- 日時: 2014-12:12 19:00~22:20
- 場所: FreakOut
- イベントURL: http://gcpja.connpass.com/event/9647/
- togetter: http://togetter.com/li/756806
- スライドは見つけ次第、追記予定

トレタのBigQuery / Google Apps Script活用術
Apps Script
- 最も簡単に動かせる Server Side Javascript
- 無料
- DB, bq にもアクセスできる
たかはしさん
- slack ボット、勤怠管理、おはよう・お疲れさまとつぶやくだけ
- Google Spreadsheet に記録
- Google Apps Script で記述
- 公開されてる、https://github.com/masuidrive/miyamoto
BigQuery の利用状況(前職)
- MySQL の内容をバッチで 1 回 / 1 日全コピー
- マーケの人が SQL を書けたので
bq の利用状況(いま)
- MySQL の内容をバッチで 1 回 / 1 日全コピー
- 個人情報はコピーしないので、いろんな人に使ってもらってる
- 非正規化を行う、あとで join しなくて済むように
- ログは fluentd 経由で
- どうやって可視化する(アクセス手段の確保も)が課題
- みんな SQL たたけない
- Google Apps Script -> Slack で実現してる
bq の可視化
- BigQuery ボットがサマリ情報を毎日つぶやく
- また、Spreadsheet で 1 ページにグラフ化させている
- SQL も Spreadsheet に書くようにすれば、仕様の更新も比較的簡単にできる
作りたい(作ってる)もの
- mysql2bq
- mysql のデータを bq にコピーする
- BigQuery Cheats
- bq の結果から単純なグラフを生成
Kubernetesの機能とデモ、開発体制について
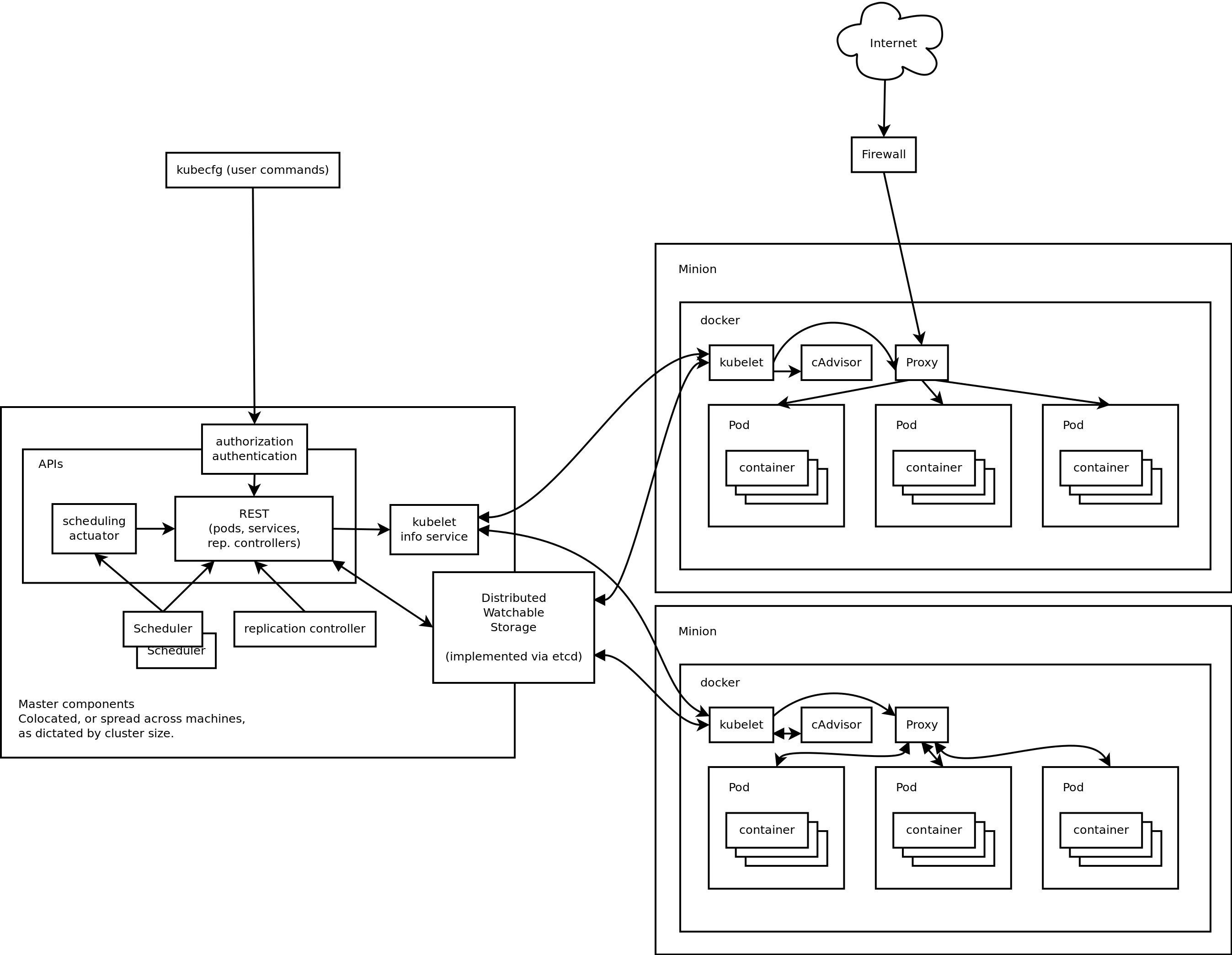
Kubernetes とは
- docker container をデプロイしてスケジュールするもの
- 全体をどう統合するのかという課題に対応するプロダクトが Kubernetes
- docker は単独のコンポーネントをデプロイするのは簡単になった
- だが、docker コンポーネント同士を連携するのは難しい
- 簡単に何をしているかというと
- マスターノードがコマンドを受け付けたら、スレーブに docker のコンテナーイメージを適当に配置してくれる
- 略称、Kube
3 つの概念
Service- 個々のコンポーネントを抽象化したもの
- 抽象的なので実装が必要、
Replication ControllerとPodが行う Replication Controller- サービスを実装する
-
Podのレプリケーション Pod- コンポーネントを配置する際の最小単位、この概念があると色々便利というのは Google の経験則が生かされた結果だろう
- これを
Replication Controllerがコピーする(必要なら)
大まかな仕組み
- Kube はマイクロサービスをデプロイするためのもの
- 設計上の前提
- ひとつひとつのコンポーネントはマイクロサービスである
- それぞれは特定の機能にフォーカスして、他のサービスと通信して依存しあう
