はじめに
ネットの数多あるコードを眺めたり、文献を読みながら、自分自身でA3Cの再現を試みたところ、落とし穴が多すぎて闇が深いと感じたので、そんな闇にはまるのは自分で最後にするため、ハマったところをTipsという形でまとめてみました
これから自分でコード書いて頑張ってみようと思っている方はこれをみて少しでも闇にはまらないことを願っています
A3Cってなに
A3CはAsynchronous Advantage Actor-Criticの略で、2016年にあのDQNでおなじみのDeepMind社が発表した、
- 早い:AsynchronousかつAdvantageを使って学習させるので、学習が早く進む!
- 安い:DeepLearningといえばGPUという常識を覆して、安価なCPUだけで計算ができる!
- うまい:DQN(やその他の比較手法)より性能がいい!
の三拍子が揃った牛丼のような深層強化学習手法です
一言でいうと、DQNはもう古くて、A3Cのが新しくてより優れている手法です(絶対とは言わないけど基本的に)
こんな感じ↓

Asynchronous
DQNでは、一つのエージェントが行動して得た経験を(オンラインだと経験がiidにならないので)ランダムにサンプリングして、学習データとして使っていました。一つのエージェントの経験しか利用しないため、学習サンプルが集まるスピードが遅かったり、経験を一旦ReplayMemoryという形で蓄積してから学習していたので、LSTMなどの時系列データからの学習がやりにくいといった問題が有りました
そこで、A3CのAsynchronousの部分では、エージェントを複数(論文ではMax 16)同時に動かし、個々の経験を集めて学習させることで、全体の経験としてはランダムにサンプリングされている状態にし、オンラインで学習させられるようにしています
また、同時にたくさんの経験が得られるので、その分だけ学習が早く進められるようにもなりました
Advantage
通常のTD学習では、行動した結果得られた報酬$r$と次状態の価値の推定値$V(s_{t+1})$(を割引率$\gamma$で割り引いたもの)の和と、現状態の価値の推定値の差$\Delta$を使って、状態の価値を更新していきます
$$
{\begin{align}
\Delta = r + \gamma V(s_{t+1}) - V(s_t)
\end{align}}
$$
逆に言えば、次の状態の推定値が正しくないと、そもそも現状態の推定値が正しく更新されません
さらに、次の状態の推定値はそのさらに次の推定値が正しくなければならず、そのさらに次の状態の推定値は...と連鎖的になっているので、1ステップ先しかみないこの更新方法は、正しい値に収束するのに時間がかかることが予想されます
そこで、A3Cでは、オンライン、すなわち時系列データを使って学習できるという利点を活かして、次の、Advantageと呼ばれる量を使って推定値を更新していきます
$$
{\begin{align}
kstep &= \sum_{i=0}^{k-1}\gamma^ir_{t+i} + \gamma^k V(s_{t+k}) \\
advantage &= kstep - V(s_t)
\end{align}}
$$
ここで、$k$はどれだけ先読みを行うかを表す定数です。
強化学習の価値推定において一番確からしい情報は実際に得られた報酬$r$なので、Advantageという量は、1ステップ先ではなく、kステップ先の報酬まで考慮した、より確からしい現状態の価値の推定誤差といえます
A3Cはこの量を使って学習を行うことで、
- より確からしい値なので、学習が早く進む
- 数ステップ先まで考慮しているので、1ステップ先しか見ない場合より学習が早く進む
の2点を期待して学習がより効率的に行えるようにした手法と考えられます
Actor-Critic
DQNではQ値と呼ばれる、ある状態$s$で行動$a$を行う価値の推定値を学習させていました
ある状態における行動の価値を推定するので、行動が連続的な場合(例:モーターの回転速度を学習させたいとき)は、推定しなければならない組み合わせが膨大になってしまう問題がありました
