はじめに
LLM を本番環境で運用する際、モデルの精度やファインチューニングに注目が集まりがちですが、実際に運用コストとユーザー体験を左右するのは推論インフラの設計です。
クラウドの APIサービスを利用できる場合は、この部分はクラウド・サービス・プロバイダーがマネージドで面倒を見てくれますが、オンプレミスやクラウドの閉域で大規模な推論環境を構築しなければならない場合には避けて通れないテーマですね。
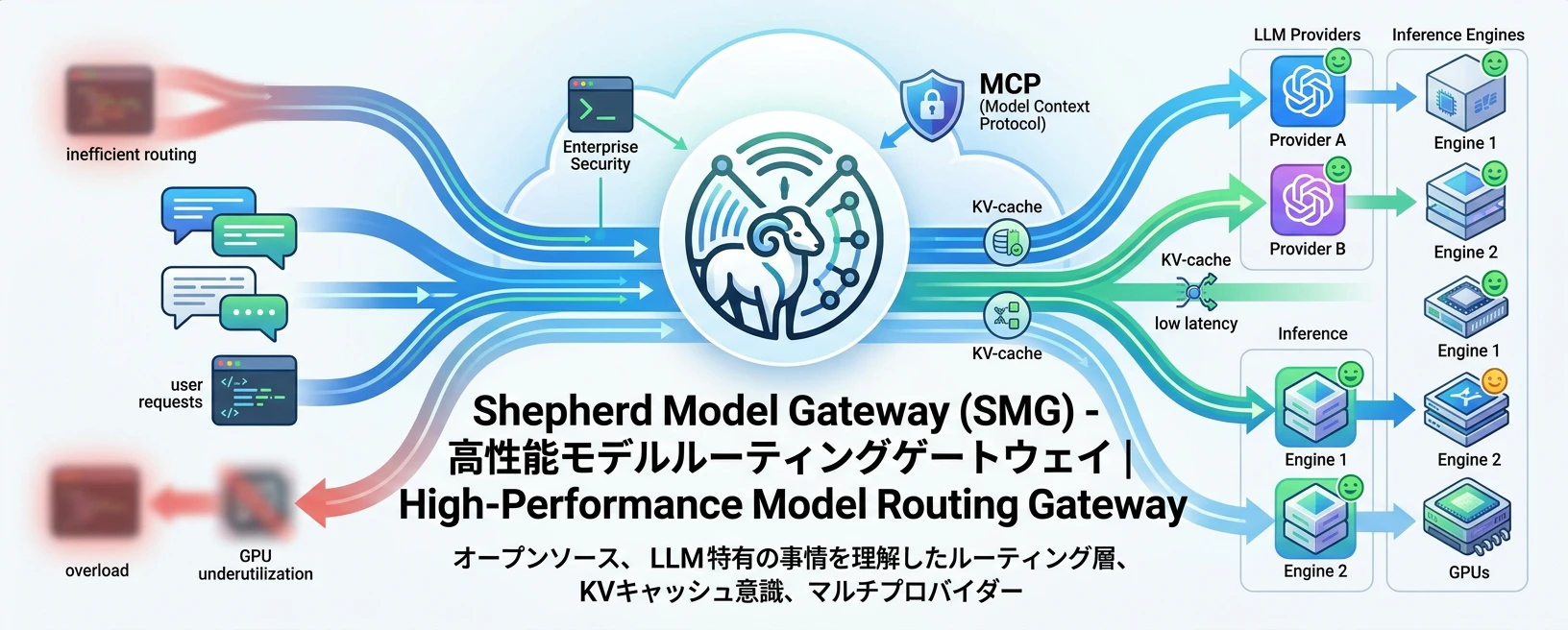
「GPU をどう使い切るか、待ち時間をどう抑えるか、複数のモデルやプロバイダーをどう束ねるか」、こうした課題に対して「LLM の事情を理解したルーティング層」というアプローチで挑んでいるのが、オープンソースの推論ゲートウェイ Shepherd Model Gateway(SMG) です。
本記事では、SMG の仕組みを理解するための前提として LLM 推論の基本構造(Prefill / Decode の2フェーズと KV キャッシュの役割)を整理したうえで、SMG がどのような課題をどう解決しようとしているのかを見ていきたいと思います。
Shepherd Model Gateway(SMG)とは
Shepherd Model Gateway(SMG)は、LLM の API推論サービスにおいて、高性能なモデルルーティングゲートウェイとして機能する、エンジン非依存(engine-agnostic)の推論ゲートウェイで Apache-2.0 license のオープンソースです。ワーカーのライフサイクル管理、HTTP/gRPC/OpenAI互換バックエンドへのトラフィック分散に加え、チャット履歴の保存、MCPツーリング、プライバシー制御といったエンタープライズ向け機能も備えています。

LLM 推論を本番環境で安定運用するうえでの最大の難所は、GPU を高稼働させつつ、ユーザー体験(待ち時間)を悪化させない形で、リクエストを"最適な推論先"へ振り分けることです。SMG はこの課題に対し、単なるロードバランサを超えた「LLM 特有の事情を理解したルーティング層」を提供します。
LLM 推論の基本構造(Prefill と Decode の2フェーズ)
SMG の仕組みを理解するために、まず LLM 推論の基本的な流れを押さえておきます。
