Speech to Text(STT)とは
Speech to Textは、Bluemixで提供される音声認識機能です。
この記事で伝えたいこと
node.js、WebRTC、STTにより、ブラウザ上でwavファイルを生成、watson-developer-cloudのSTT による音声認識結果をブラウザに表示する処理を実現しています。アプリケーションを開発する際の課題、留意事項を伝えたいのです。具体的な作業については、以下にまとめています。
1. Node.js関連の準備(Node.js導入、動作確認)
2. wavファイル生成Javascripソースの記述
3. STTで音声認識Javascriptソースの記述
4. Bluemixにデプロイ
5. おわりに
作業環境について
・Windows 7 SP1 64bit
・Firefox ESR 45.1.1
・Lenovo Thinkpad x230/CPU i7-3520M/Mem 16GB
Node.js、Express、その他は後述のpackage.jsonを参考にしてください。JavascriptやHTMLといったソースファイルはTeraPadで作成し、文字/改行コード指定保存(文字コード:UTF-8、改行コード:CR+LF)を選択しています(そうしないと、Windowsでは文字化けが発生して開発をスムーズに行えません)。
基本的には、Bluemixでデプロイするため、Node.js、Express、EJSなどのミドルウェアや関連モジュールは、STTのサンプルアプリケーションとしてGithubで公開されているspeech-to-text-nodejsに含まれるバージョンを使用します。蛇足ではありますが、DOS窓でcurlを実行するとSTTの結果に含まれる日本語が文字化け、javascriptではファイルのパス指定する際には\ではなく\\にする必要がある、とWindows環境はnode.jsの開発には不適です(Macの方が適しています)。
