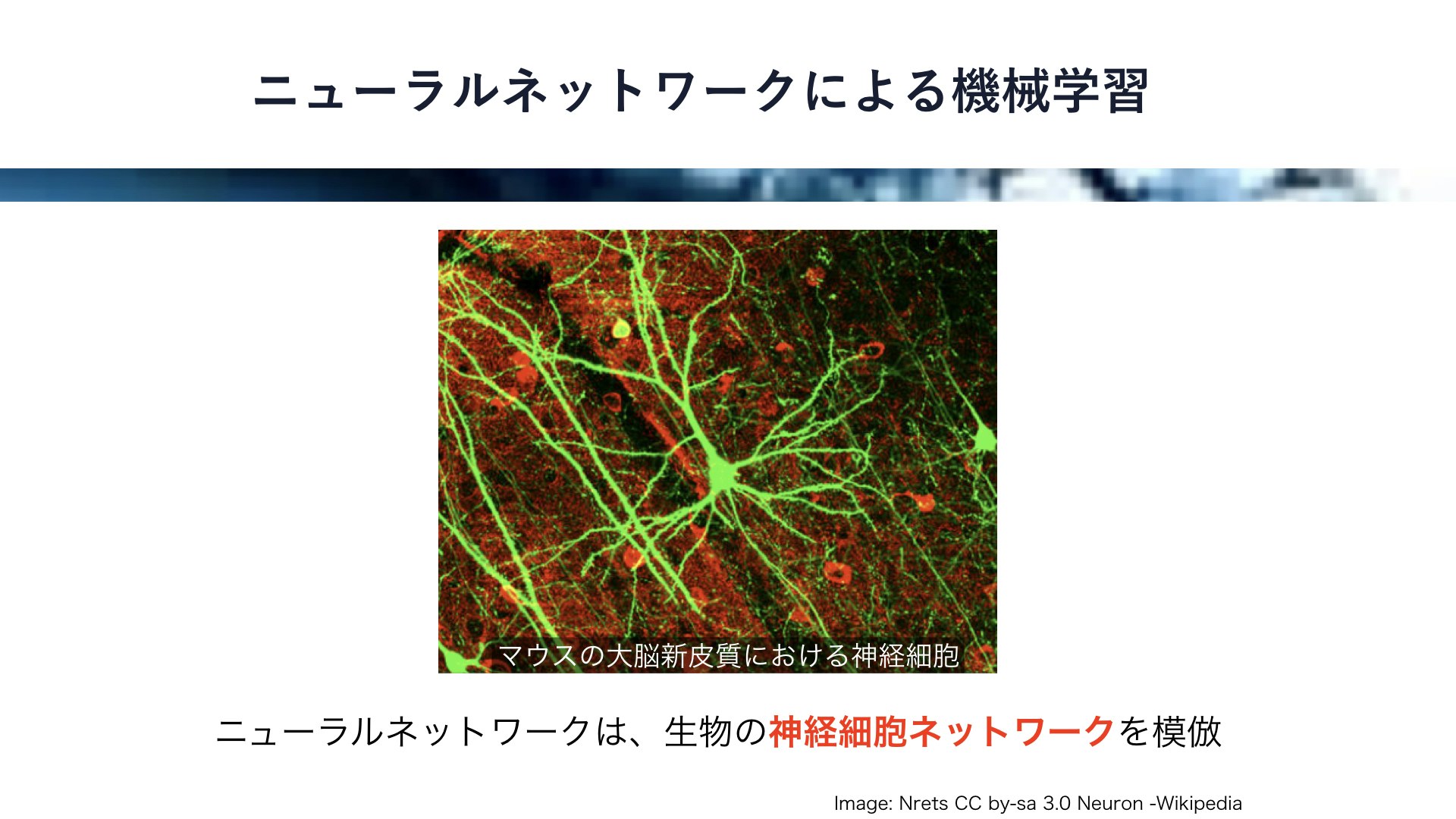
これはマウスの大脳新皮質における神経細胞を緑色に染色したもので、大きさは数マイクロメートル程度です。
まるで木のように、枝のようなものと根のようなものが伸びています。
ニューラルネットワークは、このような神経細胞のネットワークを模倣したものです。
それでは、その神経細胞のネットワークのお話をします。
ここに模式図を示しますが、神経細胞、すなわちニューロンには長い軸索があってそこから他のニューロンへの出力がパルスとして伝わります。
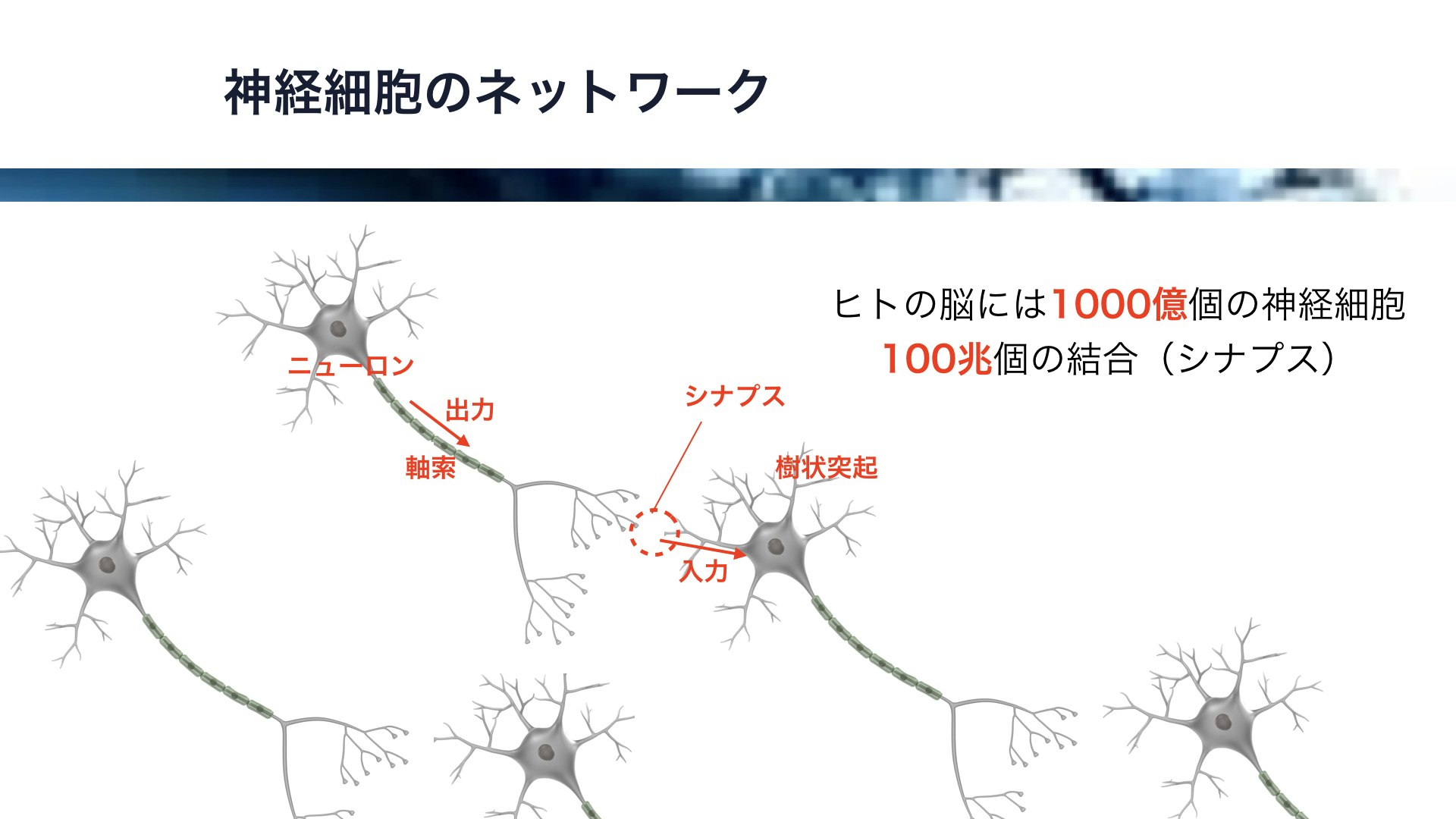
これは他の神経細胞の樹状突起に入力として伝わります。ニューロン本体では複数の入力を元に演算が行われ、結果が新たな出力となります。
なお、ニューロン同士の接合部はシナプスと呼ばれており、この結合強度が記憶の正体であると言われています。
ヒトの脳には約1000億個の神経細胞がありり、神経細胞の一個あたり1000個の接続があると考えられています。すなわち、脳全体で100兆個のシナプスがあり、複雑な記憶や、あるは意識に関連しているとも言われています。
それでは、この神経細胞をモデル化します。
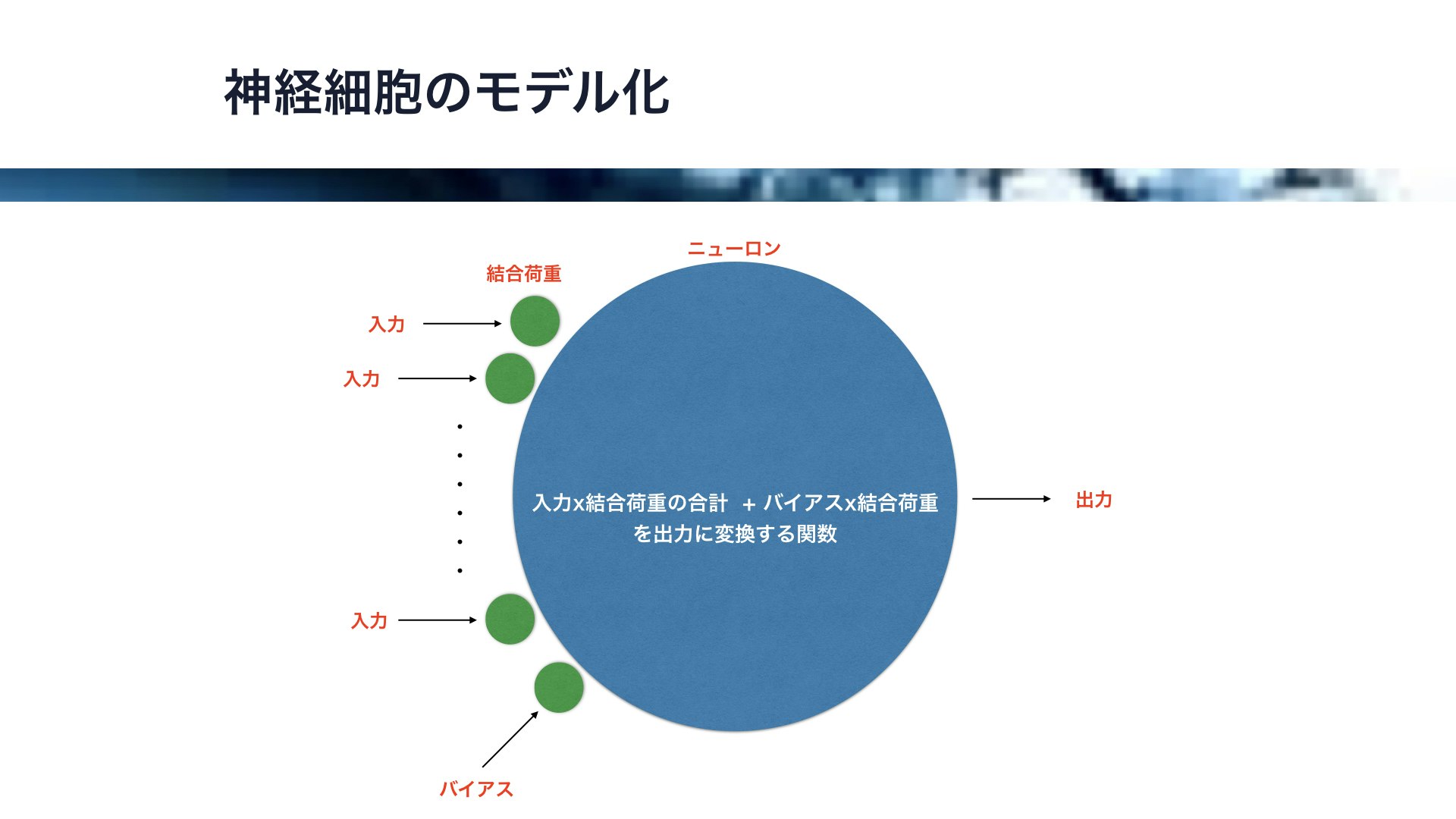
この青い丸がニューロンを、この緑の丸がシナプスの強度を表す結合強度です。
このように、複数の入力とそれに対応した結合荷重をかけたもの、及びとバイアスと呼ばれる定数とそれに対応した結合荷重をかけたものの合計を計算し、その値を関数に入れて出力値を算出します。
この変換するための関数には、シグモイド関数と呼ばれるものやReluとよばれる関数が用いられることが多いです。
そして、このニューロンを組み合わせてネットワークを構築します。
ここに図で示すニューラルネットワークは、入力層、隠れ層、出力層の三層構造をしています。
複数の入力を用いて演算を行い、複数の出力が得られるわけですが、これを用いて予測や判断、分類などを行うことができます。
このようにニューラルネットワークには複数の結合荷重があるのですが、この結合荷重の値を調整することでニューラルネットワークは学習を行うことができます。
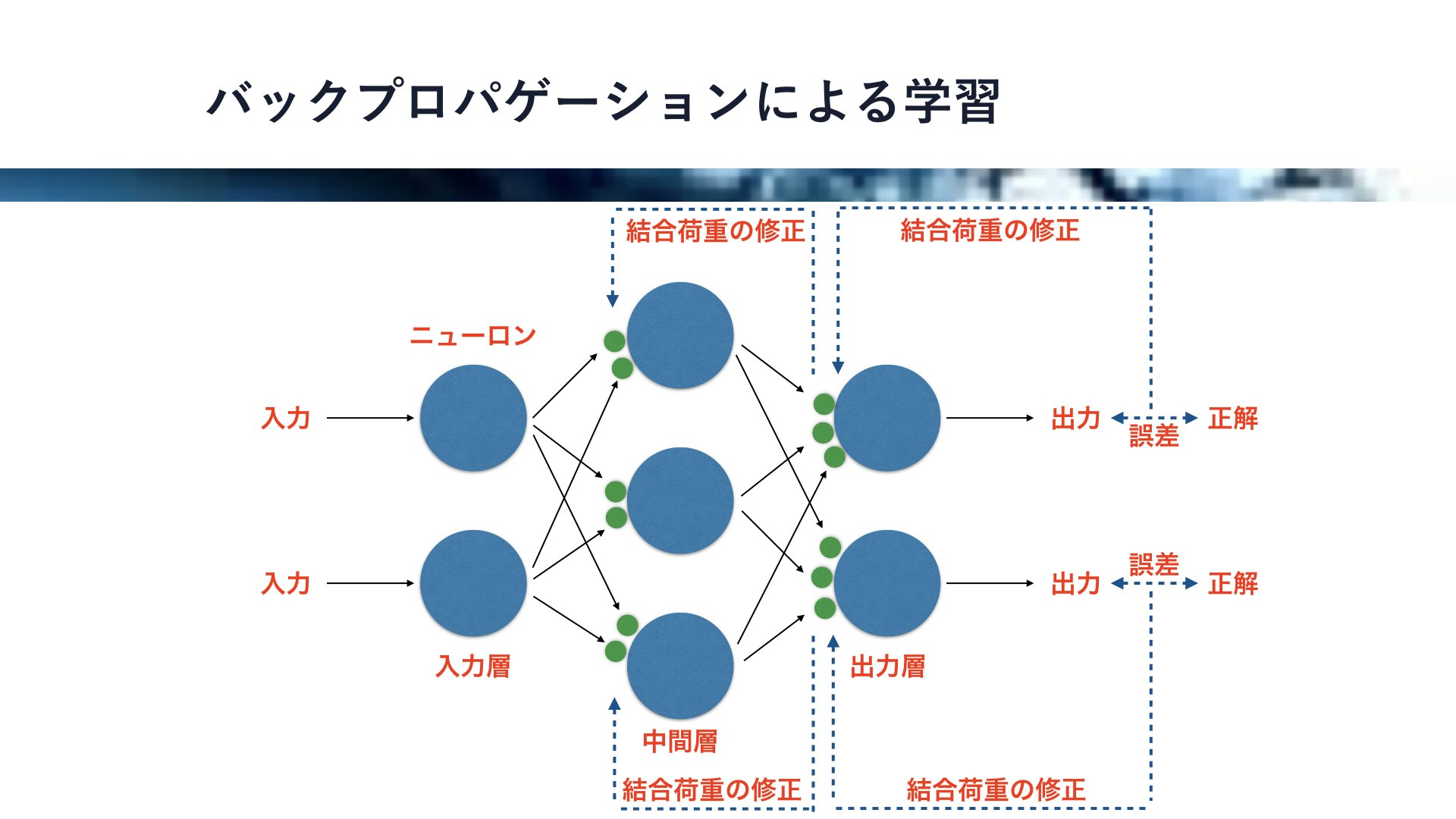
それでは、そのニューラルネットワークの学習のためメジャーなアルゴリズム、バックプロパゲーションを紹介したいと思います。
各出力値に対して、それぞれ正解値を与えてやり、この正解値と出力値の誤差を元に直前の結合荷重の値を修正します。そして、結合荷重の修正量を元に、さらに前の層の結合荷重の修正量を計算し修正します。
これを繰り返すことで、誤差をもとに全ての層の結合荷重を修正することができるわけです。