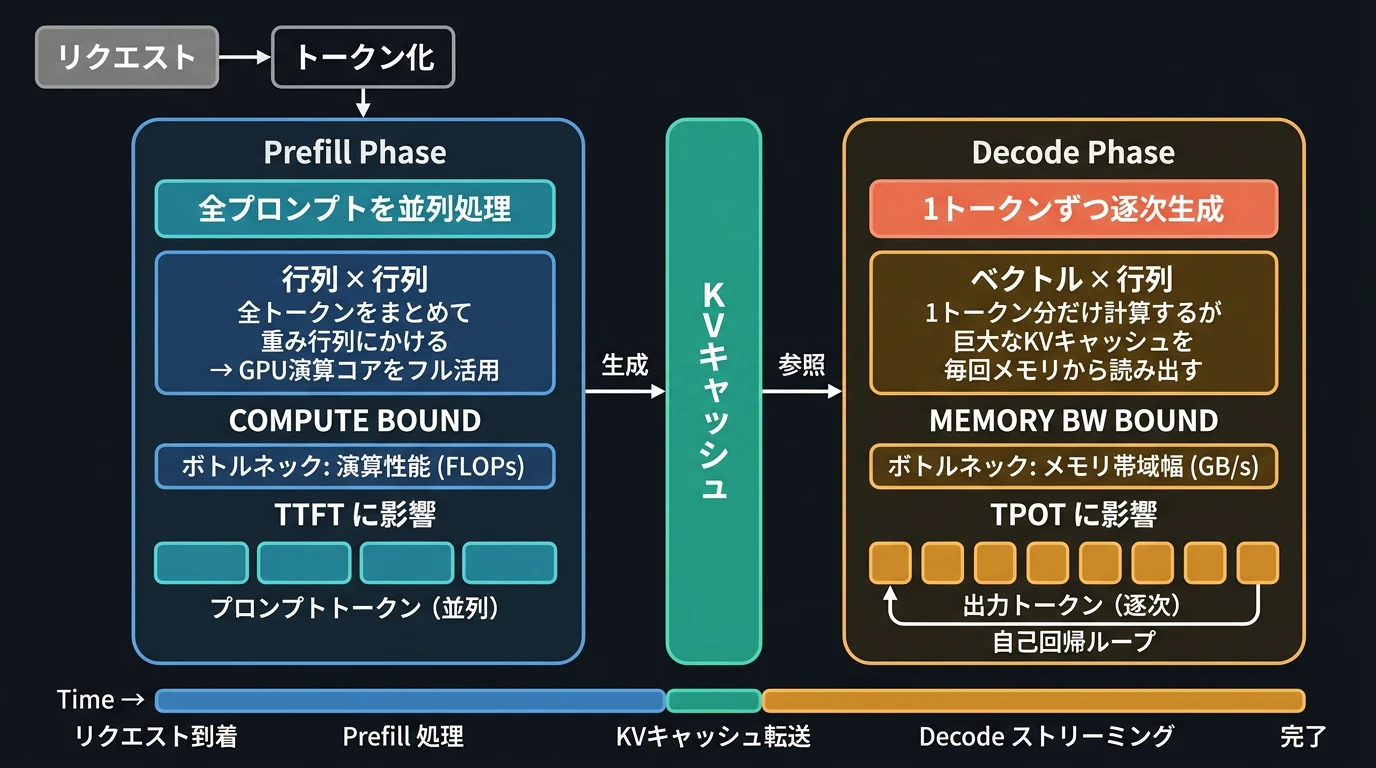
LLM(Transformer ベース)の推論は、大きく2つのフェーズに分かれます。
Prefill Phase
Prefill Phase は、入力プロンプト全体を並列に処理するフェーズです。全トークンをまとめて重み行列にかける「行列 × 行列」の演算が中心で、GPU の演算コアをフルに活用できます。このフェーズの所要時間が TTFT(Time To First Token:最初のトークンが返るまでの時間)を決定します。そしてこのフェーズで、後続の Decode Phase で使う KV キャッシュが生成されます。
Decode Phase
Decode Phase は、KV キャッシュを参照しながら1トークンずつ逐次的に出力を生成するフェーズです。演算自体は「ベクトル × 行列」と小規模ですが、生成済みの巨大な KV キャッシュを毎回メモリから読み出す必要があるため、GPU の演算性能ではなくメモリ帯域幅(GB/s)がボトルネックになります。1トークンあたりの生成時間が TPOT(Time Per Output Token)です。
KV キャッシュの再利用とルーティング
ここで重要なのは、Prefill Phase で生成された KV キャッシュは、同じ(または類似の)プロンプトを再度処理する際に再利用できるという点です。もしキャッシュが残っているバックエンドに同じリクエストを振り分けられれば、Prefill の再計算を大幅にスキップでき、TTFT が劇的に改善します。逆に、キャッシュのないバックエンドに振り分けてしまうと、毎回フルの Prefill が走り、GPU リソースと待ち時間の両方が無駄になります。
この「どのバックエンドにどの KV キャッシュがあるか」を意識してルーティングすることが、LLM 推論の効率化にとって極めて重要であり、それこそが SMG の KV-cache-aware load balancing が解決する課題です。
SMG が解決しようとしている課題
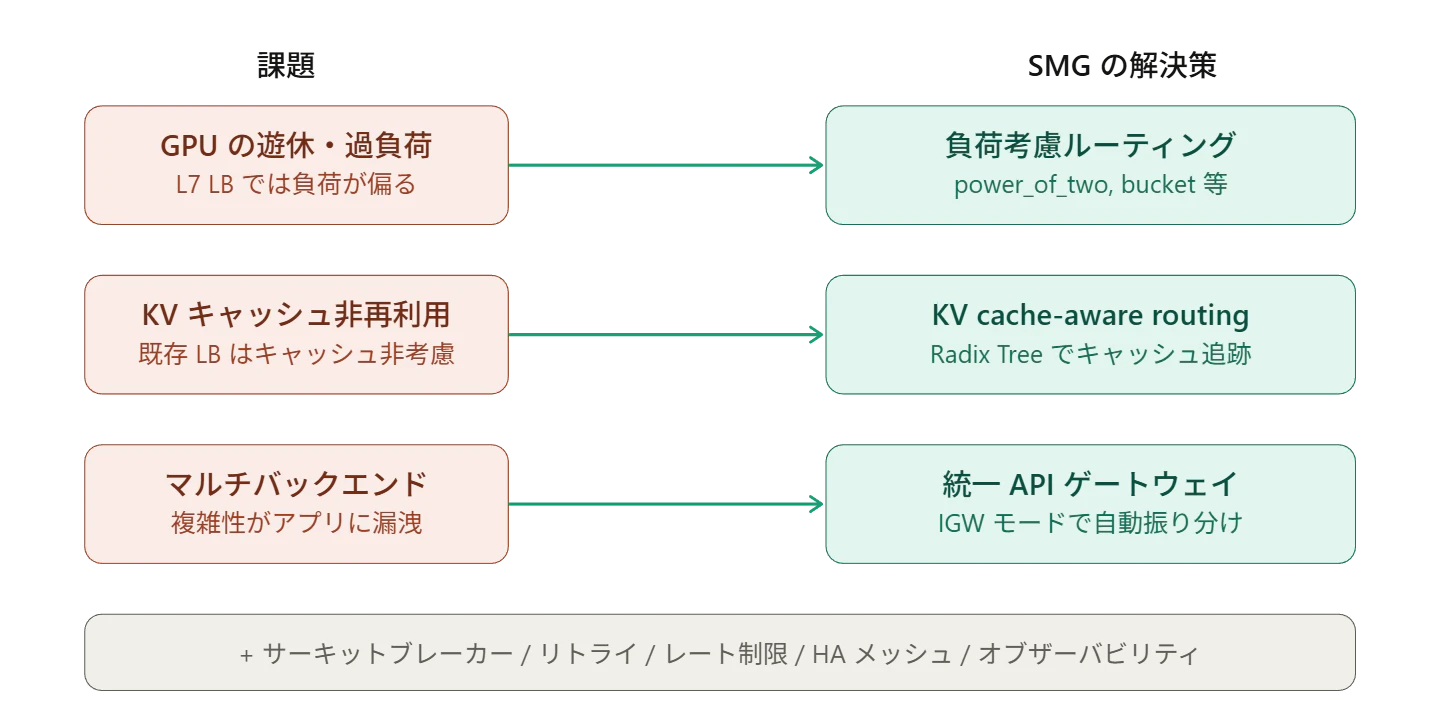
SMG が解決しようとしている課題は大きく3つあります。
第一に、LLM 推論はリクエストごとの計算量や生成長が大きくブレるため、一般的な L7 ロードバランシング(ラウンドロビン等)では GPU の遊休や過負荷が起きやすい点です。