ソースファイルの画面イメージ
最初に、wavファイルを生成します。本アプリケーションの目的のひとつは動作の説明ですので、操作中は、FirefoxでF12キーを押して、ソースファイル中のconsole.logの出力を確認できるようにしてください。
StartRecodingをクリックすると「マイクをxxxx(サーバーのurl)と共有しますか?」というメッセージが表示され「選択したデバイスを共有」をクリックすることで録音が開始されます(PCに付属するマイクが適切に設定されていることが前提です)。余談ですが、怪しいサイトを閲覧すると盗聴されるのではないか?、といった懸念を持っていたのですが、クライアントPCのHWドライバーやWebブラウザの改造が必要なので、かなり難しいと思いました。
StopRecordingをクリックすると録音が停止されます。
StartPlayingをクリックすると録音内容が再生されます(PCに付属するスピーカーが適切に設定されていることが前提です)。
GenerateWAVをクリックすると、F12キーをでFirefoxのコンソールを表示していれば、WebRTCのメモリ空間上の音声データがwavに変換されたデータを持つオブジェクトのURIが、コンソールに出力されます。
DownloadWAVをクリックすると音声データがDownloadされます。
Uploadをクリックすると、音声認識のための画面に遷移します。
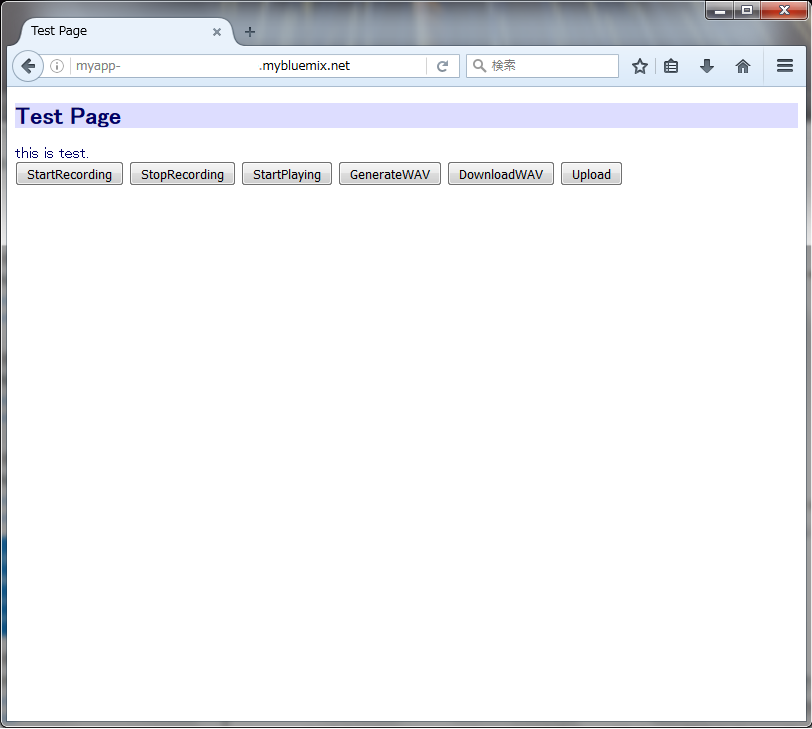
音声認識の画面では参照をクリックし、wavファイルを生成する画面で得られた音声ファイルを選択、Uploadをクリックします。↓の画面はUploadクリック直前です。選択したファイル名は、E5SKxjo0.wavです。
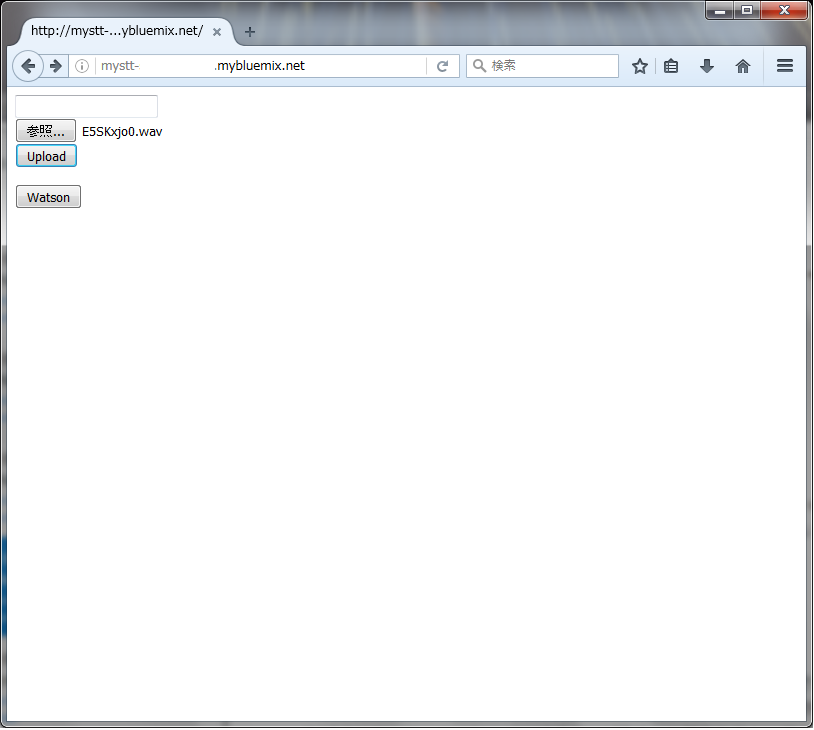
Uploadをクリックすると、サーバー側にUploadされ、属性情報が表示されます。ブラウザの戻るボタンで上記画面に戻ります。
