モチベーション
『ナウなヤングはググって調べ物しない。SNS(TwitterやInstagramなど)を検索して調べる』という記事が興味深かったので、SNSの画像を扱ったネタをやってみたいと思っていた
参考記事
やったこと
1.「ゴールデンウィーク」という単語が含まれるツイート(と添付された画像)をTwitter APIでたくさん取得する
2. 収集した添付画像をGoogle Cloud Vision APIに突っ込んで何が映っているのがラベル付けして集計する
3. 日本人ツイッタラーの連休の過ごし方を妄想する
〜当初の予想〜
きっとみんなこういうゴールデンウィークを過ごしてるんでしょ?(「リア充 写真」で検索)


- 準備
それぞれのAPIについてざっくり調べる
1-1. Twitter APIでできること
| # | APIの種類 | 説明 | 制限 | 今回 |
|---|---|---|---|---|
| 1 | REST API | ・過去のツイートを取得する | ・直近1週間分のツイートしか取得できない ・180 requests/15min(180 tweetではない) |
◀こちらを利用 |
| 2 | Streaming API | ・ツイートの(ほぼ)リアルタイム取得 例:選挙番組中に「#総選挙」ハッシュタグのツイートを取得しつづける ・リアルタイム全てのツイートではなく、公開ツイートのうちの1%程度を取得する |
・特に無し(?) |
1-2. Google Cloud Vision APIでできること
- googleが提供するAPI利用にはGoogle Cloud Platform (GCP)への事前登録が必要。Cloud Vision API(以下 Vision API)もGCPが提供するAPIのうちの一つという位置づけ
- 初回利用は60日間無料。以後課金が発生する
- 無料期間内の利用であっても初期登録時に強制的にクレジットカードの登録が義務付けられている(意図しない課金発生が怖い場合、課金発生時にアラートメールを飛ばすこともできるので一応安心)
- 日本でも導入企業事例がいろいろあるらしい
| # | VisionAPIの種類 | 説明 | 制限 | 今回 |
|---|---|---|---|---|
| 1 | 顔認証 FaceDetection | ・人の顔が写っている写真から顔の部分の座標を取り出す ・感情を分析する ("笑顔"とか、"めっちゃ笑顔"とか) 
|
? | |
| 2 | タグ付け LabelDetection | ・写っているものが何なのかをタグ付ける ・付けるタグは1つでなく、Probabilityを併記する形で複数のタグを返す 
|
・無料利用は1000 pics/month ・それ以降のお値段はこちら |
◀こちらを利用 |
| その他 | ・観光名所などの名前 LANDMARK_DETECTION ・ロゴの検出 LOGO_DETECTION ・文字の検出 TEXT_DETECTION ・有害コンテンツの検出 SAFE_SEARCH_DETECTION ・色データ検出 IMAGE_PROPERTIES |
・楽しそう(触ってない) | ? |
1-3. Vision API利用までの道のり
例によって大分苦労したのでメモ。Vision APIに関しては社内勉強会で@hik0107さんが書かれた先行記事を大いに参考にしました。
| 順番 | やること | 補足 |
|:--|:--|:--|:--|:--|
|1|GCP のアカウントを登録する|・60日間無料
・クレカ登録必須(無料枠内であれば課金は発生しない)|
|2|Vision APIを有効にする|・登録したGCPの自分のアカウントのコンソールから簡単に出来る
・Cloud Vision APIは1000リクエスト/月(1000枚の画像のタグ付け)までは無料
・この記事の序盤あたりを参考にすればok|
|3|API Keyを入手する|・GCPの自分のアカウントのコンソールから取得
・この記事を参考にすればよいが、今回必要なkeyはAPIキーの「サーバーキー」を選択して取得する|
|4|Google Cloud Platform SDKをインストールする|・APIキー以外にも認証に必要らしい
・APIを叩くマシンに入れておく
・基本的にはコチラの記事を参考にすればok(gcloud auth listの表示まで確認できればひとまずok。sshの設定とか今回は必要なし)|
- 実践
2-1. 「ゴールデンウィーク」という単語が含まれるツイート(と添付された画像)をTwitter APIで取得 (Python2で実行)
コードは@kenmatsu4さんの記事を参考にさせてもらいました
# -*- coding: utf-8 -*-
from requests_oauthlib import OAuth1Session
from requests.exceptions import ConnectionError, ReadTimeout, SSLError
import json, datetime, time, pytz, re, sys,traceback
from collections import defaultdict
import numpy as np
# import pprint
KEYS = { # 自分のアカウントで入手したキーを下記に記載
'consumer_key':'xxxxxxx',
'consumer_secret':'xxxxxxx',
'access_token':'xxxxxxx',
'access_secret':'xxxxxxx'
}
twitter = None
connect = None
db = None
tweetdata = None
meta = None
'''
Twitter接続情報の初期化
'''
def initialize():
global twitter, twitter, connect, db, tweetdata, meta
twitter = OAuth1Session(KEYS['consumer_key'],KEYS['consumer_secret'],
KEYS['access_token'],KEYS['access_secret'])
initialize()
'''
検索ワードを指定して100件のTweetデータをTwitter REST APIsから取得する
'''
def getTweetData(search_word, max_id, since_id):
global twitter
url = 'https://api.twitter.com/1.1/search/tweets.json'
params = {'q': search_word,
'count':'100',
}
# max_idの指定があれば設定する
if max_id != -1:
params['max_id'] = max_id
# since_idの指定があれば設定する
if since_id != -1:
