ちゃお……†
今回はdefragTreesという機械学習ライブラリを紹介します。
defragTreesとは
RandomForestやXGBoostなどに対して、できるだけ精度やカバレッジを下げないようにしつつ、モデルをシンプルに(ルールを減らす)表現する手法を使ったライブラリです。
ルールが少ないので人間が見たときのわかりやすさがあります。
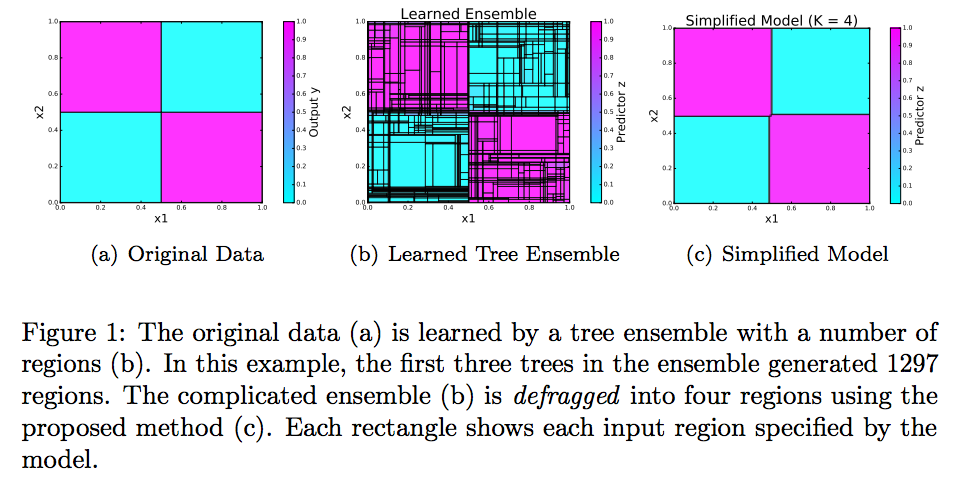
たとえば、元はシンプルなデータ(Figure 1 の a)でもアンサンブル学習すると無駄に複雑になってしまうことがあります (Figure 1 の b)。そこで、defragTreesを使うとオリジナルと同じようなシンプルさになります (Figure 1 の c)。
使い方
from defragTrees import DefragModel
Kmax = 10 # uppder-bound number of rules to be fitted
mdl = DefragModel(modeltype='regression') # change to 'classification' if necessary.
mdl.fit(y, X, splitter, Kmax)
splitterとしてRのRandomForest, XGBoostやscikit-learnのデータが使えます。
scikit-learnでirisを分類してdefragしてみる
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from defragTrees import DefragModel
iris = load_iris()
tree = GradientBoostingClassifier()
tree.fit(iris.data, iris.target)
splitter = DefragModel.parseSLtrees(tree)
mdl = DefragModel(modeltype='classification')
mdl.fit(iris.target, iris.data, splitter, 10, fittype='FAB')
ここでprint(mdl)するとルールを見ることができます。
[Rule 1]
y = 0 when
x_4 < 0.800000
[Rule 2]
y = 1 when
x_2 < 3.150000
x_3 < 4.750000
x_4 >= 0.800000
[Rule 3]
y = 2 when
x_1 >= 4.950000
x_3 >= 3.900000
x_4 >= 1.350000
[Otherwise]
y = 0
シンプルなルールでirisを分類できることがわかりました。