昨日は回帰分析の一例として外れ値を除去しながら相関係数を調べるといったことをしました。
昨日のような回帰分析を単回帰分析と言います。定義を述べると 1 つの目的変数を 1 つの説明変数で予測することです、その 2 変量の間の関係性を y = ax+b という一次方程式の形で表します。a は傾き、 b は切片です。
単変量解析の重要性
さらなる高度な分析として多変量解析をしていくにしても、多変量は単変量をたくさん集めたものとも言えますので、単変量の解析はその基礎となるというわけです。このように単変量解析は統計の基礎中の基礎であるということも述べました。
相関分析においては、昨日のように単変数ではわからない外れ値を取り除いて回帰式を求めるというケースの他に、相関がありそうにみえて実は無い (疑似相関) ケースや、反対に直線に回帰はしないが回帰式を求められるというケースもあります。
たとえばスープに入れる調味料の量を考えてみましょう。調味料は少し入れると美味しいですが、大量に入れすぎてしまうとかえって美味しくなくなります。このケースでは美味しさに最適値があり、そこを山として美味しさのカーブが描かれるわけです。にもかかわらず、直線の式を求めようとしたとしましょう。この場合、相関係数が高くならず、結果として相関関係が無しと判断してしまうわけですが、これが誤りであることは明らかでしょう。
ビッグデータなどという言葉が飛び交うようになっても基本的なデータ分析の考え方は一切変わりません。アンケート、商品の売上、ユーザーの行動履歴などを収集し、法則性を分析し、将来の予測につなげるということそれ自体は昔から何ら変わっていないのです。データマイニングで用いられる高度な因子分析などの多変量解析や回帰分析などにおいても基本を抑えておくことが大切です。
統計学的検定
さて、これと並ぶ統計学の最も基本的かつ重要な手法に筆者は「検定」を挙げます。検定とはある命題が妥当か否かについて、一定の確率的根拠に基づいて統計学的に判定することです。
このときの仮説としては以前にも説明しましたが帰無仮説と対立仮説というものがあげられます。
帰無仮説とは、それが棄却 (= 否定の意味) されたときに意味を持つ仮定のことです。一方、対立仮説とはその反対です。このあたりは上のリンク先の記事で詳しく説明しました。
有意性検定
仮説検定の目的は母集団について設定された命題を標本に基づいて検証することです。得られたデータが帰無仮説によって説明できる、すなわちデータの偏りが偶然生じる確率を有意確率と言います。
ここで言う検証とは、理論比からのズレが誤差の範囲内であるか、あるいはそれ以上の何らかの意味のあるものかを調べることを指します。統計学では仮説からのズレを 有意 significant と言います。統計学的検定とはすなわちこの有意性を検定することになります。
帰無仮説を棄却することはすなわち対立仮説を採択することになりますが、帰無仮説が本当は正しいのにそれを棄却してしまうことを 第一種の誤り error of the first kind と言います。帰無仮説が誤っているのにそれを棄却しないことを 第二種の誤り error of the second kind と言います。
有意性検定は、帰無仮説で期待する結果が「生じなかったこと」を根拠として、仮説を棄却するかどうかを決めます。これは論理学では背理法と言われています。棄却されなかったからといってそれが「積極的に支持されたわけではない」わけではありません。あくまで帰無仮説が矛盾しないであろうことが言えるわけであり、仮説が真であることを証明したわけではありません。
さまざまな仮説検定
統計学的検定にはさまざまなものがありますが、それぞれどういうものであるか、代表的なものについて、理論と数式とコードで追っていきましょう。
Z 検定と t 検定
Z 検定は標本の平均と母集団の平均が有意に異なるかを調べます。
母集団の標準偏差を σ とします。標本のサイズを n とします。 Z 集団は標準誤差を次のように求めます。
\frac {\sigma} {\sqrt{n}}
標本の平均から母集団の平均を引いて、上の標準誤差で除算すれば z スコアが求まります。
ただしこれは母集団の分散 (標準偏差) が判明していなければなりません。ビッグデータの時代においては母集団を全数走査するといったことが分散処理ソフトウェアなどで可能になってきましたので Z 検定を利用す
母集団の分散に替えて標本分散を利用するのがスチューデントの t 検定です。母集団から標本抽出したサンプルの分散を利用します。これはたくさんのサンプルは集められないが手元に収集した小規模なサンプルから検定をおこないたいというニーズに応えるものでポピュラーな検定方法のひとつです。
数式は次のようになります。
t = \frac {\overline{X} - \mu_0} {\frac {s} {\sqrt{n - 1}}}
なお、上の例では自由度 n - 1 の t 分布になります。
t 検定の実践
以前にもやった通りですがあらためて t 検定を試してみましょう。
ある医療薬品開発センターで新薬のテストをしています。以下の図は X 軸が従来の医薬品による効能のデータ、 Y 軸が新しく改良した新薬での効果のデータです。
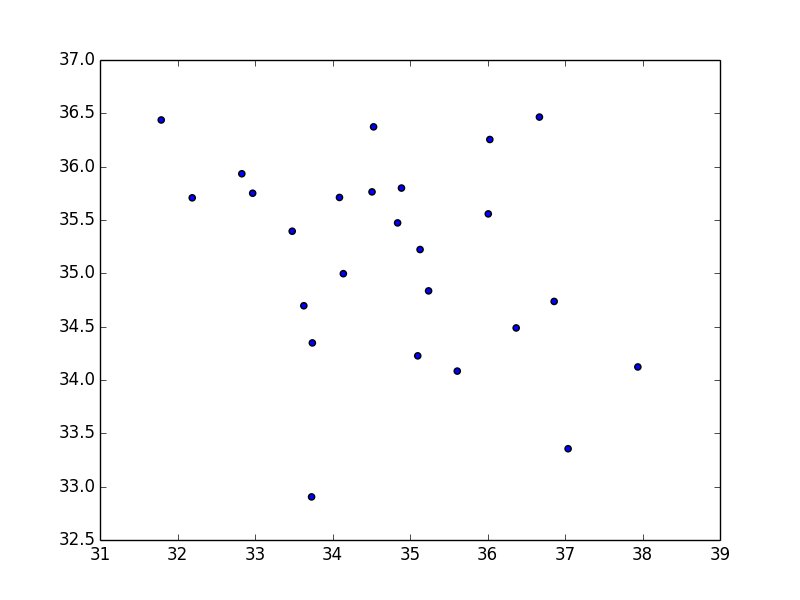
気のせいかなんとなく Y 軸の値のほうが大きいような気がしなくもありません。統計学的検定で確かめてみましょう。
- 帰無仮説 : 従来の薬品と新薬の効果に差は無い
- 対立仮説 : 従来の薬品と新薬の効果に差が有る
Python で t 検定をするなら scipy.stats.ttest_rel を利用します。
from scipy import stats
t, p = stats.ttest_rel(x, y)
print(t, p)
#=> (-0.8953592919180917, 0.379487606532)
t 値が -0.895 となり、その確率は 0.37 です。これは有意水準を 0.05 としても 0.01 としてもそれより大きいですから帰無仮説は棄却されません。
したがいまして新しく開発した新薬には従来品と比較して有意な差がなく、改良の効果がなかったと言って良いことになります。
まとめ
今回は触れませんでしたが、他にもカイ二乗検定などさまざまな統計的仮説検定があります。今日では Python 以外にも R や Excel などで簡単に計算をすることができます。理論をしっかりと理解して現実の問題に応用しましょう。