第二に、推論では KV キャッシュ(過去トークンの計算結果)を再利用できるかどうかで処理時間が大きく変わるにもかかわらず、従来のルーティングは「どのバックエンドにどのキャッシュがあるか」を考慮できない点です。
第三に、本番ではコスト・レイテンシ・可用性・機能要件に応じて、複数の推論エンジンや複数の提供元(プロバイダー)を使い分けたい一方で、アプリケーション側に複雑さを押し付けると運用負荷と障害リスクが急増する点です。
SMG による解決
前節で挙げた3つの課題に対して、SMG はそれぞれ明確な解決策を持っています。
課題 1:GPU の遊休・過負荷 → 負荷考慮ルーティング
LLM 推論はリクエストごとに計算量が大きくブレるため、一般的な L7 ロードバランサ(ラウンドロビン等)では特定のワーカーに負荷が集中しやすく、他のワーカーの GPU が遊休する状況が生まれます。
SMG はバックエンドの負荷状態をリアルタイムに把握したうえでルーティングを行います。たとえば power_of_two ポリシーでは、ランダムに 2 台のワーカーを選んで負荷の軽い方に振り分けるという、シンプルながら統計的に効果の高い方式を採用しています。また、bucket ポリシーではリクエストの入力長に応じて振り分け先を変えることで、Prefill と Decode を別々のワーカーに分離する PD disaggregation 構成にも対応しています。
課題 2:KV キャッシュが再利用されない問題 → KV cache-aware routing
これが SMG の最も重要な差別化ポイントです。
前節で見たとおり、LLM 推論の Prefill Phase は入力全体の行列積を実行する重い処理です。しかし、同じ(または類似の)プロンプトを再度処理する場合、前回の Prefill で生成された KV キャッシュが残っていれば、この処理の大部分をスキップできます。つまり、KV キャッシュが残っているワーカーにリクエストを振り分けるだけで、TTFT を劇的に短縮できるのです。
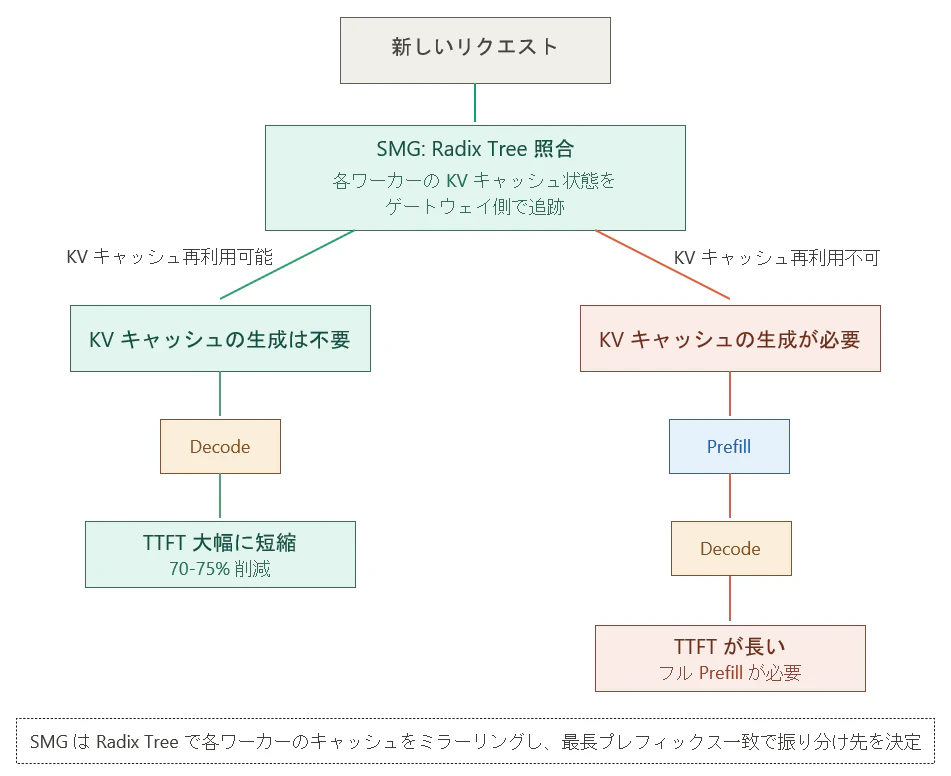