このようなニュールネットワークのうち、層の数を多くした学習をディープラーニングといいます。
Alphagoが囲碁チャンピョンに勝利したことや、高度な画像認識やで注目を浴びているアルゴリズムです。
ヒトの脳に迫る非常に高度な学習を行うことができるのですが、iO11から登場するCore MLを用いることで比較的簡単に実装することもできます。これに関しては、後ほど少し触れます。
それでは、実際にSwiftを用いてニューラルネットワークとバックプロパゲーションのコードを書いてみます。
今回は、ニューラルネットワークにサインカーブを学習させます。
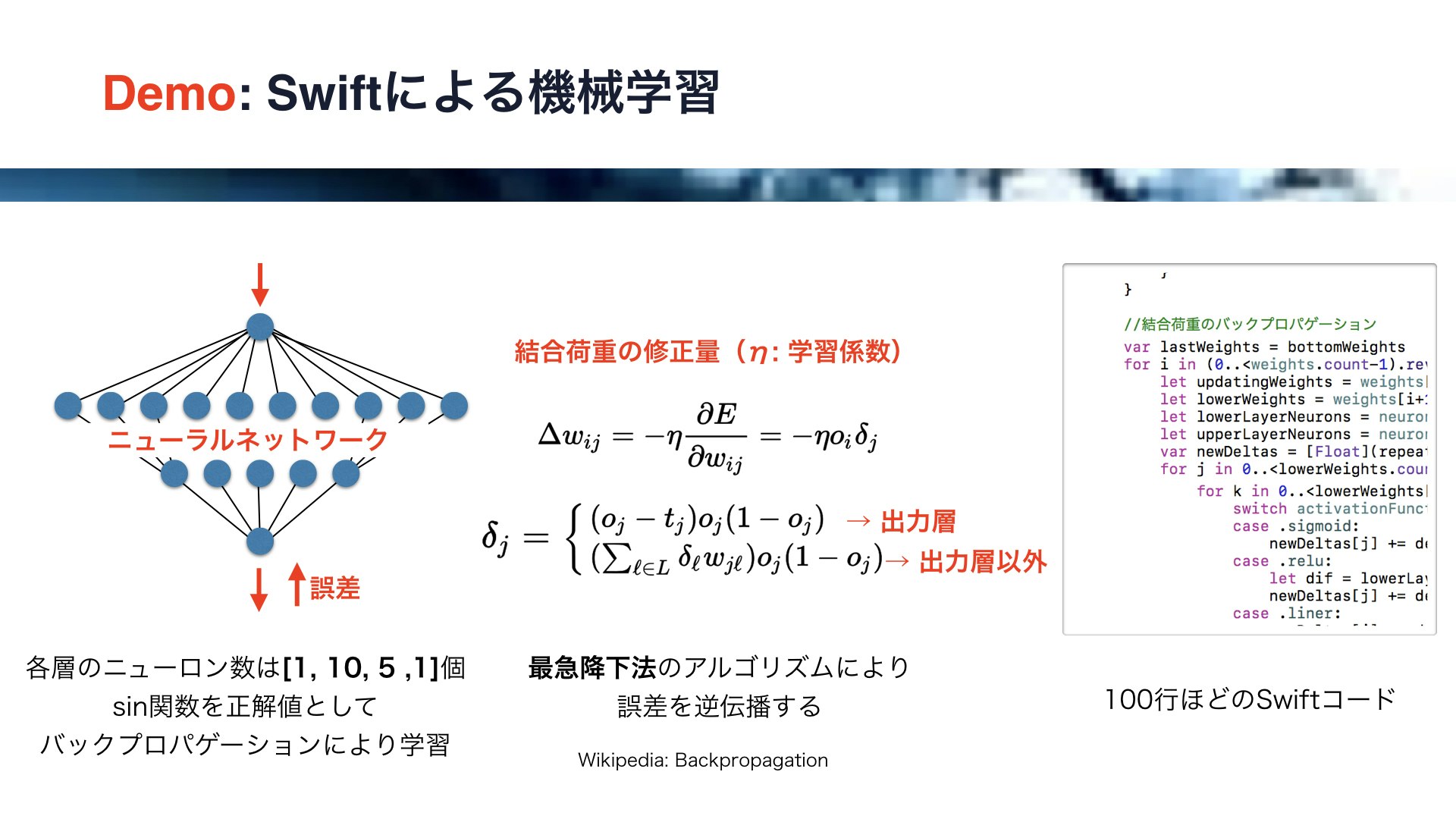
左の図にご注目ください。
これは四つの層からなるニューラルネットワークで、各層のニューロンの数はそれぞれ、1, 10 ,5 ,1です。
入力に対するsin関数の値を正解値として、出力値との誤差をバックプロパゲーションにより学習させます。
また、このバックプロパゲーションには最急降下法というアルゴリズムを用います。
中央にご注目ください
結合荷重の修正量ですが、このように誤差を結合荷重で偏微分して、学習係数イータをかけることにより求めます。
この学習係数によりニューラルネットワークの学習速度が決まるわけですが、この値が大きすぎても結合荷重が発散してしまいます。
また、このデルタの値ですが、出力層とそれ以外の層で求め方が異なります。
デルタの値はまず出力層で求めて、それを一つ上の層に順番に伝播させていくことになります。
以上のロジックはSwiftを用いて100行ほどのコードで記述することができます。
それでは、動画でデモを行います。
画面上には無数のバラバラに配置された金魚が見えますが、機械学習によりそれぞれの位置がSinカーブに沿って収束します。
それでは、デモを開始しますので画面にご注目ください。
(動画は以下から視聴可能です)
iOSDC2017でデモしたニューラルネットワーク+バックプロパゲーションによるsinカーブ収束の動画です。コードはSwiftで書かれています。 #iosdc pic.twitter.com/1g655uQaZO
— Yukinaga Azuma (@yuky_az) September 19, 2017
このように、金魚が少しずつ移動して、最終的にサインカーブの形を描きます。
これは、ニューラルネットワークがサイン関数を学習したことを意味します。
それならば、最初からサイン関数を使えばいい、と思う方もいるかもしれません。
しかしながら、人工知能の魅力は学習に時間はかかるのですが、様々な環境を柔軟に学習できるところにあります。
このニューラルネットワークでも、やろうと思えば他の関数を学習させることもできます。
極めて部分的にですが、ヒトのものに近い柔軟な認識能力を、ニューラルネットワークは発揮できるのです。
(コードはこちら)
第2章

