GunosyDM研究会 #90の発表資料です
紹介する論文
[1404.5772]Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks
MSRAでのインターンでの成果のようで,最初の3人がインターン生かな.
Introduction
検索連動型広告のクリックのされやすさを機械学習を使って予測する.
その素性として使われる代表的なものは以下の2つ
- 過去のCTR(query別, ユーザ別などなど)
- クエリと広告の意味的な近さ
この研究ではもっといろんなデータを組み合わせて予測をする
例えばあるユーザが広告をクリックしたけどすぐ閉じた場合には,次にその広告をみたときクリックする確率は低くなるだろう、みたいなことを予測をしたい
この研究ではRecurrent Neural Network(RNN)を用いてクリック確率を予測する
データは時系列データなので時系列解析を用いるのが適当
一般に時系列解析はトレンドだったり周期パターンのモデリングが主だが,
広告データは複雑で動的なので適さない.
RNNは近年様々な系列データに対するタスクで優秀な成果を上げている.
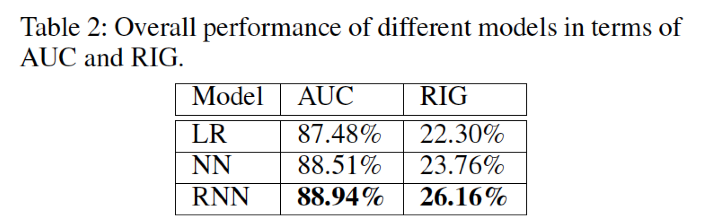
RNNを用いたモデルによって従来のLRやNNによる手法に対して高い改善を示した
重要なのは予測タスクにsequential dependencyを取り入れること.
Data Analysis on Sequential Dependency
最初にクリックした時のランディングページ(LP)の滞在時間と次のimpの時のクリック率
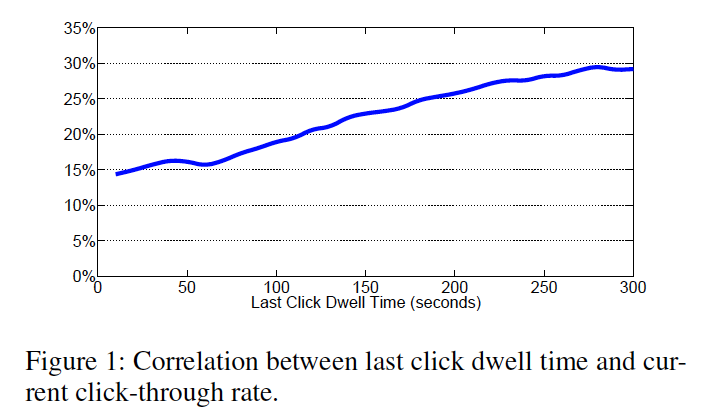
quick backから経過した時間とCTR
quick back: ユーザがLPから20秒以内に戻ったこと
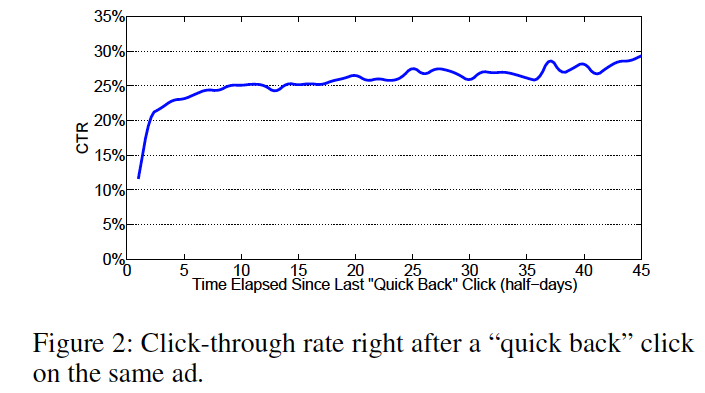
ユーザは時間がたつとunsatisfiedな体験を忘れる
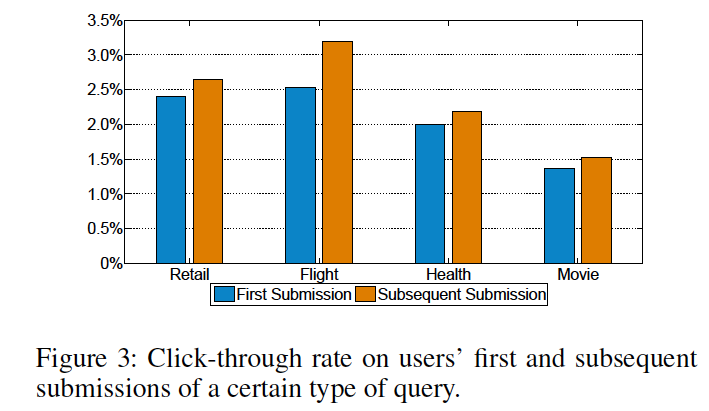
最初に検索したときと次に検索した時のCTR
The Proposed Framework
Model
特に変わったところないRNN
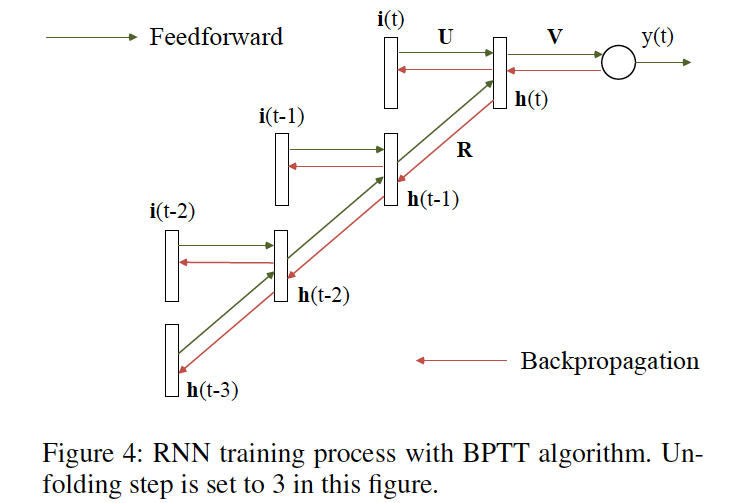
h(t) = f(i(t)U^T + h(t-1)R^T) \\
y(t) = \sigma(h(t)V^T)
f(z) = tanh(z) =\frac{1-e^{-2z}}{1+e^{-2z}} \\
\sigma(z) = sigmoid(z) = \frac{1}{1+e^{-z}}