SMG の cache_aware ポリシーは、各ワーカーの KV キャッシュの内容をゲートウェイ側の Radix Tree(基数木)にミラーリングしています。新しいリクエストが来ると、そのプロンプトのトークン列を Radix Tree で照合し、最長プレフィックスが一致するキャッシュを持つワーカーを特定します。これにより 60〜90% のキャッシュヒット率を達成し、TTFT を 70〜75% 削減できるとされています。
負荷が偏っている場合には自動的にキャッシュアフィニティより負荷分散を優先するフォールバック機構も備えているため、キャッシュ最適化と負荷均衡のバランスが取れた動作をします。
マルチターン会話(2回目以降のやりとりで前回のコンテキストがキャッシュに残る)、RAG アプリケーション(共通のドキュメントプレフィックスを多くのリクエストが共有する)、バッチ処理(同じテンプレートで大量のリクエストを流す)など、プロンプトの先頭部分が繰り返し現れるワークロードで特に効果を発揮します。
課題 3:マルチバックエンドの複雑性 → 統一 API ゲートウェイ
本番環境ではコスト・レイテンシ・可用性の要件に応じて、セルフホストの推論エンジン(SGLang、vLLM、TensorRT-LLM)とクラウドプロバイダー(OpenAI、Anthropic、Gemini 等)を使い分けたいケースが多くあります。しかし、この振り分けロジックをアプリケーション側に持たせると、バックエンドの追加・変更のたびにアプリケーションの改修が必要になり、運用負荷と障害リスクが急増します。
SMG の IGW(Intelligent Gateway)モードは、リクエスト中のモデル名に応じて適切なバックエンドを自動選択します。アプリケーションから見れば単一の OpenAI 互換エンドポイントに対してリクエストを送るだけで、SMG がバックエンドの差異を吸収します。障害時のフェイルオーバーやキャパシティ逼迫時の退避先切り替えもゲートウェイ層で完結するため、アプリケーションはバックエンドの存在を意識する必要がありません。
SMG の主な機能
SMG はルーティングだけにとどまらず、LLM 推論を本番運用するうえで必要な機能を幅広く備えています。ここでは主な機能を整理します。
パフォーマンス
