昨日まで 2 回に渡り教師あり学習の代表例でもある線形サポートベクトルマシンについて話を進めてきました。もう一度機械学習について整理しておきましょう。
教師あり学習と教師なし学習
機械学習には大きく分けて 教師あり学習 (Supervised learning) と 教師なし学習 (Unsupervised learning) があります。ほかに強化学習というものもありますがここでは一旦他所に置いておきます。それぞれの特長は次の通りです。
| 関数 | 正解データ | 目的 |
|---|---|---|
| 教師あり学習 | 与えられる | 未知のデータに対する予測 |
| 教師なし学習 | 与えられない | 未知のデータから規則性を発見 |
機械学習の手法を選択する
scikit-learn には膨大な数の機械学習アルゴリズムが実装されていますが、そもそもどの手法を選択したら良いのでしょうか。筆者は大雑把な基準としてですが以下を参考にしています。
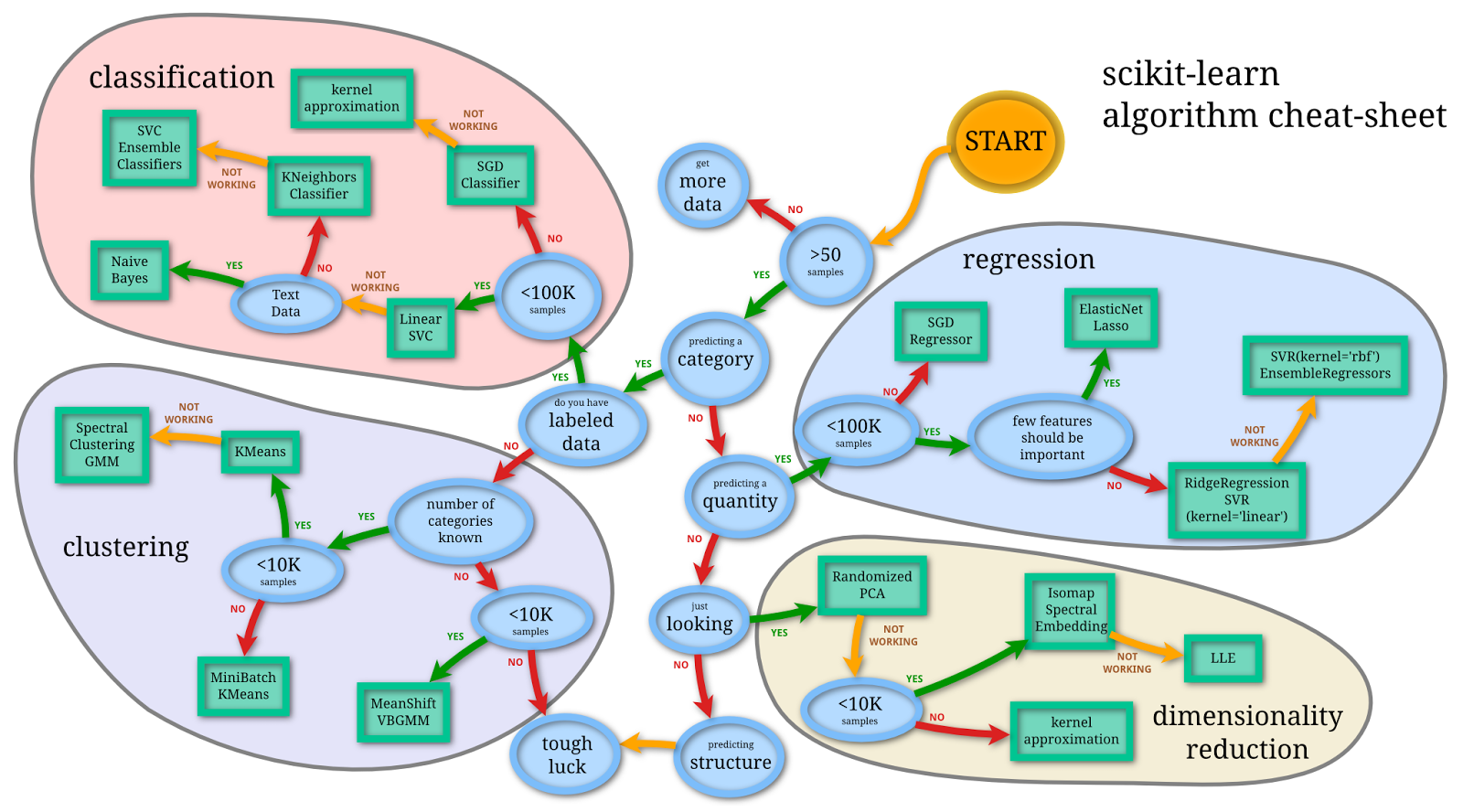
[出展]
Machine Learning Cheat Sheet (for scikit-learn)
http://peekaboo-vision.blogspot.de/2013/01/machine-learning-cheat-sheet-for-scikit.html
実際のデータで試してみる
Kaggle に投稿されたコンペのデータを拝借して教師あり学習及び教師なし学習についての色々を試してみます。以下からログインしてデータをダウンロードしてください。
Data Science London + Scikit-learn
https://www.kaggle.com/c/data-science-london-scikit-learn/data
| データ | 説明 |
|---|---|
| test.csv | テスト対象のデータ |
| train.csv | 教師データ、これを基に上記のデータを分類する |
| trainLabels.csv | 教師データの分類先のラベル |
サポートベクトルマシン
サポートベクトルマシンは疎な解を持つカーネルマシンです。カーネル関数には線形内積カーネル、ガウシアンカーネル、多項式カーネル、シグモイドカーネルなどいくつかの種類があります。ここではガウシアンカーネルを利用してシンプルな二値分類をおこないます。
import numpy as np
from sklearn import svm
import codecs
# CSV データの読み込み
train_X = np.genfromtxt('train.csv', delimiter=',')
train_y = np.genfromtxt('trainLabels.csv', delimiter=',')
test_X = np.genfromtxt('test.csv', delimiter=',')
# ガウシアンカーネルによる SVM インスタンス生成
clf = svm.SVC(kernel='rbf', C=1)
# 教師データで学習 (データに対するフィッティング)
clf.fit(train_X, train_y)
# テストデータを分類する
result = clf.predict(test_X)
# 結果をファイルに書き出す
def write_prediction(prediction, outfile):
f = codecs.open(outfile, 'w')
for x in prediction:
f.write('%s\n' % (x))
write_prediction(result, 'svm.txt')
最近傍法
データ集合から値が決定される少数のパラメータで関数形が決まるような確率密度のモデル化のアプローチをパラメトリックと言います。このアプローチでは生成データ分布を表現するために密度関数が貧弱な場合に予測性能が低下する可能性があります。
これに対し密度推定のノンパラメトリックなアプローチは分布の形状についてわずかな仮定しかおこないません。密度推定のカーネルアプローチではカーネル幅を決定するパラメータをすべてのカーネルで一定にしますが、これをデータ空間内の位置に応じて変化するモデルが最近傍法です。
オブジェクトの属性値を k 個の最近傍のオブジェクト群の属性値の平均値とし k=1 を仮定するモデルが k 近傍法です。詳しくは Wikipedia の解説辺りを読んだほうが良いでしょう。