Feature Construction
たくさんつかってる.細かく具体的には述べられていない.3つのグループに分けている.
- Ad features consist of information about ad ID, ad display position, ad text relevance with text
- User features include user Ud and query related semantic information
- sequential features include time interval since the last impression, dwell time on the landing page of the last click event, and whether the current impression is the head of sequence
同じセッションで表示された広告は表示順によってsequenceにする
Learning
Loss function
averaged cross entropy
L = \frac{1}{M} \sum_{i=1}^M (-y_i log(p_i) - (1-y_i)log(1-p_i))
$ M $: 訓練データ数
$ y_i $: クリックしたかのラベル$ {0, 1}$で表現される
$ p_i $: 予測したクリック確率
学習にはBPTTに用いる
Experiments
Data Setting
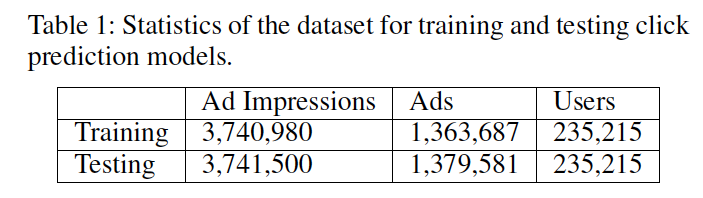
商用検索エンジンのログ, 2013/11/9 - 2013/11/22からランダムにサンプリング
第1週のデータを訓練データ, 第2週のデータをテストデータ
Evaluation Metrics
- Area Under ROC Curve(AUC)
- Relative Information Gain(RIG)
Compared Methods
- Logistic Regression(LR)
- Neural Network(NN)
Experiment result
overall perfomance
grid search
- the coefficient of L2 penalty: 1e-6
- the number of training epochs: 3
- the hidden layer size: 13
- the number of unfolding steps for RNN: 3
Performance on Specific Ad Positions