params['since_id'] = since_id
req = twitter.get(url, params = params) # Tweetデータの取得
# 取得したデータの分解
if req.status_code == 200: # 取得に成功した場合
timeline = json.loads(req.text)
metadata = timeline['search_metadata']
statuses = timeline['statuses']
limit = req.headers['x-rate-limit-remaining'] if 'x-rate-limit-remaining' in req.headers else 0
reset = req.headers['x-rate-limit-reset'] if 'x-rate-limit-reset' in req.headers else 0
return {"result":True, "metadata":metadata,"statuses":statuses,"limit":limit,"reset_time":datetime.datetime.fromtimestamp(float(reset)), "reset_time_unix":reset}
else: # 失敗した場合
print ("Error: %d" % req.status_code)
return{"result":False, "status_code":req.status_code}
# 文字列を日本時間2タイムゾーンを合わせた日付型で返す
def str_to_date_jp(str_date):
dts = datetime.datetime.strptime(str_date,'%a %b %d %H:%M:%S +0000 %Y')
return pytz.utc.localize(dts).astimezone(pytz.timezone('Asia/Tokyo'))
# 現在時刻をUNIX Timeで返す
def now_unix_time():
return time.mktime(datetime.datetime.now().timetuple())
'''
ループさせて制限いっぱいまでツイートデータを取得する
'''
sid=-1
mid = -1
count = 0
res = None
while(True):
try:
count = count + 1
print '-----------------------count',count
res = getTweetData(u'ゴールデンウィーク',max_id=mid,since_id=sid)
# tweet取得に失敗したら終了する
if res['result']==False:
print "status_code", res['status_code']
break
if int(res['limit']) == 0: # 回数制限に達したので休憩
# 待ち時間の計算. リミット+5秒後に再開する
diff_sec = int(res['reset_time_unix']) - now_unix_time()
#print "sleep %d sec." % (diff_sec+5)
if diff_sec > 0:
time.sleep(diff_sec + 5)
else:
# metadataの処理
if len(res['statuses'])==0:
sys.stdout.write("statuses is none. ")
elif 'next_results' in res['metadata']:
tweets = res['statuses']
for tweet in tweets:
if tweet['lang']=='ja': #取得対象を日本語tweetに限定
pattern = r'^RT'
pattern2 = r'^@'
match_text = re.search(pattern,tweet['text'])
match_text2 = re.search(pattern2,tweet['text'])
if not match_text: # リツイートは取得対象から除く
if not match_text2: # リプライも取得対象から除く
if 'media' in tweet['entities']:
media = tweet['entities']['media']
for urls in media: #リストの中の辞書を展開
media_url = urls['media_url']
twitter_img_pattern = r'.+?/pbs.twimg.com/media/.+?' #ツイッターデフォルトの写真アップロードurlに限定
match_img_pattern = re.search(twitter_img__pattern,media_url)
if match_img_pattern:
screen_name = '@' + tweet['user']['screen_name']
ja_time = str_to_date_jp(tweet['created_at'])
text = tweet['text'].replace('\n','')
encode_text = text.encode('utf_8')
if not tweet['geo'] == None:
geo = tweet['geo']['coordinates']
result = "%s;%s;%s;%s;%s" % (screen_name,ja_time,media_url,geo,text)
encoding_result = result.encode('utf_8')
print encoding_result
else:
result = "%s;%s;%s;%s;%s" % (screen_name,ja_time,media_url,tweet['geo'],text)
encoding_result = result.encode('utf_8')
print encoding_result
'''
過去に遡ってツイートを取得するための処理
'''
# 同じ検索ワードでこれよりも古いツイートを取得したいときのURLをnext_urlから取得
next_url = res['metadata']['next_results']
# 今回のループでゲットした一番古いツイートIDを取得
pattern = r".*max_id=([0-9]*)\&.*"
ite = re.finditer(pattern, next_url)
for i in ite:
mid = i.group(1) # midに代入することで,次のループはこのIDよりも古いツイートを取ってくるようにする
break
else:
sys.stdout.write("next is none. finished.")