それでは第二章に入ります。
この章では、iOSの中のAIを紹介していきます。
iOSで使用可能な人工知能関連のフレームワークには以下のようなものがありますので、順番に軽く紹介しています。
Core ML、Metal Performance Shders、Basic Neural Network Subroutines、GameplayKitの順番です。
これらのフレームワークの構成ですが、この図のようになっています。
一番ハードウェアに近いところにあるのが、CPUで動作するAcceratateとBNNS、そしてGPUで動作するMetal Performance Shdersです。
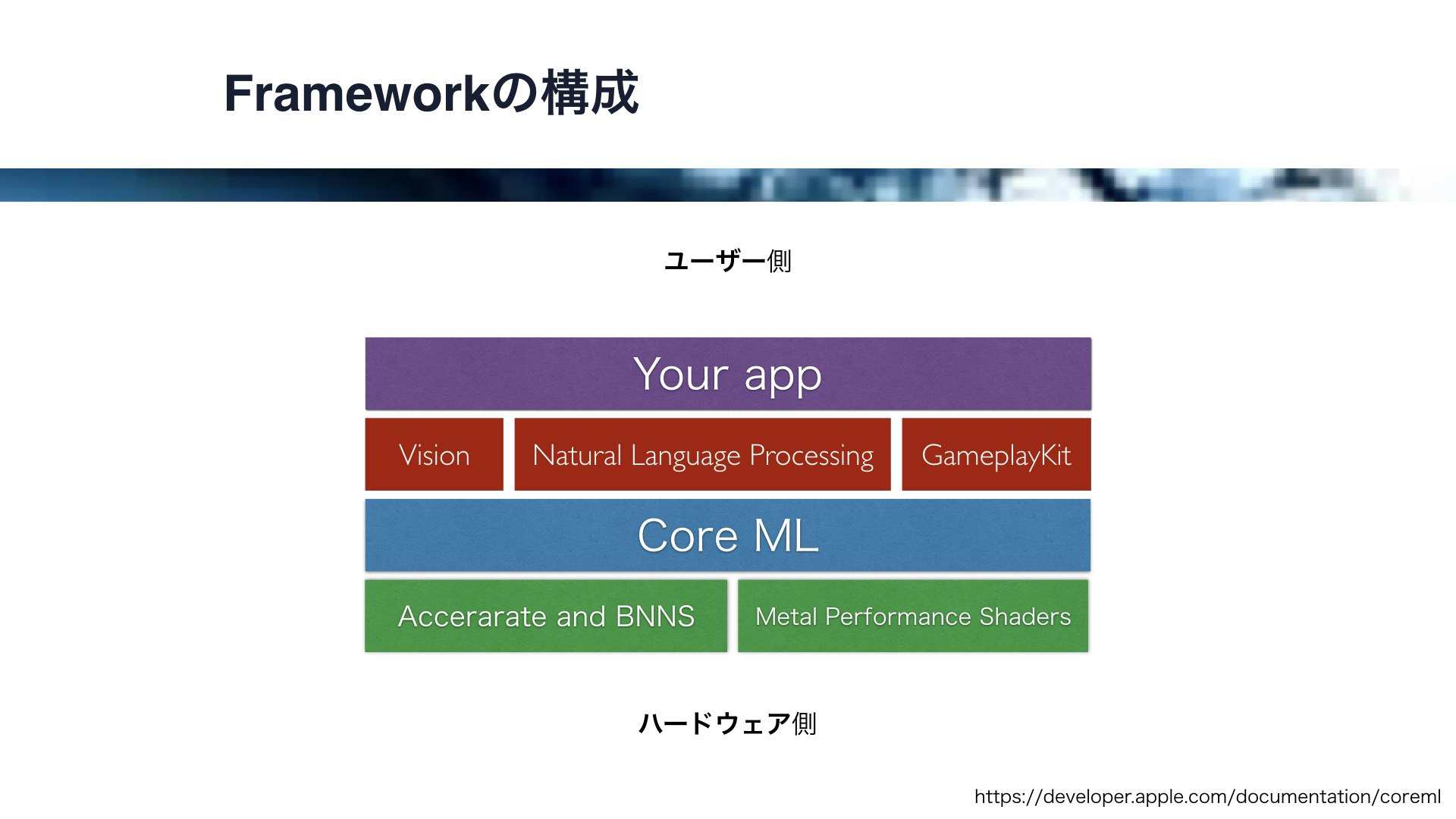
そして、それらをベースとして動作する機械学習フレームワークが、iOS11で導入されたCore MLです。
また、このCore MLをベースとして、画像解析のVisionフレームワーク、自然言語解析のNtural Language Processing、ゲーム用のGameplayKitフレームワークが動作します。
これらの基盤の上に、アプリ開発者は比較的容易に人工知能をアプリに導入することができるわけです。
それでは、まずCore MLから簡単に解説していきます。
Core MLでは訓練、すなわち学習済みのモデルをアプリに導入することができます。
このフレームワークは、機械学習の予測に特化したツールで、モデルの訓練はできません。
CoreMLでは、例えばscikit-learn、ケラス、カフェのような主要な機械学習ツールの訓練済みモデルを使用することができます。
応用としては、例えば顔認識、物体認識、自然言語処理、翻訳、不動産価格などの予測、などがあります。
次に、MPS、Metal Performance Shadrsです。
このフレームワークは、GPUを用いたMetalの高い演算能力をアプリに導入します。
このフレームワークはCore MLのベースの一つとなっていますが、Core MLと同様に機械学習の予測に特化しています。
また、MPCNNと呼ばれる畳み込みニューラルネットワークのAPIを備えています。
畳みこみニューラルネットワークは生物の視覚を模倣したもので、高度な画像の識別が可能です。
MPSはCoreMLよりも低レイヤーなのでコードはより複雑になりがちです。
AppleはこのMPSのサンプルコードをいくつか提供していますので、興味のある方は試してみてはいかがでしょうか。
サンプルコードで、文字認識や画像認識、画像フィルタなどを試すことができます。
また、これもCore MLのベースとなっているのですが、Basic Neural Network Subroutinesと呼ばれるものもあります。
これは、数値計算処理全般を扱うAccerlerateフレームワークに含まれています。