SMG は Rust で実装されており、gRPC パイプラインによるストリーミング処理、サブミリ秒(1ミリ秒未満)のルーティング判断、ゼロコピートークナイゼーション(トークン化時にデータの不要なコピーを発生させない手法)により、ゲートウェイ自身がボトルネックにならない設計になっています。
ルーティングポリシー
SMG には 8 種類のルーティングポリシーが用意されています。
本番環境で推奨されるのは cache_aware です。各バックエンドの KV キャッシュの状態をゲートウェイ側で追跡し、キャッシュが再利用できるバックエンドを優先的に選択します。キャッシュヒット率は 60〜90% を達成でき、TTFT を 70〜75% 削減できるとされています。負荷が偏った場合には自動的に負荷分散にフォールバックします。
その他のポリシーは用途に応じて選択します。power_of_two はランダムに 2 台のワーカーを選んで負荷の軽い方に振る、シンプルながら効果的な方式です。consistent_hashing は同じユーザーを同じワーカーに振り続けるセッションアフィニティ向け、bucket はリクエストの長さに応じて振り分ける PD disaggregation(Prefill と Decode を別ワーカーに分離する構成)向けです。ほかにも prefix_hash、manual、round_robin、random が揃っており、テスト環境からマルチターン会話、RAG アプリケーションまで幅広いワークロードに対応できます。
信頼性
本番運用で避けて通れないのが障害対応です。SMG はサーキットブレーカーにより、応答が返らないワーカーを自動的に切り離して障害の連鎖を防ぎます。一時的なエラーに対してはバックオフ付きリトライで自動回復を試み、レート制限によってバックエンドの過負荷を未然に防ぎます。
高可用性メッシュ
複数の SMG ノードを SWIM プロトコル(ゴシップベースのメンバーシッププロトコル)で接続し、ルーティング状態を共有するメッシュ構成をサポートしています。ノード障害時にはメッシュ内の別ノードが自動的に引き継ぐため、ゲートウェイ自体が単一障害点にならない構成が可能です。
マルチバックエンド対応