Actor-Criticはある状態で起こす行動の確率$\pi$と、状態の価値の推定値$V$をそれぞれ独立に推定しながら学習を行う強化学習手法で、推定値が独立していることで、行動が連続的な場合でも学習させやすいという特徴があります
A3Cそのものの性能にどれほど、Actor-Criticであることが寄与しているかはわかりませんが、上記のような特徴があるため、Actor-Criticを採用したA3Cは、離散的、連続的いずれの方策も学習させることができ、汎用的になっているといえます
挫折しないための7Tips
前置きが長くなりました
A3Cの実装自体は下記のGitHubリポジトリ等を筆頭に参考にできるものはたくさんあるので
ここからは、A3Cをどのように実装するか細かい話はさておき、まるまるパクってくるのではなく、ある程度自分でコードを書きたい、書いた、もしくは書こうと思っている人向けに、実装したけどなんか学習が進まない、学習進むけど論文の結果と全然違うといったときに、気をつけたり、確認したりするべきポイントを、自分がハマった落とし穴兼Tipsとして紹介します
落とし穴/Tips その1 Hyperparameterが謎
実装を進めていくと、途中でRMSPropのパラメータしかり、学習率の減衰のさせ方しかり、よくわからないところが出てきます
幸い先人たちによって、どんなパラメータにすべきかはすでに公開されているので、自分でハイパーパラメータを探ったり、変に悩むのはやめましょう
落とし穴/Tips その2 自動微分の罠
論文に書かれているA3Cの実装の説明に以下の2行があります
$$
{\begin{align}
&\theta' : d\theta \leftarrow d\theta + \nabla_{\theta'} \log\pi(a_i|s_i;\theta')\bigl(R-V(s_i;\theta_v')\bigr) \\
&\theta_v' : d\theta_v \leftarrow d\theta_v + \partial\bigl(R-V(s_i;\theta_v')\bigr)^2/\partial{\theta_v'}
\end{align}}
$$
別に何も間違ってはいないのですが、Atari再現用ネットワークは途中2又に分かれて、パラメータを一部共有するネットワークのため、$\theta' : d\theta \leftarrow d\theta + \nabla_{\theta'} \log\pi(a_i|s_i;\theta')\bigl(R-V(s_i;\theta_v')\bigr)$は、そのまま実装してしまうと、$V(s_i;\theta_v')$の部分は本来$\theta'$の関数ではないので、tensorflowの場合、$V(s_i;\theta_v')$はスカラー値を与えないと、自動微分された結果、勾配の計算がおかしくなります
落とし穴/Tips その3 OpenCV2劇遅問題
もし、画像のグレースケール化や画像表示等でOpenCVを使っていたら、OpenCV3を使っていることを確認したほうが良いです
自分は気づかずなんかOpenCVがボトルネックっぽいなぁと思ってたら、OpenCV2を使ってて、OpenCV3にしたら数倍実行速度が上がりました
落とし穴/Tips その4 Arcade Learning Environmentがマルチスレッド非サポート問題
マルチプロセスで実装するのであれば、問題にはならないですが、マルチスレッドで実装する場合は、考えなくてはいけません
ただ対策しなかったから、全然動かないのかというとそうでもなく、かといって抜本的な解決方法はどうもなく、たぶんこれで大丈夫だろう的な気休めの対症療法しか自分の知る限りありません
miyosuda/async_deep_reinforceにもありますが、arcade learning environmentのソースコードを少しいじって、staticな変数をstaticじゃなくしておくと言ったような修正が有効のようです
しかし、それでも自分が試した範囲ではときどき変な状態になるようで(というのも自分のコードがバグってるのか、ALEがバグってるのか正直わからないため)、後は運と言った感じです
それから、arcade learning environmentのコードは最新のmasterよりも、v0.5.1のコードを修正するほうが安定感があるように自分の環境では感じました(気のせいかもしれないですが・・・参考まで)