BNNSはGPUではなくCPUの性能をフルに引き出して演算を行います。
これも、機械学習の予測に特化しています。
MPSと同様に畳み込みニューラルネットワークをサポートしており、画像認識などに用いることができます。
そして、GameplayKitです。
これは、ゲームのロジックを構築するためのフレームワークです。
CoreMLをベースに、敵キャラなどの動きに機械学習の一種、決定木を用いることができます。
また、ミニマックス法を用いて、オセロやチェスなどの対戦相手のAIを構築することができます。
GameplayKitではAgent、Goals、Behaviousというものがあるのですが、これを用いて自律的に動くオブジェクトをつくることができます。
さらに、これはハードウェアの話になるのですが、iPhoneXとiPhone8にはA11 Bionicのチップが導入されます。
これは毎秒最大で6000億の演算処理が可能であり、ニューラルエンジンによる機械学習アルゴリズムの高速化が可能であると言われています。
また、Apple独自設計のGPUが導入されるそうです。
このようにフレームワーク、ハードウェア共に端末側のAI環境が整ってきたと言えます。
第3章
それでは第3章に入ります。
ここでは、MetalによるGPU並列演算、すなわちGPGPUのお話をします。

まず、GPU並列演算とは何か、の解説をして、Metalを支える登場人物、そしてパフォーマンス測定の実験のお話をします。
GPU並列演算ですが、一言で言うとGPUの演算リソースを画像処理以外に利用することです。
CPUはせいぜい数コアしかなく複数の処理を同時に走らせることは苦手なのですが、GPUは数千、数万の処理を同時に走らせることが得意です。
このGPU並列演算は膨大な演算を必要とする人工知能と相性が良く、人工知能に短時間で高度な判断を行わせるためには必須となるケースが多いです。
それでは、Metalとは何でしょうか。
Metalは、OpenGLとOpneCLに似た機能を一つのAPIに統合し、CPUとGPUのシームレスな連携を提供します。
もちろん、AIとの相性がよくAppleはMetalをベースとしたAI関連のフレームワークを提供しています。
今回はMetalを通してGPUを制御するお話をするのですが、OpenGLのような画像処理の話ではなくてOpenCLのようなGPU並列演算のお話をします。
それでは、Metalにおいて、CPUとGPUはどのように連携するのでしょうか。
それを、この図で示します。
CPUはGPU側で実行される関数を含んだCommandBufferをGPU側に送ります。
CPUとGPUは共通メモリをシェアしており、これを用いてデータのやり取りを行うことができます。
ここで、Metalを支える登場人物を紹介していきます。
まず、CPU側の登場人物です。
