以前、ちょっと大きなデータを分析する必要があり、処理にかなりの時間がかかっていました。
その際、処理高速化のために使った方法をまとめます。
以下は、multiprocessingモジュールを使ったものです。
インポート
multi.py
from multiprocessing import Pool
from multiprocessing import Process
使い方
基本
こんな感じです。
multi.py
def function(hoge):
#やりたいこと
return x
def multi(n):
p = Pool(10) #最大プロセス数:10
result = p.map(function, range(n))
return result
def main():
data = multi(20)
for i in data:
print i
main()
この場合だと、「0,1,2・・・19と値を変化させてfunctionを20回実行する」という処理になります。
functionの返値はresultにリストで入っているので、受け取って標準出力しています。
また、私の環境では12コア(正確には6コア12スレッド)まで使えるので最大プロセス数は10としました。
最大まで使うとブラウザを開くのも一苦労になるのでやめておいた方が無難です。
CPU使用率
並列処理中のCPU使用率も載せておきます。
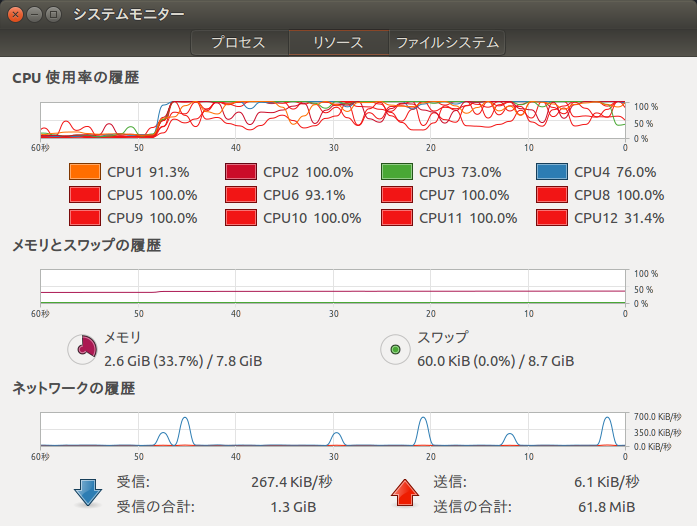
このようにきちんとマルチコアで並列処理ができていることが分かるかと思います。
プロセスid取得
各処理を担当しているプロセスidを取得することもできます。
multi.py
import os
def fuction(hoge):
#やりたいこと
print 'process id:' + str(os.getpid())
return x
# 以下省略
こうやって表示させておくとちゃんと異なるプロセスで実行されてるんだなあということがわかっておもしろいです。
高速化はどれくらいできたか
35時間ほど掛かった処理が4時間ちょっとで終わりました。
処理時間、10分の1弱ということで十分な成果です。
もちろん1プロセスごとの速度が上がっているわけではないので、効率化するためには均等に割り振れる仕事である必要がありますが、分析系ではそういったものが多いので役に立つのではないかと思います。