いままで統計の実践的な方法について書いてきましたが、統計学や計量経済学を身につけるとデータ分析で次々と未来を予測できて株などの投資で大儲けできるのでしょうか。いいえ、それならば統計学者や経済学者は研究もそこそこに投資にせっせと精を出し今頃は大金持ちになっているはずです。
ウォール街のランダム・ウォーカーでは、多くのプロのファンドマネージャーが上場株式全体をランダムに買うような投資方法に勝てていないという科学的実証データが書かれています。将来の予測不能性というのはさまざまな要因が複雑に絡むため、未来を予測するのはとても難しいのです。
たとえば医療統計によってある栄養や生活習慣とある病気との相関関係を調べることはできます。ではこれによってあなたがいつ病気で死ぬか正確に予測できるようになるのでしょうか。もちろんそんなわけはありません。データ分析によってあなたがいつ死ぬかということを正確に予測できるわけではありません。
すなわち因果関係の洞察がとても大切であるということです。
たとえば仕入れと販売に携わっている担当者ならば売上につながりやすい商品のポイントは何か、営業担当者なら成約につながる決め手となる要因は何か、人事なら自社の利益につながる人材を育てるための鍵は何か、こういったポイントをデータの分析から明らかにしてくのが肝心です。
そしてそれはデータサイエンティストと名乗るスーパーマンか魔法使いのような人物が颯爽とあらわれて問題を解決して去っていくのではなく、第一線の現場での地道な日々の努力と多少の統計分析によって問題発見と解決の糸口をつかむものです。
たとえばある季節のある時間帯に特定の商品が売れているということが明らかになったとき、計算機による分析ではその商品を多く仕入れましょうという結論にしかなりません。しかし店舗や商品に関わり続けてきた人間ならばその背後になる「何か」、たとえばお客様が実は〜〜を求めているからに違いない、というふうにピンと来るというものです。このように最終的には人間の洞察と判断が必要になり、それこそがとても重要です。
データ分析の対象と分析計画
今回はあるひとつの事例を例に、実際にデータを分析してそれを役立てるという流れを考えてみます。
以前に Flask でガチャのエミュレータを作りましたが、今回も題材はソーシャルゲームです。ソーシャルゲームは万人がアクセスすることができて実際に本物のデータを収集可能なので材料としては身近で便利です。
もちろん実際には店舗の売上であろうとも、営業担当者の成績であろうとも、ソーシャルネットワーク上の発言でも何でも構いません。
概要は次の通りです。
- あるソーシャルゲームでは毎月イベントがあります。
- このイベントでは参加者がスコアを競い合い、ランキングの順位によって報酬が得られます。
- ランキングの報酬やボーダーとなる順位は毎月変わります。
分析の手順は次のようになります。
- 目的を明かにする
- データを収集する
- データを整理・加工する
- 傾向をつかむ
- 判断の材料にする
目的を明らかにする
なぜこのイベントの分析をするのでしょうか。データ分析をする前にまず目的をハッキリさせる必要があります。
- 今月のイベントにも参加する
- 過去のデータから今月のボーダーをある程度予測する
- もしボーダーを予測できれば、必要最小限の投資額に抑えられる
ランキングというのはソーシャルゲームで課金を煽るための効果的な方法です。たとえば、あと 10,000 点で目的の報酬が手に入る順位になるとします。そのために必要なアイテムは 10 個で 1,000 円の課金ですみます。そこで 1,000 円課金するわけですが、ライバルも当然同じように考えて 1,000 円の課金をするわけです。これによってボーダーとなるスコアが上がりますから順位は結局上がりません。
