Apexデータローダーとは?
Salesforceに大量のデータをアップロードするときによく使うのがApexデータローダーです。
データローダーの基本知識についてはテラスカイさんのこちらの記事とかをご参照ください。
マニュアルはこちら。
ちょっと融通が効かないよね
さて、色々便利に使えるデータローダーですが、いまいち融通が効かない点があります。
- 区切り文字はカンマ(CSV)、または、タブ(TSV)のみ
- 先頭行はフィールド名を含むヘッダ行でないといけない
- 日付・時刻の形式に制限がある
- 一部のレコードのみを選択的にロードできない
で、アップロードするデータファイルを自分で自由に作れるのなら、データローダーが受け入れてくれる形式で作ればよいのですが、既存システム連携などで既に決められた形式がある場合などは、フォーマット変換とか不要なレコードの削除とかをしてあげないといけないわけです。
実際に私が経験したのは、こんなファイルでした。
- ヘッダ行なし。1行目からいきなりデータ
- 固定長。区切り文字はない
- 全部で500万件。ただしロードする必要があるのは300万件のみ
- 500万件が、ファイル名に連番を含む複数のファイルに分割されている
JavaやVBAやRubyなどのプログラミング言語を使って自前で書きますか?
Salesforceプロジェクトであれば、ほとんどのコードはApex/Visualforceで書かれるというのに、変換やフィルターや結合のために別の言語を導入しなければならないのはちょっと嫌ですね!?
それにこれだけ件数が多いと、処理時間も結構かかります。
お金があればETLツールとか買えばいいですが、それなら最初からデータローダーとかいらないわけです。
バッチモード・・・!?
ところでデータローダーには「バッチモード」というのがあります。
事前に設定ファイル、マッピングファイル、データファイルを用意しておき、コマンドラインからデータローダーを起動したら、後は終わるのを待つだけ。
同じフォーマットのデータを定期的にアップロードする必要がある場合などに便利です。
で、そのバッチモードなんですが、GUIのインタラクティブモードにはない機能を持っています。
それは、アップロードデータをJDBC経由でデータベースから読み込む機能です。
ふーん、それなら区切り文字もヘッダー行も関係ないね・・・ん? ローカルのデータファイルにJDBCでアクセスできれば、変換なしで色んなフォーマットのデータファイルを読み込めるんじゃない?
CsvJdbc
探してみるとあるものです。それがCsvJdbc。
CsvJdbc is a read-only JDBC driver that uses Comma Separated Value (CSV) files or DBF files as database tables. It is ideal for writing data import programs or analyzing log files.
これを使うと、様々な形式のファイルをJDBC経由で読み込むことができます。
例えばこんなことができます。
- ヘッダー行の有無。ない場合の各フィールドの名前
- 区切り文字。または固定長の場合の各フィールド長
- 複数ファイルの一括読み込みとファイル名パターン
- 日時フォーマット
- SQLによるフィルター(WHERE句)や演算
データローダーの実体はJavaプログラムです。
なので、データローダー実行時のCLASS_PATHにCsvJdbcのjarファイルをインクルードしてあげれば、両者を組み合わせることができます。
では、実際にやってみましょう。
下準備
前提とするデータフォーマット
今回は取引先オブジェクトに、次のような固定長フォーマットのデータをロードしてみます。
| 桁 | 対応するAccountフィールド | 備考 |
|---|---|---|
| 1-10 | AccountNumber | 取引先番号 |
| 11-30 | Name | 取引先名 |
| 31-43 | Phone | 電話 |
| 44-44 | なし | フィルター用。Yなら取り込む、Nなら取り込まない |
全5レコードを、2ファイルに分割して保存します。
1111111111Salesforce.com 03-1111-1111 Y
2222222222Oracle 03-2222-2222 N
3333333333IBM 03-3333-3333 Y
4444444444SAP 03-4444-4444 N
5555555555Microsoft 03-5555-5555 Y
この2つのファイルが結合され、最後のフィールドが"Y"のレコードのみがフィルターされ、3レコードのみがロードされる、というのが期待する結果です。
cliqでバッチ実行をセットアップ
さっき紹介した記事でも紹介されているCLIqを使って、まずは普通にこんなCSVファイル(↓)を使ってバッチ実行できるようにします。
AccountNumber,Name,Phone,IsValid
1111111111,Salesforce.com,03-1111-1111,Y
2222222222,Oracle,03-2222-2222,N
3333333333,IBM,03-3333-3333,Y
細かい手順は省きますが、今回はCsvJdbcTestというProcess Nameでバッチを作成しました。
マッピングファイルはこれです。
Name=Name
AccountNumber=AccountNumber
Phone=Phone
この時点では当然ながら4列目のIsValidでのフィルターは効かず、3件全てがロードされます。
正しくバッチロードできることを確認したら、いよいよ本題に入っていきます。
(ロードしたレコードは消しておきましょうか)
いよいよCsvJdbc + データローダー
CsvJdbcのインストール
CsvJdbcのダウンロードページから、CsvJdbcのjarファイル(csvjdbc-version.jar)をダウンロードします。
ダウンロードしたjarファイルは、データローダーのマニュアルに従い、データローダーのインストールフォルダの下のjava/binに保存しておきましょう。
process-conf.xml
process-conf.xmlのdataAccess.nameとdataAccess.typeの設定を変更します。
変更前
<entry key="dataAccess.name" value="C:¥path¥to¥CsvJdbcTest.csv"/>
<entry key="dataAccess.type" value="csvRead"/>
変更後
<entry key="dataAccess.name" value="queryAccount"/>
<entry key="dataAccess.type" value="databaseRead"/>
変更前はデータをCSVファイルから読み込むことと、そのファイルのパスが指定してありました。