break
except SSLError as (errno, request):
print "SSLError({0}): {1}".format(errno, strerror)
print "waiting 5mins"
time.sleep(5*60)
except ConnectionError as (errno, request):
print "ConnectionError({0}): {1}".format(errno, strerror)
print "waiting 5mins"
time.sleep(5*60)
except ReadTimeout as (errno, request):
print "ReadTimeout({0}): {1}".format(errno, strerror)
print "waiting 5mins"
time.sleep(5*60)
except:
print "Unexpected error:", sys.exc_info()[0]
traceback.format_exc(sys.exc_info()[2])
raise
finally:
info = sys.exc_info()
本当は取得したツイートをDBに入れていくと良いのだろうけど、今回は期間的にもツイート量的にも大したことないので全部テキストファイルとして吐かせる
$ nohup python twitterRESTapi.py > GWtweets.txt &
上記のPythonコードを回したままツイートが貯まるのをしばらく待つ。
我が家には起動しっぱなしのデスクトップPCなど無いので、小型省電力でお馴染みのRaspberry Piでコードを実行し放置。(といいつつ、今回取得したデータ量くらいなら6時間ほど?で取得可能でした)
#### 2-1-1. Twitter REST APIで取得したデータ概要
■ツイート数
23,299 tweets(uniq user count:23,235 user)
※ 日本語ツイートに限定。リプライ、リツイートも含まない
※ ツイート中に「ゴールデンウィーク」という単語を含むツイートに限定
※ 画像が添付されたツイートに限定しているため 23,299 tweets = 23,299枚の画像を取得
■期間
2016-05-04 (Wed) 05:30:35 〜 2016-05-08 (Sun) 12:16:13
→「status code 500 Internal Server Error(Twitterの故障が起こっている)」「503 Service Unavailable(Twitterサーバーが高負荷状態)」でちょいちょい止まる。こんなものか...
■取得したツイートの内、位置情報を含むもの
34 tweets (0.15% of acquired tweets)
→ 他の人がやった場合でも位置情報付きtweet数は0.3%だったそうなのでこんなもんかも
→ 位置情報のマッピングもしたかったが数が少ないので断念
#### 2-1-2. こんな感じのデータが出来た
データの並びは以下
アカウント名; ツイートされたdatetime; 添付画像のfull url; 緯度経度情報; ツイート分
-----------------------count 1
@melanzane_;2016-05-08 11:15:46+09:00;http://pbs.twimg.com/media/Ch5mR6nUYAAaF5K.jpg;None;ゴールデンウィーク最終日は日曜日。国分寺イタリアンレストラン、メランツァーネでは、日曜日のランチタイムに手作りデザートをサービスしてます。今週はオレンジのババロアです。ご来店お待ちして、開店です。 https://t.co/ukjqvzY9G4
@hii_sanpo;2016-05-08 11:15:18+09:00;http://pbs.twimg.com/media/Ch5mKhoVIAA5or6.jpg;None;朝兼お昼ごはんトマト、蒸し茄子野菜炒め(大根、人参、キャベツ、鶏挽肉、キムチ、卸生姜)蒟蒻素麺16kcal(+長芋オクラ昆布、烏賊鮭)八朔半分、夏蜜柑1つゴールデンウィーク最終日。のんびり過ごします〜 https://t.co/pgncens0Ck
@kobamiki362;2016-05-08 11:15:10+09:00;http://pbs.twimg.com/media/Ch5mJslU4AA8yGr.jpg;None;快晴のゴールデンウィーク最終日、横浜港で飛鳥2とコスタビクトリアが仲良くツーショット(^_^)vお名残惜しいですが、旅は終わりです https://t.co/1ThqisoJiM
@AkibaDailyNewsM;2016-05-08 11:15:05+09:00;http://pbs.twimg.com/media/Ch5mGuiUkAIuq56.jpg;None;ジャンカレーのゴールデンウィーク期間限定カレーは今日が最終日。 https://t.co/guYMRvOEDu