一番大事なのは、MTLDeviceで、これは単一のGPUのインターフェイスです。
これはMTLCreateSystemDefaultDeviceで生成することができます。
MTLDeviceはクラスではなくプトロコルです。Metal関連の機能の多くはクラスではなくプロトコルとして提供されていますが、これは様々な異なるGPUを扱うために、インターフェイスのみ提供しているためと考えらえます。
実際に、このようにnameプロパティをprintするとGPUの名称を取得することができます。
それでは、その他の登場人物を紹介していきます。
これらは、ほとんどMTLDeviceによって生成されます。
MTLLivraryはシェーダーへのインターフェイス
MTLFunctionはMetal Shading Languageで書かれた関数、
MTLComputePipelineStateはMTLFunctionをコンパイルされたコードに変換します。
また、MTLComputeCommandEncoderはコマンドをGPU用にエンコードし、
MTLCommandBufferはGPUで実行されるコマンドを格納します。
そして、MTLCommandQueueはMTLCommandBufferを格納するキューで、コマンドの実行順を管理します。
それでは次に、Metal Shading Language、すなわちGPU側で実行されるコードを紹介していきます。
Metal Shading LanguageはC++をベースとして言語なので、基本的な文法はC++の通りです。
GPU側で並列で実行される処理の単位をスレッドと言いますが、各スレッドごとにこのような関数が実行されます。
CPU側からの入力や出力は引数のバッファーでやり取りすることができて、スレッドのidは引数のidで知ることができます。
ここには、シンプルに入力に1を足して出力とする、という関数が書かれています。
それでは、実験を行います。GPUとCPUのパフォーマンスの比較です。
入力に1を足して1を引くを繰り返すシンプルな処理を、CPU側では1万xN回、GPU側では1万スレッドxN回行います。
この際のGPU側のコードはこの通りです。
ループを使ってN回繰り返し処理を行っています。
それでは、結果です。
このグラフは横軸がN、すなわちリピート数、縦軸が処理の所要時間です。
青い線がMetalの結果で、緑の線がCPUの結果です。
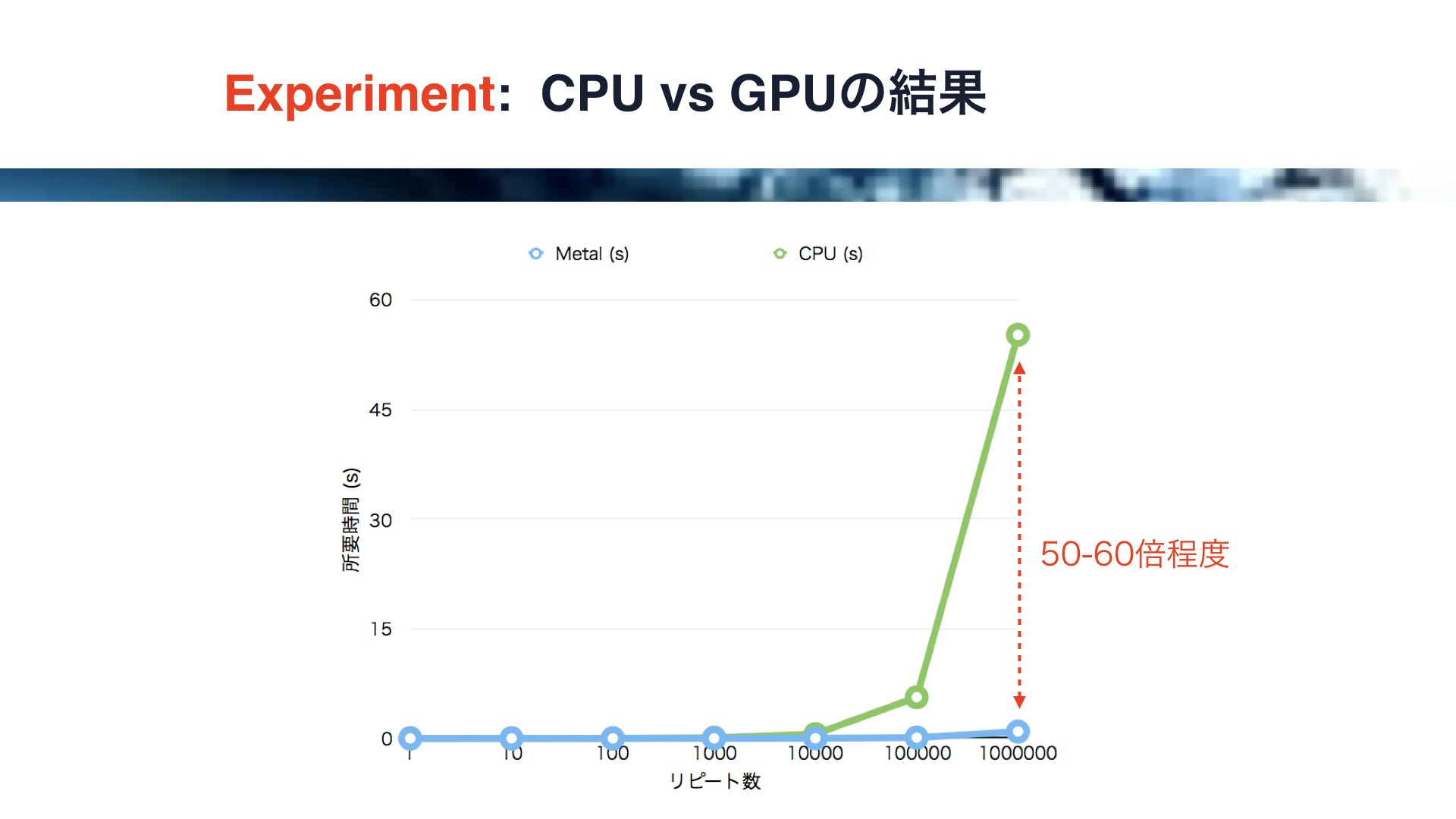
このようにリピート数が多いと両者のパフォーマンスに50-60倍もの開きがあることがわかります。
しかしながら、このグラフではリピート数が少ないときの比較ができないので、次に縦軸を対数にしてみます。
すると、このように見えかたが変わります。
リピート数が少ない時は、何とCPUの方がMetalよりもパフォーマンスが高いという結果が得られました。