- それでいて全体でシステムを構成する
- そのうちのいくつかは外部に公開されている
- このマイクロサービスが、上記概念の
Serviceである - サービス内では、サービスを実装するコンポーネントが複数並んでいて、それらはロードバランスされている
- その配備されている一個一個のコンポーネントが
Podである - ひとつのマシーンにて、複数の
Podを走らせることもある - 1 つの
Podは 1 つ以上の docker コンテナーを持っている
guestbook アプリというサンプルを例に
- 3 つのサービスによって、ひとつのウェブサイトが出来上がっている
- Redis master サービスがある
- Redis slave サービスがある
- guestbook app サービスがある
- まずは、Kube のクラスターを立ち上げる
- 次に、Redis master サービスに対応する
Podをつくる - master node は replication しなくていい(複数要らない)ので直接
Podをつくるだけになる - Kube クラスターに
Podの作成を依頼すると、Kube クラスターの管理下に redis master サービスを実装するPod(master ノード)が配置される - 今度は、redis slave の
Replication Controllerをつくるところからはじめる - json で定義ファイルを用意している
- 定義ファイルでは、1) いくつつくるか、2) その
Podインスタンスはどうつくるべきか、3) Pod 内の個々のコンテナはどう走るべきか(いわゆるシェルコマンド)を書く - クラスターに依頼したら、
Replication Controllerで指定した数だけのPodができていることが確認できる - 次に、その複数の
Podを ロードバランスするサービスをつくることになる - ロードバランスサービスでは、どの
Podが自分に属するのかを定義すれば、それにマッチするPodに自動でロードバランスするようになる。 - 最後に、redis を使うウェブアプリの
Replication Controllerをつくる - クラスターに作成を依頼すると、適当なノードに割り振られる
- redis slave と同様に、その複数のノードをロードバランスする
Serviceもつくらないといけない
もう少し細かい仕組み
- Kube の中心は
etcd - zookeeperみたいなもの。ロックをとったり、 kvs があったり。高可用性 KVS。
- すべての設定は
etcdに書かれる - API サーバー(= Master components)はコールを受け取ったら、最後に
etcdに書く(= 直接他のデーモンとやり取りしない) - いろんなデーモンが etcd を watch していて、必要に応じて fetch している
-
Pod作成のコールが来てetcdに書かれた場合、それをkubeletというデーモンが watch していて、Podをつくる(Minion = Slave components にて) -
kubeletは 完了したら、その対応した情報をetcdに書き込む - ネットワーク周りは
Podにプロキシがあって、それを通じて行われる -
Podは他のサービスにつなぎたければ、このプロキシに接続して、そのプロキシが他のノードにつなぎにいってくれる - さっきの guestbook での ウェブアプリサービスは redis がどこにあるかわからないけど、localhost のプロキシにつなぎにいけば、redis
