昨日は統計のウソを見破る 5 つの視点として統計的誤りに関する注意点を説明しました。
本日はここであらためて、分析しようとしているデータそのものにスポットを当ててみたいと思います。
KPI (key performance indicator) とは目標を達成するために何が必要かを定量的に表す数値です。整形して美人になりたいというのは KPI ではありませんが、体重を 3 ヶ月後までに 10 キロ減らすとか鼻を 1.5 センチ高くするといったものは KPI です。
データにはどのような種類があり KPI として利用しようとしている指標はどんなデータなのか正しく理解していないとしばしば誤った KPI を導き、無意味なデータ分析へとつながる危険を孕みます。
変数とは
社会調査や医療統計など様々な分野で被調査対象者の状態を多方面から特定していきます。たとえばアンケートやカルテを想定してみましょう。あなたは性別は何ですか、年齢はいくつですか、と質問していきます。このとき取る値は大きく 離散変数 (discrete variable) と 連続変数 (continuous variable) に分けられます。このうち離散変数は測定値の境界線を明らかにできるものを言います。たとえば性別などがそうです。この離散変数は順序をつけられるかどうかでさらに 2 つに分けられます。
- 順序付け不能な離散変数 (例 性別、国籍、所属している会社)
- 順序付け可能な離散変数 (例 成績: 1. 優 2. 良 3. 可 4. 不可)
- 連続変数
尺度とは
変数はその性質について次のようにその尺度水準を分類されます。
-
名義尺度
単なるカテゴリとして与えられ、順序を付けられない変数は名義尺度です。出身地、所属する会社などはこれにあたります。名義尺度は当然のことながら平均を求めたりすることはできません。ただし、最頻値を取ることはできます。 -
順序尺度
上で言う順序付け可能な離散変数を評価する尺度です。順位などがこれに相当します。あくまで順序でしかないので、 1 位だから 2 位の人の 2 倍だというような計算をすることはできません。なぜなら 1 位の人は 2 位の人と僅差で 3 位以下の人とは大差、というふうに、目盛間隔が一定では無いからです。平均や分散を求めることはできません。 -
間隔尺度
ゼロを起点としない連続変数です。たとえば時刻、気温などが相当します。時刻が 20 時だから 10 時の 2 倍だとか、温度が 30 度だから 15 度の 2 倍暑いというような評価はできません。ただし、その間隔自体は意味がある点が順序尺度との違いです。平均や分散などの要約統計量を求めることができますが、比率を求めることはできません。 -
比例尺度
ゼロを起点とする連続変数です。たとえば売上、価格、ユーザー数、ある日からの経過日数、百点満点のテストの得点などです。
代表値とは
要約統計量とはデータを要約するために統計的操作を加えて求めた数値のことです。代表値とは要約統計量でもとくに使われるポピュラーなものです。平均といえば馴染みがあるでしょう。みんなで飲み会をしたときの一人当たりのお金の計算をはじめとして日常的によく利用されます。
- 平均値
観測された値をすべて足して個数で除算したもので算術平均とも言われます。すべてのデータから求まるため、全体の変動を表すという利点があります。欠点は外れ値の影響を受けることです。このため上位または下位の数パーセントを除いて平均を求めるといったトリム平均が利用されることもあります。
- 中央値
観測された値を並び替えた時にちょうど真ん中に位置する値です。分布形状が不明である場合や外れ値を多く含むと予想される場合に有効です。
- 最頻値
その名の通りもっとも観測された値です。
いずれにせよ注意すべき点として、あくまで要約であるため何らかの情報が欠落していることに気を付けるべきです。
例
ある幼稚園の構成人数を調べた年齢の分布を示しています。
| 年齢 | 人数 |
|---|---|
| 3 | 15 |
| 4 | 28 |
| 5 | 31 |
| 6 | 15 |
| 22 | 1 |
| 25 | 1 |
| 46 | 1 |
| 49 | 1 |
| 70 | 1 |
| 75 | 1 |
この場合の代表値として上記のいずれを適用するのが最もふさわしいか考えてみてください。
線形回帰
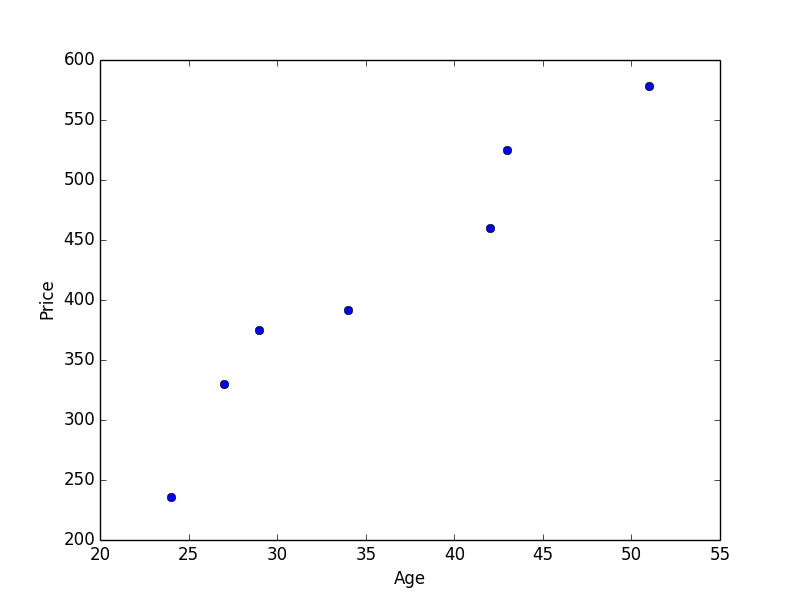
長々と変数について説明しました。そろそろ統計らしいことをやってみましょう。次のような変数があったとします。これはある化粧品販売店での、購買顧客の年齢とそのお買い上げ金額を表にしたものとします。