あとちょっと、あとちょっと、のはずがその繰り返しでいつのまにか多額の課金をしてしまう、という仕組みなわけですね。
このようなじゃぶじゃぶ課金したくなるような射幸心を煽りまくるイベントの課金底なし沼を回避するためには最終的に着地となる順位のボーダーのスコアをある程度予想して、現在のランキングにとらわれずに最終的なスコアを稼ぐのに必要なだけの資金を投入するということをします。このスコアをできるだけ正確に見積もるのが今回の分析の目的です。
データを収集する
なにはともあれデータを集めなければ話にならないのですが、データ分析では多くの場合この収集プロセスが地味に大きな負担となります。
サンプルとなるデータを掲載します。
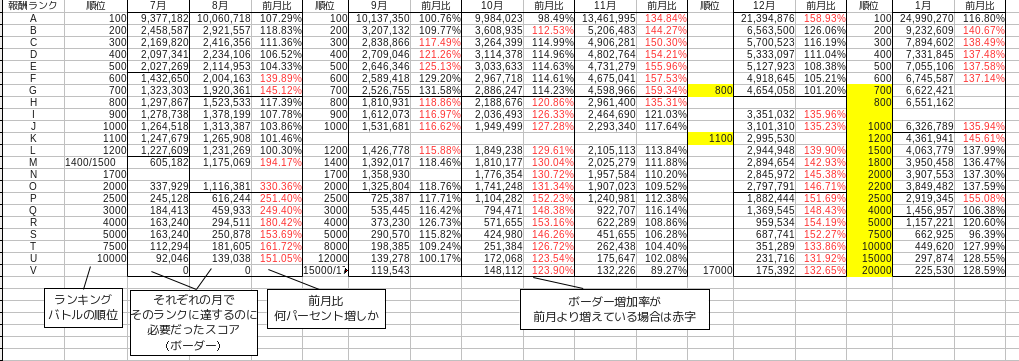
これは約半年分、つまり昨年 7 月から今年 1 月までの各月のイベント最終結果のスコアのみを収集したデータです。
毎月ボーダーとなるスコアは多少変動していますが、基本的には最上位報酬= 100 位=ランク A 、上位報酬= 700 〜 800 位=ランク G 、下位報酬= 2000 〜 2200 位=ランク O です。表では黒線で区切ってあります。ランクというのは筆者の判断で順位の上から A,B,C と付けていった便宜上のものです。ボーダーを分ける順位は毎月異なるので、上から何番目のボーダーかというランクとして考えます。
また前月比というのは順位を分けるボーダーとなったスコアが前月比どれだけ増加したかを表す割合です。これは 当月を前月で除算すれば求められます。
データを整理・加工する
このようにデータをマメに収集するだけでもなかなか負担になるものです。ただし収集のプロセスに関してはものによっては自動化することができる場合があります。
とはいえ、たとえばセンサーや自動ツールなどを通してデータベースなどに収集した後でも、データを整理するプロセスが必要です。これは人間の手で加工していくフェーズですから完全に自動化するようなことはできません。
まずは可視化して全体の傾向を見ます。とりあえずデータを可視化するのは基本中の基本となるプロセスです。方法についてはこれは pandas の基本ですのでもはや説明の必要も無いかと思います。
df = pd.read_csv("data.csv", index_col=0) # データを読んで
lines = df.interpolate(method="linear") # 欠損データを埋めて
plt.figure()
lines.plot() # ラインチャートをプロットする
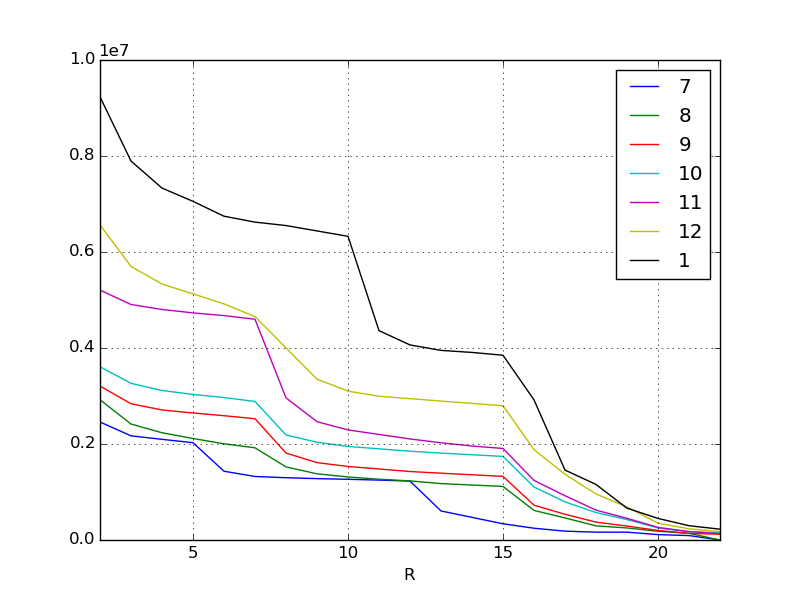
X 軸はランキングのボーダーですので左に行くほど高い順位です。 Y 軸はスコアです。各線は月を表していますが、元データを一目見ればわかるとおり毎月毎月必要となるスコアがどんどん上がって行っています。特に直近となる 1 月や 11 月あたりのインフレぶりはすごいです。
人々がどんどんお金を出して強くなっていくわけですから、当然稼げるスコアも毎月どんどんインフレしていくわけです。このような現象はほとんどのソーシャルゲームで見られると思います。あらためて現象が可視化されたわけですね。
なお上の例では欠損値の補間を線形におこないました。 pandas.DataFrame.interpolate はさまざまな基準で欠損値の補間や穴埋めができます。 pandas の強力な機能のひとつです。
後編に続きます。