@splatoonantena;2016-05-08 11:15:03+09:00;http://pbs.twimg.com/media/Ch5mH-jWwAMSPRf.jpg;None;【スプラトゥーン】ゴールデンウィークで一番わろた【スプラトゥーン 完全攻略】https://t.co/ppA3khbJVY #スプラトゥーン https://t.co/yIYYzlRptE
@trnd76;2016-05-08 11:14:51+09:00;http://pbs.twimg.com/media/Ch5mE9fUoAA2nJu.jpg;None;【悲報】 ゴールデンウィークが明けたら「68日間」祝日なし https://t.co/Vq7Ftq1Y6W https://t.co/6UWTQ0FxBo
@Chikuwa4;2016-05-08 11:14:49+09:00;http://pbs.twimg.com/media/Ch5mDLDUYAEV5wn.jpg;None;ゴールデンウィーク最終日、富山に向けて出発〜! https://t.co/B9xLH2hguD
-----------------------count 2
@na_chu_009;2016-05-08 11:14:43+09:00;http://pbs.twimg.com/media/Ch5mClnUgAcUYsw.jpg;None;ゴールデンウィーク終わっちゃうっっっ!!!!行くなーーーーーーーーっっっ!!!!!!!😭😭😭 https://t.co/5eyXv1nC3x
(続く)
この後、Vison APIに上記のデータの画像URL部分だけをインプットデータとして利用するため、先に切り出して準備しておく
$ grep "@" GWtweets.txt | cut -f 3 -d ";" > GWtweets_pics.txt
2-2. 収集した添付画像をGoogle Cloud Vision APIに渡して何が映っているのがラベル付けする
Vision APIのコードを実行する前に、先に以下のコマンドをCloud SDKをインストールしたPCのターミナル上で実行し、認証(?)的なことを行う
参考: http://qiita.com/kosuke_nishaya/items/3d9a95f559d0c22d8134
$ gcloud auth login
正しくログイン出来ると "You are now authenticated with the Google Cloud SDK!" というブラウザページヘ飛ばされる
そうして認証が完了したら、Vision APIを叩くコードを実行(※Python2で実行)
コードは@hik0107さんの社内勉強会記事を参考にさせてもらいました
# -*- coding: utf-8 -*-
from glob import glob
from collections import Counter
import matplotlib.pyplot as plt
import requests
import random
import pandas as pd
import numpy as np
# Google Cloud Vision APIで使う
import base64
import httplib2
# 以下2つはeasy_install --upgrade google-api-python-client でimportできるっぽい <- pip install すると何故かコケまくった
# 参照: https://developers.google.com/api-client-library/python/start/installation#system-requirements
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
# 画像の扱いに使う
from PIL import Image, ImageFont, ImageDraw
# from StringIO import StringIO
plt.style.use('ggplot')
'''
Google Cloud Vision APIのオブジェクトを返す関数
'''
def authorize_visionapi(apikey):
DISCOVERY_URL='https://{api}.googleapis.com/$discovery/rest?version={apiVersion}'
# APIを叩くためのオブジェクトを作成
#credentials = GoogleCredentials.get_application_default() # service account方式の認証を使う場合にはこちらを使う。今回は必要なし
service = discovery.build('vision', 'v1',
#credentials=credentials,
#↑今回はAPI key使ってるので関係ないが、GoogleCredentialsを使えば、API key無しで認証が完了してAPIを動かせる、的な感じなのかもしれない
discoveryServiceUrl=DISCOVERY_URL,
developerKey=apikey)
return service
'''
画像ファイルのパスを与えると、{画像名 : ラベルのリスト} 形式で辞書を返す関数
'''
def get_labels(service, photo_file):