| 年齢 | 価格 (単位 100/円) |
|---|---|
| 24 | 236 |
| 27 | 330 |
| 29 | 375 |
| 34 | 392 |
| 42 | 460 |
| 43 | 525 |
| 51 | 578 |
このとき、年齢は間隔尺度、価格は比例尺度にあたります。
データをプロットする
プロットとは要するに変数からグラフを描くことです。なぜグラフを描くのでしょうか。グラフを描くことで変数を視覚記号で図示し可視化します。これによってデータを把握しやすくなったり、仮説を立てる手助けをしたりします。
Python の NumPy と matplotplib は統計数理で非常によく使われる素晴らしいライブラリで、統計的手法による図示のための機能がきわめて強力かつ手軽に扱えます。とにかく散布図を描いてみましょう。
import numpy as np # NumPy の読み込み
import matplotlib.pyplot as plt # matplotlib の読み込み
v1 = np.array([24, 27, 29, 34, 42, 43, 51]) # 年齢を表すリスト
v2 = np.array([236, 330, 375, 392, 460, 525, 578]) # 価格
plt.xlim(20, 55) # X 軸の範囲を指定
plt.ylim(200, 600) # Y 軸の範囲を指定
plt.xlabel('Age') # X 軸のラベルを年齢に
plt.ylabel('Price') # Y 軸のラベルを価格に
plt.plot(v1, v2, 'o', color="blue") # 描画する
plt.show() # 画面に画像を表示する
plt.savefig("image.png") # 画像をファイル名を付けて保存する
このような散布図ができました。
一次関数を求める
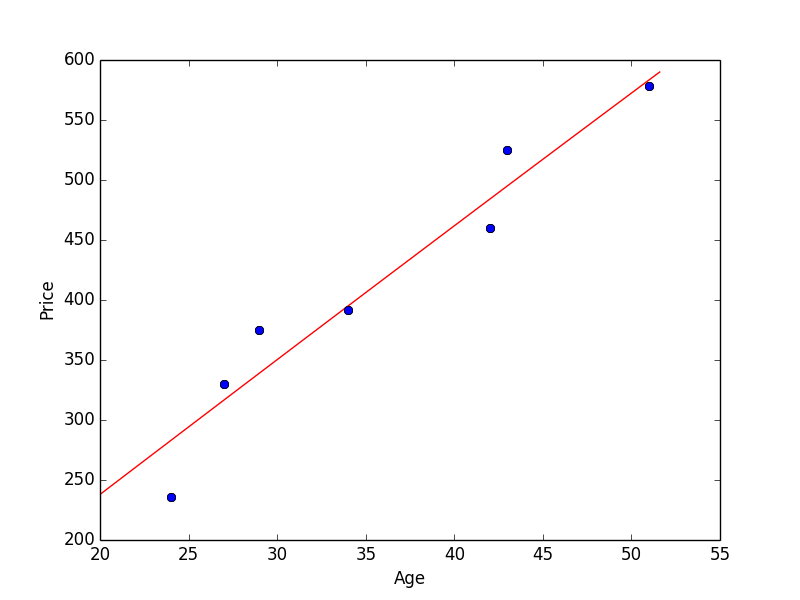
さて、図を眺めてみるとどうやら顧客の年齢が上がるほど購入した化粧品の価格が高くなっていく傾向があるような気がしてきます。人間の感覚だと、なんとなく右上がりに直線をひきたいような気持ちになりますね。
数学的には、適当なモデルから想定される 1 次関数 (y=2x などです) や対数曲線など特定の関数を用いて近似する回帰分析の一種を線形回帰と言います。
まずはプログラムで線形回帰を実際におこなってみましょう。
import numpy as np
import matplotlib.pyplot as plt
v1 = np.array([24, 27, 29, 34, 42, 43, 51])
v2 = np.array([236, 330, 375, 392, 460, 525, 578])
def phi(x):
return [1, x, x**2, x**3]
def f(w, x):
return np.dot(w, phi(x))
PHI = np.array([phi(x) for x in v2])
w = np.linalg.solve(np.dot(PHI.T, PHI), np.dot(PHI.T, v1))
ylist = np.arange(200, 600, 10)
xlist = [f(w, x) for x in ylist]
plt.plot(xlist, ylist, color="red")
plt.xlim(20, 55)
plt.ylim(200, 600)
plt.xlabel('Age')
plt.ylabel('Price')
plt.plot(v1, v2, 'o', color="blue")
plt.show()
plt.savefig("image2.png")
このように直線 (= 一次関数) が求まりました。近似解が得られたように見えますね。
線形回帰の詳細な話は教科書に譲りたいところですが、次回は線形回帰とその応用についてなどを考察してみたいと思います。
参考
社会統計学入門 (放送大学教材)
http://www.amazon.co.jp/dp/4595313705
[PDF] 統計学入門 - 小波秀雄
http://ruby.kyoto-wu.ac.jp/~konami/Text/Statistics.pdf
エンジニアのための データ可視化[実践]入門 ~D3.jsによるWebの可視化
http://www.amazon.co.jp/dp/4774163260