Podにつなぎにいくことが出来た - これは、GCE LB を経由して外部につながることが出来る。
印象
- まだ若いプロジェクトで、デファクトがない状況
- 重要なのは将来性
- 特別なテクノロジーは使われていないが、当たり前のことを積み重ねてはいる
- そして、Google の 2 billion containers / week で培った経験が積み重ね方に現れてる
- issue の解決がめちゃくちゃ早い
- kibana の dashboard がある、ログの収集機能は fluentd を使ってる。こういう機能を自分たちでつくるのではなく調べた上で他のオープンソースを選択できる開発体制は信頼が出来ると思う。
類似
- Fleet
- 小さいものを配置するのには良い
- ただし、ネットワークをどうするかはあまり練りこまれていない
- また、Kube on Kube で同じように使うことが出来る
- Paas w/Docker(Managed VMs, Elastic Beanstalk)
- 比較的大きなマイクロサービスをここに載せるのは大変
- とはいえ、Kube の
Replication Controllerを使わないような場合には Kube は無用に複雑なのでこれらのほうがいい - Mesos
- Kube はネットワークは良く作りこまれているけれど、CPU / memory / プロセスを盛り込みたい場合にはスケジューラーが作りこまれていないので、難しい
- メモリ 2GB 空いているので突っ込むとかしたいなら、Mesos の方が良い
質疑応答
- GCE LB は差し替え可能?
- 差し替え可能。プラットフォームごとに変えられる
ログだけじゃない!BigQuery使おうぜ!とGCEも使えるよ。
紹介
- セブン & アイ NetMedia
- 妖怪メダルはけっこうあるからおすすめ
- 運用チーム、データマイニングとか監視やってる
bq との出会い
- Google 本社でまだ使ってない bq を社長が使ってると言ったから
bq の使い方
- アクセスログ、在庫、商品、顧客属性、注文明細、カテゴリのデータを
非正規化して、bq に入れたのが最初 - GAS -> bq -> GAS で現場に提供している
7 カフェキャンペーンページの検証に使ってみた
- キャンペーンの結果、より詳細にリンク先の売上がどう影響したのかを調査した
- 直リンクのもの(マンガ)、PV は伸びたけど、売上には効果がなかったり
- バナー先で紹介されているもの(料理本)、PV も売上も伸びた
- 商品カテゴリが影響したのか、バナーが良かったのか等の仮説が出てきた
bq の pro, con
- [con?] Oracle にあるマスターデータを入れているが、bq は UPDATE が出来ない
- 更新日を持たせてインポートして、View で取っている
- [con] タイムスタンプが UTC, よくわからない EACH 句
- JOIN でデータが多すぎるときには EACH 句使わないといけない
- [pro] テーブルワイルドカード
-
table_date_rangeは 指定した期間のテーブルが UNION されて使える - [con] いつもなら数十秒なのが数分たっても返ってこないことがたまにある
JOIN も早い
- リコメンドメールの開封率やコンバージョン解析で、5 億 x 1 億の JOIN が 5 分。1 回 7 円。
質疑応答
- Oracle では実現できない?