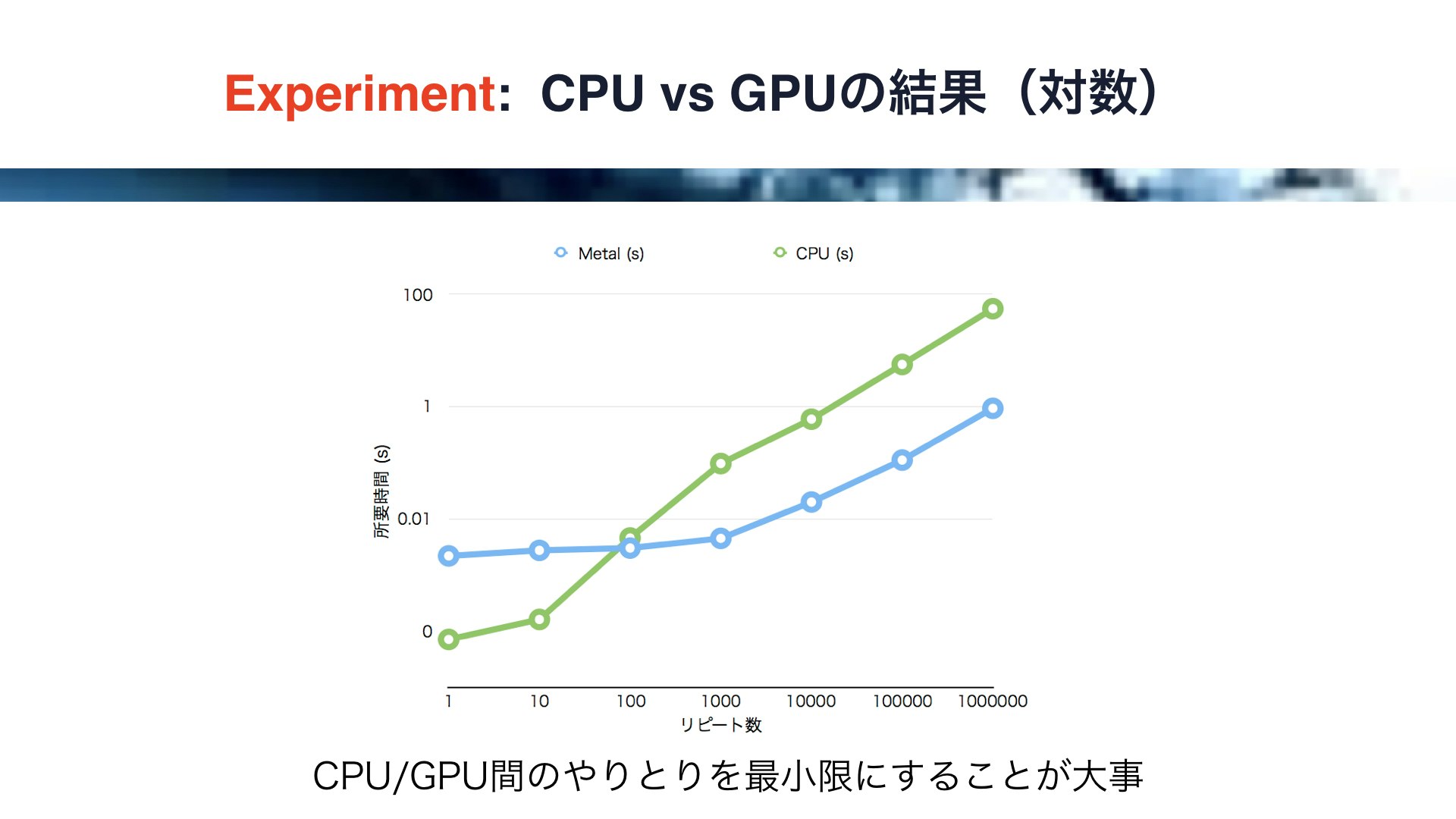
これは、GPU側で実行される処理の量が少ない場合、CPUとGPUのやり取りのコスト、すなわちドローコールのコストの割合が大きくなることを意味すると考えられます。
従って、MetalにおいてGPUのパフォーマンスをフルに発揮するためには、ある程度大きな処理をGPU側で行えるように、GPUとGPUのやり取りを最小限にする必要があるわけです。
この例からも分かる通りGPU並列演算は癖が強いので、アプリを開発する際は試行錯誤しながらその特性を把握する必要があります。
第4章
それでは、最後の第4章に入ります。
ここでは、実際にMetalを用いてAIの実装を行います。

まずは、ニューラルネットワークとバックプロパゲーションにより、先ほどSwiftによるデモと同等の、sinカーブの収束のデモを行います。
そして、内部にニューラルネットワークを仕込んだ人工生命の実装を行います。
最後に、各個体が群れになった時に興味深い現象が見られる、群知能の実装を行います。
それでは最初に、Metalを用いた機械学習の例として、sinカーブの収束をDemoします。
GPU側で各ポジションに対応した複数のニューラルネットワークを同時に計算し、それぞれバックプロパゲーションを行います。
今回はGPU側で101個のニューラルネットワークを同時に計算し、得られた結合荷重の修正量をCPU側で統合し、新たな結合荷重とします。
この処理を繰り返すことにより、ニューラルネットワークはサインカーブを学習します。
各点の出力値は、サインカーブで決定される値に次第に近づいていきます。
クラス構成はこのようにします。
演算のみMetalManagerとShaderで行い、描画はMetalで行わずにUIImageViewのサブクラスで行います。
この場合、Metalでは純粋に演算のみ行っていることになります。
それでは、デモを実行します。
このアルゴリズムですと一度の結合荷重の修正量が大きいので最初は大きくぶれますが、やがて少しずつサインカーブが収束していく様子をみることができます。
(動画は以下から視聴可能です)
同じ原理による機械学習を、今度はMetalを用いて実装しました。 #iosdc pic.twitter.com/LcF7dk7eiU
— Yukinaga Azuma (@yuky_az) September 19, 2017
なお、今回のアルゴリズムではCPUとGPUのやりとりの割合が大きいため、Metal本来のパフォーマンスは発揮できていません。
CPU側の処理を減らしほとんどをGPU側で処理してしまえばいいのですが、今回は学習過程を表現するためにCPU側とのやり取りが頻繁に発生します。
個人的には、学習結果だけではなく、実はこの学習過程も面白いのではないかと考えています。