変更後はデータをデータベースから(JDBC経由で)読み込むことと、その際に利用するデータベース設定を指定します。データベース設定はdatabase-conf.xmlというファイルに書きます。
database-conf.xml
まずは何も言わずに次の内容で作成してください。
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="dbDataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="org.relique.jdbc.csv.CsvDriver"/>
<property name="url" value="jdbc:relique:csv:data_file_dir?fileExtension=.txt&indexedFiles=true&fileTailPattern=_\d%2B&suppressHeaders=true&fixedWidths=1-10,11-30,31-43,44"/>
</bean>
<bean id="queryAccount"
class="com.salesforce.dataloader.dao.database.DatabaseConfig"
singleton="true">
<property name="sqlConfig" ref="queryAccountSql"/>
<property name="dataSource" ref="dbDataSource"/>
</bean>
<bean id="queryAccountSql"
class="com.salesforce.dataloader.dao.database.SqlConfig" singleton="true">
<property name="sqlString">
<value>
SELECT COLUMN1 AccountNumber, COLUMN2 Name, COLUMN3 Phone FROM CsvJdbcTest WHERE COLUMN4 = 'Y'
</value>
</property>
<property name="columnNames">
<list>
<value>AccountNumber</value>
<value>Name</value>
<value>Phone</value>
</list>
</property>
</bean>
</beans>
CsvJdbcTest.batのあるフォルダーの直下にdata_file_dirというフォルダーを作成し、先ほどの2つのデータファイルをそこに保存してください。
それからCsvJdbcTest.batを実行すれば、データがロードされるはずです。
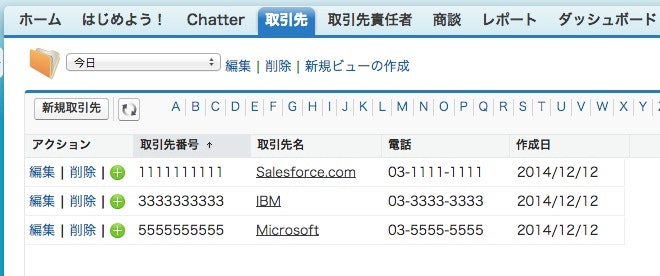
では、database-conf.xmlの肝となる部分を説明します。
JDBCドライバー設定
以下の箇所でドライバーの設定を行っています。
<property name="driverClassName" value="org.relique.jdbc.csv.CsvDriver"/>
<property name="url" value="jdbc:relique:csv:data_file_dir?fileExtension=.txt&indexedFiles=true&fileTailPattern=_\d%2B&suppressHeaders=true&fixedWidths=1-10,11-30,31-43,44"/>
driverClassNameはCsvJdbcのドライバークラス名です。
次の行は接続文字列(URL)です。
最初のjdbc:relique:csv:はCsvJdbcを使うときの固定の文字列です。
次のdata_file_dirは、データファイルの保存ディレクトリです。
SELECT文のFROM句で指定されたテーブル名と同じ名前持つデータファイルが、読み出しの対象となります。
その後ろはドライバープロパティで、URLエスケープされているのでちょっと読みづらいですが、まとめるとこうなります。
| プロパティ名 | 値 | 意味 |
|---|---|---|
| fileExtension | .txt | データファイルの拡張子は".txt" |
| indexedFiles | true | テーブル名と次のfileTailPatternの正規表現にマッチする名前を持つ全てのファイルを結合して単一のファイルとみなす |
| fileTailPattern | _\d+ | ファイル名末尾がこの正規表現にマッチする一連のファイルを結合 |
| suppressHeaders | true | データファイルにはヘッダ行がない |
| fixedWidths | 1-10,11-30,31-43,44 | データファイルは固定長で、各フィールドの桁範囲を示す |
CsvJdbcでは他にも様々なプロパティを使って設定ができます。
詳しくはこちらを参照してください。
SQL
みんな大好きSQLです。
<value>
SELECT COLUMN1 AccountNumber, COLUMN2 Name, COLUMN3 Phone FROM CsvJdbcTest WHERE COLUMN4 = 'Y'
</value>
fixedWidthsパラメータで4つの列があることを示しましたが、先頭からCOLUMN1、COLUMN2・・・という列名で参照できます。
headerlineというプロパティを使うと、自分で分かりやすい列名を指定できるのですが、なぜか今回は時間内にエラーを解消できませんでした。前はうまくいったんですがね。
またWHERE句でフィルターを指定している点にも注目してください。
これで一部のレコードのみを選択的にロードできます。
他にも算術演算や関数、GROUP BY句をサポートしています。
マッピング
この<value>要素は、先頭から先ほどのSQLの選択列リストに対応します。
<property name="columnNames">
<list>
<value>AccountNumber</value>
<value>Name</value>
<value>Phone</value>
</list>
</property>
たぶんデータローダーのマッピングファイル(.sdl)で参照される名前がこれなんじゃないかと。
まとめ
CsvJdbcとデータローダーを組み合わせると、データファイルの結合、フィルター、変換などの操作を、ノンプログラミングで実現することができます。
ETLとかESBとかEAIとか買うほどじゃないけど、自前で変換プログラムを組むのも手間、という場合には強力な武器になるんじゃないでしょうか。
皆さんもぜひ活用してみてください。
おまけ
12/2に @stomita さんがFreeeのデータをLightning Connect経由でSalesforceタブに表示するという記事を書いてくれて、freeeで働く者として大変ありがたく思っているのですが、念のため補足させていただくと Freee じゃなくて freee です。
どうぞお間違えのないようお願いいたします。m(_ _)m