はじめに
API Gateway にやってきたリクエストのうちGETメソッドについてはS3のオブジェクトを返す
ということをやってみました。
これは、商品情報のような以下の特性を持ったデータの取得について
性能問題を無視できるようしてみたいというニーズから考えて見ました。
- 公開目的でセキュリティーの考慮が不要
- データ取得の頻度が高く、秒間数アクセス
- データ更新頻度は1日1回程度で高くない
ということで、WebAPIで毎回DBアクセスを行うのではなく
戻り値そのものをS3に置いておいてしまったらどうなのか試して見ました。
じゃあ、ただS3をそのままとればいいじゃん?
となるんてすが、API Gatewayをかませることでさらに以下のようなメリットを生み出そうと考えました。
- POST/PUTではLambdaを呼び出せ、同一URLで更新が出来、RESTっぽい。
- Cloud frontのキャッシュが使える
- 不正なURLの場合、カスタムエラーを出せる
ということで、まずはAPI GatewayからS3を呼び出してみます。
S3へのファイルアップロード
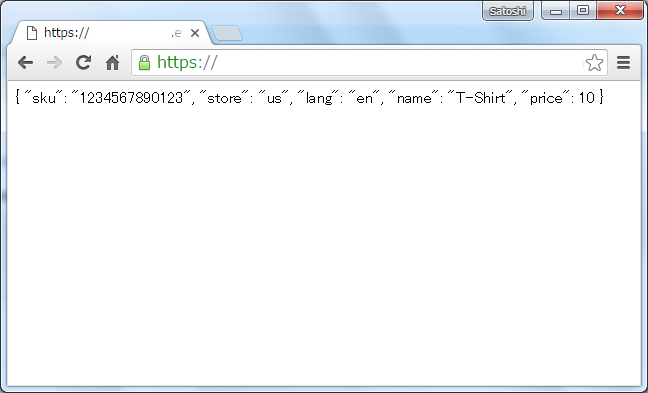
最初にS3に戻り値となるjsonを持ったファイルをアップして公開します。
ブラウザで見ると、こんな感じです。

API Gatewayの設定
API Gatewayでは、まずResourceを作成します。
ここでの注意点はResourceは1階層ずつ作る必要があることです。
今回の例ではitemの下にitem idを指定出来るようにします。
なので、item には何のメソッドも紐付きません。
追々、ここに検索用のEndpointを作るのもありですね。

itemの下に{id}というResourceを設定します。
これでAPI Gatewayはidをパラメータと認識します。
GETメソッドと追加しますが、Integration TypeをHTTP Proxyとして、
Endpoint URLに取得したS3のバケットを指定します。
ここでは、{id}で指定された値のテキストファイルを取得するようにしています。
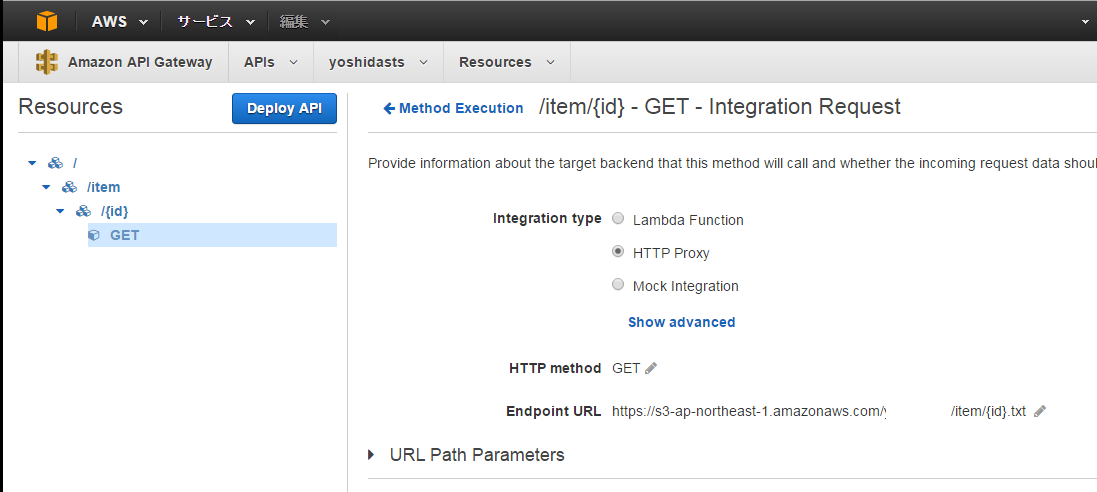
次にS3の{id}にセットする値を設定します。
同じ画面のURL Path Parametersで以下のように設定します。

このmethod.request.querystringでクエリ文字列を取得できます。
ただし、querystringでidというプロパティを追加するには、もう一手間必要です。
idというプロパティを作ってあげないといけません。
これはMethod Requestの方で設定します。
Request Pathsにidを設定します。
これで、method.request.querystringにidというプロパティが追加されます。

これにてブラウザでAPI GatewayのEndpointにアクセスして、
S3の内容が表示されるようになりました。