次には、この学習過程を用いて人工生命を実装するお話をします。
それでは、ここから人工生命のお話をします。
体長1mmほどの線虫の一種、C・エレガンスをご存知でしょうか。
この線虫はいくつものノーベル賞に寄与した凄いやつなんです。
体細胞1000個のうち、約300個が神経細胞です。

実はこの線虫のすべての神経細胞の接続がこれまでに明らかになっています。
神経細胞の接続状態を表した地図のことをコネクトームと呼びますが、右に示すのはこの線虫のコネクトームです。
これは、自然界における知能のミニマルな実装、と考えることもできます。
もし知能の本質がコネクトームであるならば、それをモデル化することで生物の知能を再現できるはずです。
それでは、ここから簡単なコネクトームを持った人工生命のモデル化を行います。
まず、ある領域に匂いの分布を作ります。
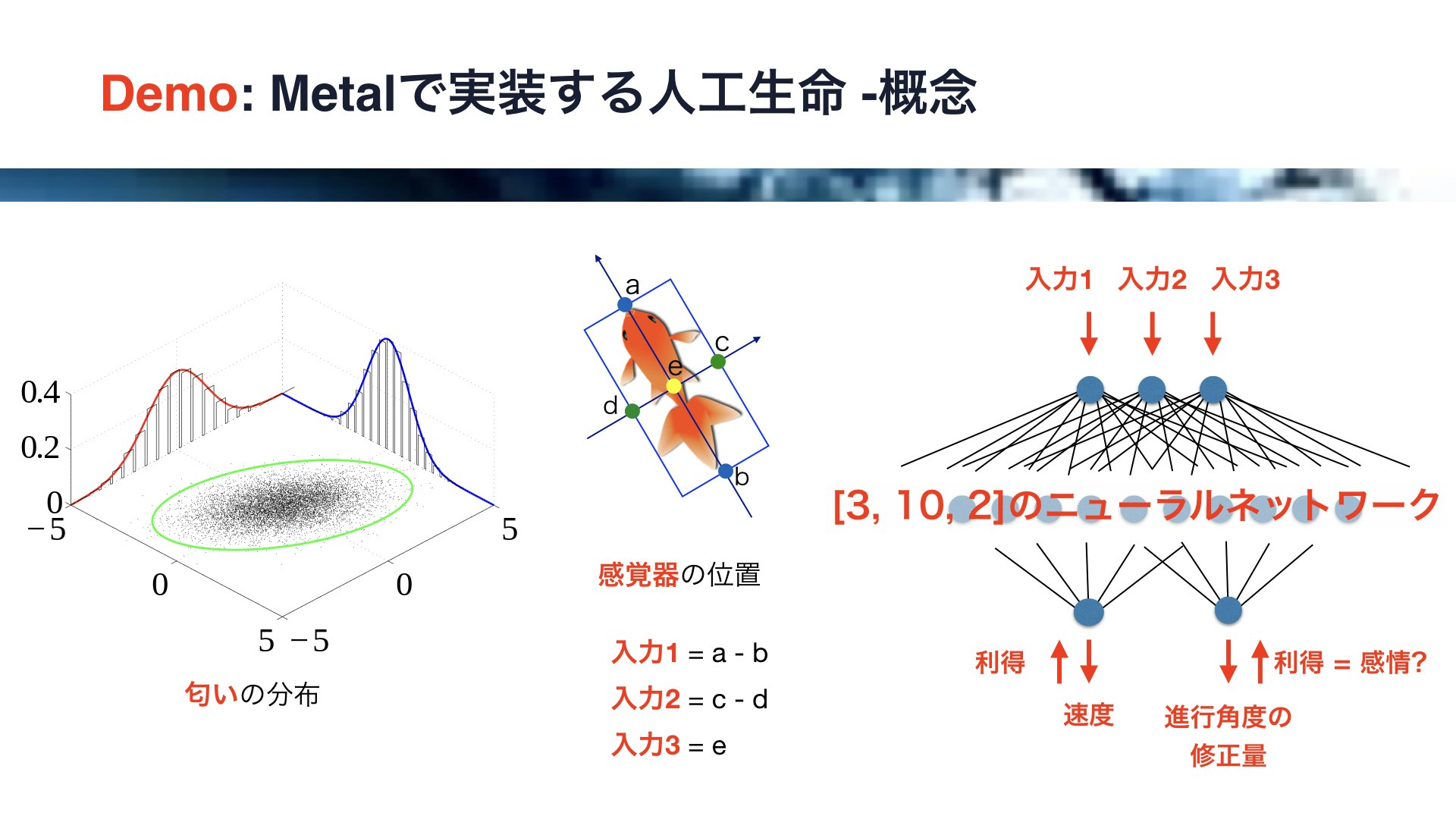
左側の図にご注目ください。
匂いの分布は正規分布とし、領域の中央で匂いが強くなるようにします。
そして、各個体の感覚器の位置を決めます。
中央の図にご注目ください。
ここでは金魚の画像を用いていますが、前方と後方、左右および中央に感覚器を配置し、前後の差分、左右の差分、及び中央の匂いの値を入力値とします。
これらの3つの値を入力に対して、3、10、2の三層のニューラルネットワークを構築します。
右側の図にご注目ください。
先ほどの線虫の300個の神経細胞からなるコネクトームと比較すると、かなりシンプルです。
出力は2つで、それぞれ速度と進行角度の修正量です。
今回は誤差の代わりに、移動した際の匂いの利得、すなわち匂いの増減を用いてバックプロパゲーションを行います。
この利得ですが、感情のようなもの、と考えることもできるかもしません。
利得がプラスの場合は嬉しいという感情を、マイナスの場合は嫌だという感情が発生し、それに応じて行動が変化する、と解釈することも可能かと思います。
それでは、デモを行います。
ご注目ください。
(動画は以下から視聴可能です)
iOSDC2017のデモ、Metalによる人工生命です。各個体にはニューラルネットワークが仕込んであり、バックプロパゲーション+強化学習により動きます。 #iosdc pic.twitter.com/E1VKpQlxrP
— Yukinaga Azuma (@yuky_az) September 19, 2017
ご覧の通り、多数の個体が思い思いの動きをしています。
ある個体は、同じところを周回し、ある個体は同じ場所から動きません。
しかしながら、いくつかの個体は止まったり動いたりしながら、探索をしている様子です。
画面中央が一番臭いが強いのですが、しばらく時間が経過するといくつかの個体は中央付近をぐるぐると回り始めたり、中央付近で動かなくなったりします。