- exadata 入れてるけど、たぶん無理
- 同時に回せるのがすごくいい
- 朝一番に 200 人みんなが SQL 発行している
- 出版社別受注実績で、日次期間・月次期間・出版社を Google スプレッドシートで指定したら、商品マスターと注文データを JOIN している(現場では神ツールと呼ばれている)
- 今後は購入者のデータと JOIN しようと思ってる
- データの見せ方は?
- Google スプレッドシートの可視化の方法もスプレッドシートに書いている(前述のトレタと同じような方法)ので、現場と話しながら可視化を検討できるのが、bq だけしかできないこと
GCP最新動向まとめ
gcp live の話がメイン
GCE(過去 6 ヶ月のリリース)
-
16 コアの VMが登場 - ローカル SSD を使う場合には、CPU がボトルネックになるほど早いのでこれを使わないといけない
- Transparent maintenance(
ライブマイグレーション) - メンテナンスでリスタート騒ぎを起こさない
- vmotion をより早くやってるようなイメージ
- 200ms でメンテナンス出来ているのでは
GCE (Local SSD)
- いままでは、全部ディスクは
ネットワークディスク(ドライブ)だった - NFS のようなイメージ
- 書き込もうとすると、3 台以上のサーバーのディスクに書き込まれるので可用性はとても高い
-
Local SSDは直付けされているのでとても早いが、冗長化はされていない - FusionIO と同じようなパフォーマンスをクラウドで出来るようになったのが新しい、そして安い
- インスタンスタイプと結びついていないのも良い
- それでいて、GCE の
ライブマイグレーションにも対応予定。 - 冗長化やスナップショットがないという欠点はまだある
- CPU がボトルネックになるので、4 SSD をつけるときには 4 x 4 の 16 コア必要
- また、IRQ がボトルネックになったりもする
- ベータ版
Compute Engine Autoscaler
- ベータ版
- CPU 使用率、LB の負荷率、Google Cloud Monitoring のカスタムメトリックスをトリガーのしきい値にできる
Container Engine(GKE)
-
kubernetesの商用エンジンという位置づけ - フルマネージドのコンテナエンジン
- Alpha 版
- ゾーン、クラスタ、VM 数、VM のインスタンスタイプを指定すると Kube のクラスターが出来る
fluentd との取り組み
- Kube に採用
- Google Cloud Logging に採用
Firebase
- 買収したサービス
- GCP との統合はこれから
- NoSQL, JSON database
- milisec で変更が各クライアントにプッシュされる
Google Cloud Networking
- 大きくは次の 2 つがサポートされる
-
- Google Cloud Interconnect
- 1-1) Direct Peering -- POP(Point of Presence) に専用線を直接ピアリングすることが可能、大手向き
- 1-2) Carrier Interconnect -- キャリアの専用線経由で Google Network に接続できる、順当な感じの選択肢
-
- Google Compute Engine VPN -- 通常の VPN、以前から出来たは出来たけれど、ちゃんとしたサービスとして出てきた
Monitoring Kubernetes
Kubernetes
- Docker をクラスタ管理するにはツールが必要というところから出てきたプロダクト
- 色々な環境で動かせるのが良い
- マネージドではなくてオンプレとかで動かしたい
- リソース管理をどうするか
- Mackerel でやってみるとか試してる
Monitoring に関連する要素
kubeletcAdvisorheapster
kubelet
- 各ノード(
minion)に常駐、動作しているデーモンプロセス -
kubernetes masterと協調動作して、コンテナを配置したりしている -
minionをコントロールするプロセス
cAdvisor
- Docker の統計情報を取得する
- ホスト全体、コンテナ全体、それぞれにある
-
kubeletとは別のレポジトリにある
heapster
- リソース情報収集ツール
- kubernetes 専用
- influxDB と連携している
標準モニタリング
- heapster + cAdvisor -> InfluxDB + Grafana
- クラスタ内にあるのでクラスタが落ちると消える -- これにプロダクション依存は出来ないだろう
- 各コンテナの CPU 使用率とかメモリ使用量とかが可視化される
Minion の統計情報取得
-
kubeletの API があるので、http で取得できる
モニタリング手法
- クラスタ上で動いているものを把握するためのコマンドがある
-
Minion上のコンテナ状態取得するためのコマンドがある
pods の動的なサイズ変更
- レプリカを動的に指定すれば、オートスケールとかも出来る
GCPUG
Google Cloud Platform User Group を立ち上げました