# 取得するラベル数を指定
maxresult = 5
with open(photo_file, 'rb') as image:
# 画像データをbase64形式に変換する(cloud vision APIに投げるために画像に対してこの変換が必須)
image_content = base64.b64encode(image.read())
service_request = service.images().annotate(body={
# 渡す画像ファイル情報、エンコードしたもの
'requests': [{
'image': {
'content': image_content.decode('UTF-8')
},
# 使うサービスとそのパラメータ
'features': [{
'type': 'LABEL_DETECTION',
'maxResults': maxresult
}]
}]
})
response = service_request.execute()
label = response['responses'][0]['labelAnnotations']
return label
'''
Twitter REST APIから集めてきた画像URLをイメージとしてフォルダにどしどし保存していく
'''
list_urls = []
count = 1
for line in open('./GWtweets_pics.txt','r'):
url = line.replace('\n',"")
list_urls.append(url)
# 写真urlをランダムに選んで画像を落としてくる
for i in range(0,400): #今回は適当に400枚ランダムに選択
rand_url = random.choice(list_urls)
rand_img = requests.get(rand_url)
fname = './golden_week/file_{}.jpg'.format(count)
f = open(fname, 'wb') ; f.write(rand_img.content) ; f.close()
count += 1
list_file = glob('./golden_week/*')
# Cloud Vision APIのサーバーキー
# 本当は別のファイルに書いて参照したほうがいいけど今回はベタ書き
cloudvision_api_key = 'xxxxxxxxxxxxxxxxxxx'
service = authorize_visionapi(cloudvision_api_key)
list_tags = []
for twitter_img in list_file:
try:
# 1枚の画像にラベルされたprobabilityの高いラベルtop5を取ってくる
tagdata = get_labels(service, twitter_img)
list_tags.append(tagdata[0]['description'])
list_tags.append(tagdata[1]['description'])
list_tags.append(tagdata[2]['description'])
list_tags.append(tagdata[3]['description'])
list_tags.append(tagdata[4]['description'])
except:
pass
# CloudVisionAPIから400枚分の写真のタグが返ってくるのにだいたい8分、500枚では12分ほどかかった
'''
集計したタグをグラフ化する
'''
countdata = Counter(list_tags)
countdata = pd.Series(countdata)
print 'number of detected tags are ',len(countdata) #取得したタグの種類数を確認
print 'total number of tag count is ',countdata.sum() #取得したタグの合計数を確認
print countdata.sort_values(ascending=False) #取得したタグを数の多い順に出力してみる
distribtion = countdata.sort_values() / countdata.sum() * 100 #タグの分布割合を算出
# カウント数の多いtop20タグをグラフ化
distribtion.tail(20).plot(kind='barh')
plt.title('top20 detected tags in #GW tweet pics and percentages%')
plt.xlabel('% of tag share out of all tag count [%]', size=12)
plt.ylabel('Detected Tags', size=12)
plt.xlim(0,6)
- 結果
今回は23,299枚の取得した画像から400枚の画像をランダムに選んでVision APIに投げた。1枚の画像からprobabilityの高いtop5のタグを収集 × 400枚分。