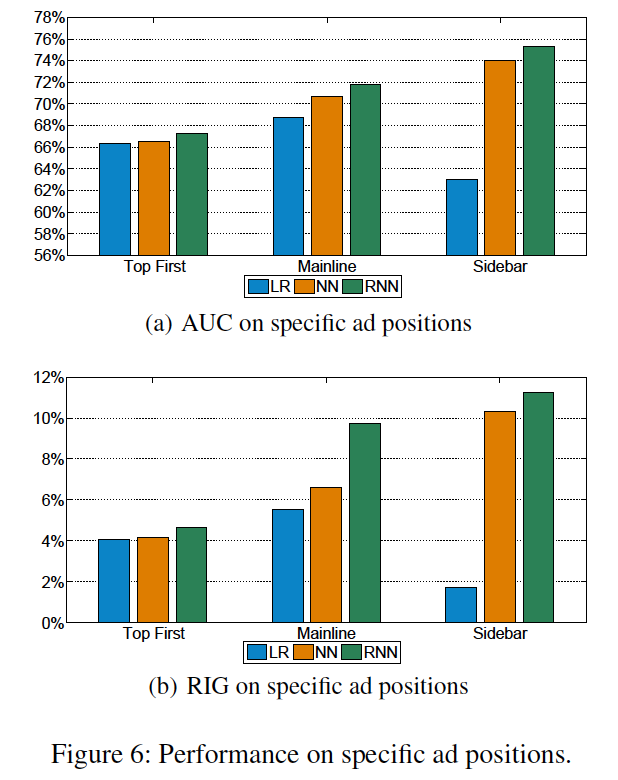
- mainlineが一番収益を生むのでRNNがこちらで高いのは良い
- sidebarはクリック数が少ないのでrareケースに過剰反応するためLRは低くなる
Effect of Recurrent State for Inference
RNNとして学習したあとに通常のNNとして推定する
つまり前の系列データの隠れ層の値を使わない状態にする
AUC: 88.25%
RIG: 18.95%
Table2と比較して性能が劣化している.
recurrent structureが推定に対して有効に働いているといえる.
Performance with Long vs. Short History
しきい値T以上のsequenceをもつデータを集め, Tで隠れ層にデータをためて残りでtestを行う.
Tの長さに対してRNNがrobustであるかを確認する
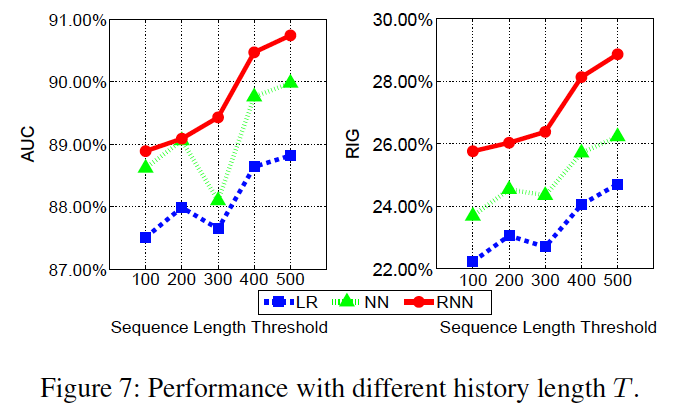
Tが大きいほどperformanceがよい.系列データの特徴をよく蓄積できているといえる
Effect of RNN Unfolding Step
Unfolding Step: BPTTにおける学習のステップ数
(BPTTよくわかってないので今度ちゃんと調べる)
AUC, RIGのベストは3,それより大きな値にすると数値は落ちていく(3までは上昇する)
3より大きい値にしたときは逆伝搬のエラーが消える
これからこのモデルは系列データを以下のように扱っていると推測できる
- short-span dependency: 少ない単位で明示的に学習している
- long-span dependency: 暗黙的に長いデータをreccurentな構造に貯めこんで精度を高めている
Future Work
- 今回はユーザレベルのsequential dataを扱ったけど(user, ad)とか(user, query)などより多様な形で学習させたい
- 今回学んだrecurrentな部分の特徴を活かして,より最適化した形で扱いたい
- Deep Recurrent Neural Network(DRNN)[Hermans+2013]を試してみたい
感想
- シンプルなRNNでここまで改善するのすごい(ほんとかよって気持ちにもなる)
- feature全然隠してるけどこういうのでも論文として成立するものなのかな
- 素性がsequentialなところに依存しすぎていたのではみたいな懸念もありそうな
- こういうタスクいろいろあると思うのでいろいろ試してみたいところ
- RNNの特性についての分析が深くて参考になった.