これは、これらの個体が学習に成功し、匂いの強い場所に滞在し続けることを覚えたことを意味します。
今回用いたのは非常にシンプルなコネクトームですが、それでもまるで生物の知能のようなものを少しは再現できることが分かりました。
それでは次に、群知能のデモを行います。
群知能は人工知能の一種で、個体が集団になったときに発揮する、集団としての高度なふるまいのことです。
先ほどの人工生命では各個体の動きしか扱わなかったのですが、今回は個体同士の相互作用を扱います。
今回、各個体に適用したのは以下のたった3つのシンプルなルールです。
すなわち、等距離と平行と等速です。
各個体は、他の個体と等距離を保つように動き、また、同じ向き、同じ速度になるように動きます。
以上を数式で表現するとこのようになります。
ある個体と他のすべての個体の相互採用を計算します。

計算量が個体数の2乗に比例して増えるので非常に負荷がかかりますが、MetalによるGPU並列演算の本来の力を発揮できれば問題ないはずです。
そして、これらの等距離と並行と等速度の数式はシェーダーのコードに落とし込みます。
各個体の速度と進行方向を毎フレームごとに計算し、位置を更新していきます。
それでは、デモを行います。
(動画は以下から視聴可能です)
iOSDC2017のデモ、群知能です。各個体は簡単なルールに従って動きますが、全体して知性のようなものが発現します。 #iosdc pic.twitter.com/x8tNtptKGu
— Yukinaga Azuma (@yuky_az) September 19, 2017
最初は各個体がばらばらに動いているのですが、やがて金魚たちが集まって、まるで一つの生き物であるような動きをします。
無数の個体が集まって一つの個体を形成する様子は粘菌のようでもあり、各個体を細胞とするならば多細胞生物に例えることもできるかと思います。
このように、知能はシンプルなルールに従う個体の集合体として発現することもあるわけです。
アリの巣や、鳥の群れなどのような群体がイメージできますが、神経細胞も一個一個はシンプルなルールに従って動作しているうなので、脳もある種の群知能と言えるかもしれません。
それでは、まとめに入ります。
iOSと人工知能についてですが、
近年、AI用のフレームワークが充実してきており、端末側で動作するAIの存在感の向上が期待されます。
また、MetalによるGPU並列演算ですが、AIに必要な膨大なリソースを提供してくれます。
そして、Metalを用いて自由に人工知能を構築することも可能です。
このようにiOSアプリには次第に知性が宿りつつあります。
iPhoneはヒトと最も距離が近いコンピュータであり、今後ますます人類にとって大事なパートナーになっていくものと考えられます。
今回の発表は以上になります。ご静聴をありがとうございました。