※ツイッターに添付されていた画像は、ツイッターデフォルトの写真機能によってアップロードされたものに限定している(つまりInstagramなどの写真は含まれない)
3-1. 結果

- 取得したタグの種類数は449タグ
- 取得したタグの個数は1,521個(本来なら400枚×5tags = 2,000tagsあるはずなので、実際はすべての写真から5tagづつ回収できているわけではないっぽい)
- 一番多い"person"タグでも42タグだった
3-2. 解釈
- やっぱり自撮り系、ごはん系が多い...?(twitterに自撮り晒す人 意外に多いのだなぁ)
- "advertising"は、「GWセール!」みたいな広告ツイート。スマホ販売店やアパレル系広告など確かに多かった印象
- "vehicle"とか"sports"とかゴールデンウィーク臭する(むりやり)。やっぱりタグ情報からだけではリア充写真かどうかの判断はできない
- しかし実際に取得した写真を眺めてみると、意外に(予想通りに?)カップルや仲間同士の集合写真とかリア充っぽい写真が多かった気もする
実際に収集した写真の一部(公開ツイートではあるが一応控えめに載せてみる)
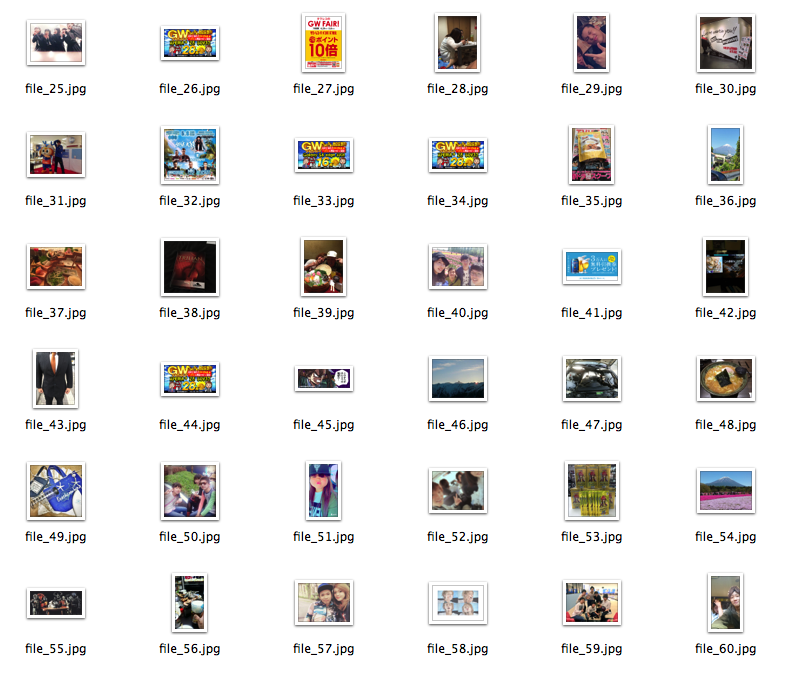
ちなみに "cartoon" タグはGWが終わることに対する煽り系ネタ画像など...


- 感想
- 最終的にはありきたりな結果になったなぁ。。。
- SNSに集まる画像から取り出されるタグのバラエティーが多すぎるので、それを集計したとしてもあまり意味のある結果は取り出せなそう
- 特定キーワードを指定しないノーマルツイートを同日から取得して、写真タグのバラエティー比較したかった(が、Vision APIの無料枠が尽きたので断念)
- 添付写真対象をInstagram(おしゃれ写真)に限定した場合、タグの種類と分布が変わるか試したかった(SNSの文化が違うのでたぶん変わりそう)
Twitter REST APIについて感想
- 使おうとするたびにAPI利用方法変わってる印象あるのでなんだか面倒くさい
- サーバーエラーとかサーバーが高負荷とかなんだかんだでセッションが頻繁に途切れるので、大量のツイートをゲットしようとすると根気が必要そう(コード中でエラー処理をちゃんとできていない疑惑あり)
Google Cloud Vision APIについて感想
- 画像を突っ込むとその画像に説明するテキストが出てくる体験は単純に興味深い
- 画像認識を何も考えず遊べるのはやはりスゴイ。でも例によって準備が面倒くさい
- 大量に画像を投げても意外に結果が返ってくるのが早い
- 1000枚/月5ドル、安いような高いような...
- 公開されているSNSデータであっても一般人の"写真"を大量に収集するのはインモラルな気分がする。しかしVision APIのように写真からタグだけ抽出してその後、元の写真は削除するという方法ならプライベートな画像データでも活用ができそう。
- というか、百貨店に設置したカメラの画像から来店客の属性データ(性別・予想年齢など)を抽出するなど実際にやっている会社もある(もちろんここでやったようなチープな方法ではない)。
- 参考にしたページ
-
スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1
http://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2 -
Google Cloud Vision API Label Detection Tutorial
https://cloud.google.com/vision/docs/label-tutorial
その他お世話になったサイト
- PythonのUnicodeEncodeErrorを知る
http://lab.hde.co.jp/2008/08/pythonunicodeencodeerror.html
=> Unicode型の注意点を改めて整理できた
- Python2で文字列を処理する際の心掛け
http://qiita.com/FGtatsuro/items/cf178bc44ce7b068d233
=> PYTHONIOENCODING=utf-8 という方法知らなかった
=> Python3をつかえやオラ、という話
- Python実行時にInsecurePlatformWarningが出る場合の対応方法
http://qiita.com/testnin2/items/97ddb749879415b23e18
=> requestsパッケージを2.5.3以前に戻す手段をとりました
- pip install: Please check the permissions and owner of that directory
http://stackoverflow.com/questions/27870003/pip-install-please-check-the-permissions-and-owner-of-that-directory
=> 何かをpip installしようとすると"そのディレクトリには権限ないぞ"と怒られた。そんな時は sudo -H pip install すればいいらしい