以前の記事ではTensorFlowを使って英語から日本語に翻訳するニューラル翻訳モデルを訓練しましたが、今回は最近のチャットボットブームに乗っかって(?)、ニューラル会話モデルを訓練してみました。
環境
環境は以前の記事と同じですが、今回はAWSのスポットインスタンスを使うことでコスト削減を図りました。
- TensorFlow 0.9
- AWS g2.2xlarge spot instance
- Ubuntu Server 14.04
- Python 3.5
データ
ニューラル会話モデルを訓練するためには、発言とその発言に対する返信のテキストデータが必要になります。ここではTwitterのリプライを収集スクリプトを書き、1.3Mほどのツイートと返信先のペアを収集しました。ツイートからユーザ名、ハッシュタグ、URLは削除され、例えば次のようなペアが得られます。
| 返信先ツイート | ツイート |
|---|---|
| じょーは買ったの? | 発売日に買ったわ!^ ^ |
| ある(ノシ 'ω')ノシ バンバン | (ヾノ´°ω°)ナイナイ |
あとは以前と同じように単語分割と訓練データの分割を行います。
- MeCab 0.996とunidic 2.1.2を用いた単語分割
- 訓練データ99%とテストデータ1%のランダム分割
訓練
ニューラル会話モデルはニューラル翻訳と同じエンコーダ・デコーダモデルを使うため、今回はTensorFlowの機械翻訳のチュートリアルのスクリプトをそのまま使います。会話の場合、返信中の単語が元の発言の単語に対応するとは限らないためアテンション付きのモデルが妥当かどうかは疑問の余地が残りますが、このあたりは今後の課題としたいと思います。パラメータは前回と同じくニューロン数が512でレイヤー数は2、語彙数は返信元と返信先の両方とも40,000に設定しました。
% python translate.py --data_dir data/ \
--train_dir model/ \
--size=512 --num_layers=2
2日ほど待つと200kステップが完了し、パープレキシティは2.8まで下がりました。
global step 207200 learning rate 0.0612 step-time 0.50 perplexity 2.86
eval: bucket 0 perplexity 393.02
eval: bucket 1 perplexity 1015.13
eval: bucket 2 perplexity 295.72
eval: bucket 3 perplexity 148.09
今回はスポットインスタンスを使ったため、GPUインスタンスにかかった費用は$30くらいで済みました。
テスト
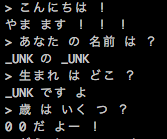
会話は翻訳よりも自由度が高いので自動評価は難しいと考えられますが、うまくいった例を見るとそこそこ賢いような気がします。

しかし、うまくいかなかった例も多くあるのでなんとも言えません。
感想
機械翻訳では翻訳文の意味は原文と同じである必要がありましたが、会話では意味的にも複数の正解が許されるので翻訳よりも易しいと言えるかもしれません。一方でちゃんとした学習に必要な語彙数やベクターサイズが大きく、特に日本語だと形態素解析の粒度が細かすぎて単語ベクトルがまとまった意味を捉えられていないように思えます。また応用について考えてみると、以下のような課題があると思いました。
- ビジネスになりそうなテクニカルサポートや電子コマースなどのでは致命的な間違いが許されないので使いづらい
- オンラインゲームなどの娯楽目的では発言に一貫性がないためキャラクター性を付与するのが難しい
ニューラル会話モデルは人間のような会話ができる事を目的関数にしていますが、人間らしさよりもタスクの完遂を優先する場合やユーザーを楽しませることを目標にする場合は工夫が必要であるように思いました。ただし、GMailのスマートリプライやiPhoneキーボードのQuickTypeの予測変換ように、入力の補助をするといった応用は比較的すぐに実現すると考えられます。