落とし穴/Tips その5 画像のPreprocessingで、0-1の範囲にscaleを変換する
aleから得られるグレースケール画像は0-255の範囲なのですが、自分が実験した感じだと、255で割って、全体のスケールを0-1の範囲に変更したほうが性能が上がるっぽいです(上がるだけで、255で割らないと学習しないわけではないところが難しいところ)
落とし穴/Tips その6 論文に忠実に実装する
そんなの当たり前だろ!と怒られてしまいそうですが、論文に忠実に実装するべきだと自戒の念をこめてここに書いておきます
特に気をつけなければならないのがadvantageのstep数で、上にも書いた通りadvantageは先読みするので、理論的にはたくさん先読みできたほうが結果は良さそうに思え、じゃあ論文の5なんかじゃなくて、10とか20とかもっと大きい数字のほうがいいんじゃない?DeepMindってアホなの?俺天才!とか思いたくなります
これは学習させたいゲームの報酬の与えられ方と、Actor-Criticという学習手法に起因した問題だと思いますが、自分の試したBreakoutのゲームでは$t_{max}=5$でないと、途中まで論文以上に早く学習が進み、いい感じだと思った辺り(13Mstep辺り)で学習がおかしくなり、ネットワークが壊れ、その後復帰しないといった症状が見られました
一方、Pongでは20にしてもうまくいくようですので、このstep数は単純に増やせば良いってものでもなく、慎重に選ばないといけないということ、そして再現させるのであれば、オレオレ変更は再現後にやるべきということです
落とし穴/Tips その7 Gradient Ascentになってるかどうか確認する
今回の手法では報酬が大きくなる方向かつエントロピーが大きくなる方向にpolicyネットワークの勾配を修正しないと行けないので、GradientDescentではなく、Ascentになるように、負号をLossにつけないと計算がおかしくなります
tensorflowの場合、下記のような感じになります
policy_loss = - tf.reduce_sum(log_pi_a_s * advantage) - entropy * self.beta #こっちは値が大きくなる方向に変化させたいので、両方マイナスをつける
value_loss = tf.nn.l2_loss(self.reward_input - self.value) #こっちは推定値との誤差を小さくしたいのでそのまま
落とし穴/Tips 番外編 Global Interpreter Lockは気にしなくて良いの?
気にしたほうが良いですが、どのライブラリを使うかとどこまで高速に実行させたいかによります。
少なくとも、TensorflowはGILの問題を比較的意識して実装されているらしく、自分のところではRyzen7 1800Xの環境下で大体2Mstep/hourくらい出てました
2Mstep/hourだと大体論文に書いてある80MStepまで、40時間くらいかかります。
ほぼfull-pythonのChainerなんかはGILを意識してmultiprocessingで実装しないとだめっぽいです
おわりに
自分が再現するにあたって書いたコードはGitHub(LSTM版はまだ)に上げてあるので、参考にどうぞ
学習結果も あとで載せる予定です 載せました
学習結果
Ryzen 1800X(本当は16ThreadでやりたかったけどKernel的に対応してなかったので8)で40時間位かけたときのデータがこちら
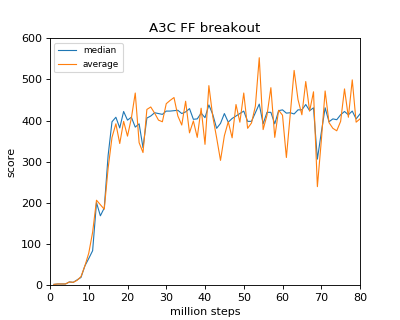
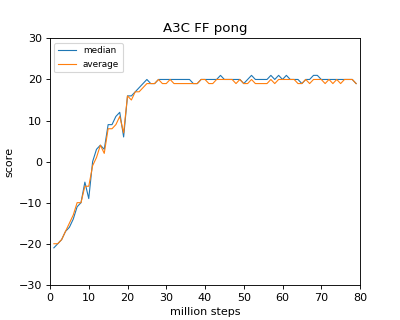
自分が論文を読んだ限り、Breakout/Pongに関しては同じ結果が得られていそうです
Breakout/Pongの場合はわりと早い段階(20 million step)でほぼ収束するようです
参考文献
Asynchronous Methods for Deep Reinforcement Learning
Reinforcement learning in continuous time: advantage updating