scikit-learn の API は概ね標準化されており、サポートベクトルマシンのときと似たような感覚で k 近傍法を扱うことができます。
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier()
clf.fit(train_X, train_y) # 学習
result = clf.predict(test_X) # 分類
ランダムフォレスト
樹木モデルの集団学習のひとつで分類・回帰をおこなうランダムフォレストもよく使われる手法です。ブートストラップサンプリングでは学習データからの復元抽出をおこない、ランダム抽出変数から樹木モデルを生成、木構造の条件分岐を確立します。 (このことからランダムフォレストと呼ばれます)
欠損値を持つデータでも有効、説明変数が多数でも効率的にうまく動作する、説明変数の重要度を推定できる、高速で精度の高い学習と評価といった特長があります。
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(train_X, train_y)
result = clf.predict(test_X)
scikit-learn を利用すると多くの手法が似たパターンで統一されているのでコードも簡潔になり非常に扱いやすいですね。
交差検定
scikit-learn には様々な機械学習アルゴリズムだけでなく、モデル選択や評価のためのアルゴリズムも実装されています。
Model selection and evaluation
http://scikit-learn.org/stable/model_selection.html
交差検定でそれぞれの機械学習アルゴリズムについての検定をおこなってみましょう。
# n_jobs パラメータには同時実行可能な CPU コアの数を指定できる、これを -1 にすると実装された全てのコアで並列計算する
clf = svm.SVC() # SVM
scores = cross_validation.cross_val_score(clf, train_X, train_y, cv=5, n_jobs=1)
print( "SVM: %(scores)s" %locals() )
clf = neighbors.KNeighborsClassifier() # k 近傍法
# 評価方法は同じ
clf = RandomForestClassifier() # ランダムフォレスト
# ...
# SVM: [ 0.89 0.92 0.95 0.93 0.89]
# KNeighbors: [ 0.865 0.9 0.91 0.915 0.895]
# RandomForest: [ 0.81 0.825 0.86 0.815 0.81 ]
グリッドサーチ
サポートベクトルマシンのカーネル関数を評価し最適なカーネル関数を導出してみましょう。このようなときはグリッドサーチが使えます。
# 検索用のパラメータを設定する
tuned_params = [
{'C':[1,10,100,1000], 'kernel':['linear']},
{'C':[1,10,100,1000], 'gamma':[0.001, 0.0001], 'kernel':['rbf']},
]
clf = GridSearchCV(svm.SVC(C=1), tuned_params, n_jobs=-1)
clf.fit(train_X, train_y, cv=5)
best = clf.best_estimator_ # 最適なカーネル関数が返る
print( "Best is %(best)s" %locals() )
# =>
# Best is SVC(C=100, cache_size=200, class_weight=None, coef0=0.0, degree=3,
# gamma=0.001, kernel=rbf, max_iter=-1, probability=False,
# random_state=None, shrinking=True, tol=0.001, verbose=False)
# ガウシアンカーネルによる SVM が返却された。
前回、前々回とあわせてまたも駆け足でサポートベクトルマシンをいじり倒しました。次回からは分類器の王道、多項分布モデルをベースとしたベイズ分類について話を進めていきます。