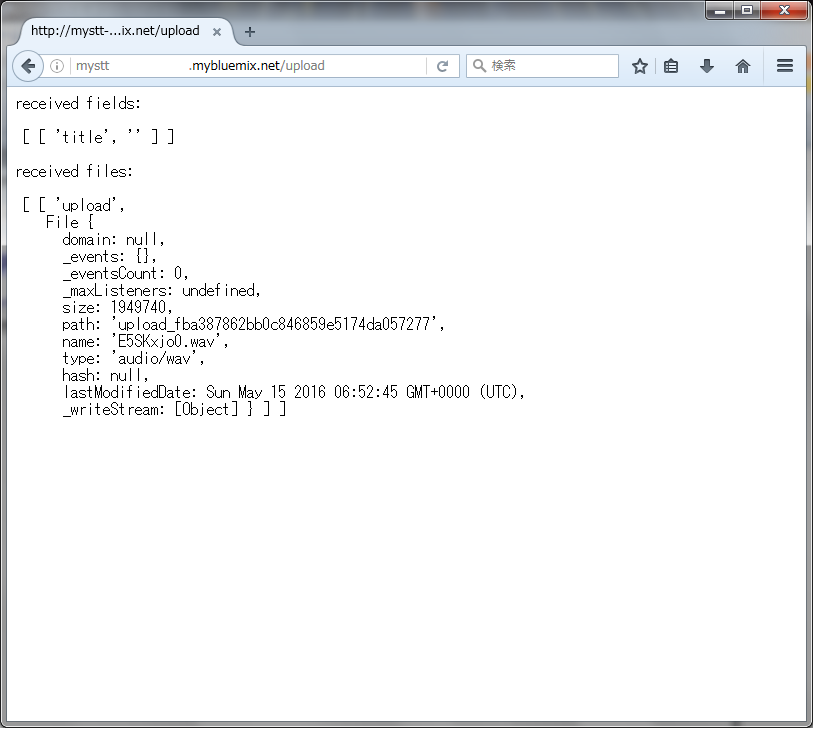
次にWatsonをクリックすると、STTの音声認識が実行されテキスト情報が返されます。このファイルでは、「日本IBMの商品について教えてください」という話し声の録音データが含まれています。テキストデータに漢字やアルファベットが含まれていることに注目してください(STTが意味を理解しているからこそ、漢字やアルファベットになっています。もし、理解していなければ、すべて、平仮名になっているハズです)。また、"confidence"は"transcript"が "日本 IBM の 商品 に ついて 教えて 下さい "になる確率を示します。確率が0.7以下だったら、もう一度話してください、とリクエストすることで話者の意図を明確にする、といった利用方法が考えられます。また、 "timestamp"キーは、例えばwavファイルの1.62秒目から2.01秒目までの音声データを"日本"という単語であると解釈されていることを示しています。
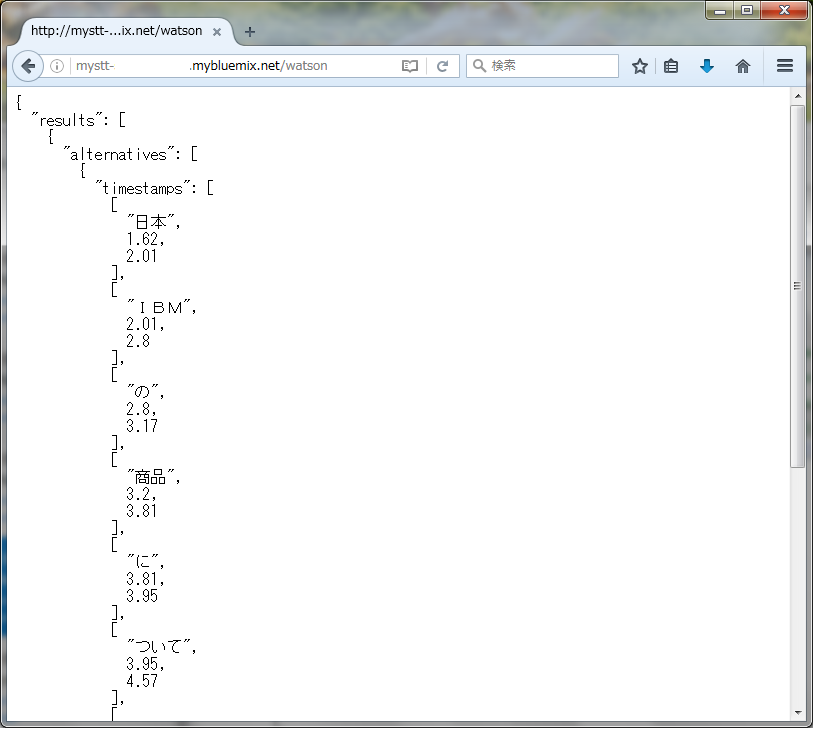
:STTの出力
{
"results": [
{
"alternatives": [
{
"timestamps": [
[
"日本",
1.62,
2.01
],
[
"IBM",
2.01,
2.8
],
[
"の",
2.8,
3.17
],
[
"商品",
3.2,
3.81
],
[
"に",
3.81,
3.95
],
[
"ついて",
3.95,
4.57
],
[
"教えて",
4.6,
5.11
],
[
"下さい",
5.11,
5.73
]
],
"confidence": 0.979,
"transcript": "日本 IBM の 商品 に ついて 教えて 下さい "
}
],
"final": true
}
],
"result_index": 0
}
テキスト化終了