SMG は単一の API エンドポイントから、セルフホストの推論エンジン(SGLang、vLLM、TensorRT-LLM、Ollama など)とクラウドプロバイダー(OpenAI、Anthropic、Gemini、AWS Bedrock、Azure OpenAI)の両方にリクエストを振り分けられます。IGW(Intelligent Gateway)モードでは、リクエスト中のモデル名に応じて適切なバックエンドを自動選択します。たとえば model: "llama3" はセルフホストのワーカーへ、model: "gpt-4" は OpenAI API へルーティングされます。
エンタープライズ向け制御
マルチテナント環境向けに、OIDC(OpenID Connect)トークンによる認証とテナントごとのレート制限を提供します。また、WebAssembly(WASM)プラグインにより、リクエストやレスポンスに対するカスタムロジック(例:特定条件でのフィルタリングやヘッダ付与)をゲートウェイ内で実行できる拡張ポイントも備えています。
MCP 統合
Model Context Protocol(MCP)を介して外部ツールサーバーと連携できます。LLM の応答にツール呼び出しが含まれていた場合、SMG がそのツールを自動的に実行し、結果をモデルに返すループを処理します。これにより、アプリケーション側にツール実行のロジックを持たせる必要がなくなります。
チャット履歴の保存
会話履歴のストレージとして PostgreSQL、Oracle、Redis、またはインメモリを選択できるプラガブルな設計です。チャット履歴をゲートウェイ側で管理することで、アプリケーションは状態を持たずに済み、マルチターン会話のコンテキスト管理が簡素化されます。
オブザーバビリティ
40 以上の Prometheus メトリクス(リクエスト数、レイテンシ、キャッシュヒット率、トークン数、ワーカーの健全性など)、OpenTelemetry によるリクエスト相関トレーシング、構造化 JSON ログを提供します。ゲートウェイからバックエンドまで、各レイヤーで何が起きているかを詳細に把握できます。
まとめ
要するに SMG は、「LLM 推論をクラウド規模で速く・安定に・無駄なく回す」ための賢い交通整理役です。LLM 本番運用で起きがちな、GPU の偏り・待ち行列の肥大化・キャッシュ不活用・バックエンド多様化による複雑性を、ゲートウェイ層で吸収し、アプリケーションはシンプルな呼び出しのまま高い性能と信頼性を得ることができます。それが Shepherd Model Gateway の価値です。