こんにちは、freeeでエンジニアをしている@yebiharaです。
この記事はfreee Engineers Advent Calendar 2015の22日目です。
皆さんの中には「マイクロサービスアーキテクチャ」という言葉を聞いたことがある方も多いと思います。
James LewisとMartin Fowlerによるブログ記事 Microservices(日本語訳)により、急激に広まった感のあるこの言葉ですが、マイクロサービスそのものについて書き始めると長くなり過ぎてしまうので、この記事では触れません。
さて、freeeのアーキテクチャもマイクロサービスを意識しています。
粒度についてはサービスによってマチマチで、必ずしも「マイクロ」とは言えないものもありますが、いずれにしても異なる機能を提供する複数のサービスをAPIで統合することにより、freeeのシステムは成り立っています1。
この記事ではそのようなシステムの開発・運用を行ってきた中で感じた、マイクロサービスアーキテクチャ、またはサービス分割のメリット・デメリットとともに、どのようにしてデメリットを克服できるのかを考察してみたいと思います。
サービス分割のメリット
我々がfreeeを開発・運用する中で感じているメリットとして、以下のようなものが挙げられます。
開発生産性
各サービスの規模はコンパクトになるので、全体の理解が容易です。
API仕様の互換性を崩さない限りは、変更の影響範囲が小さくなるので、大胆な改善やリファクタリングもやりやすいですし、新たに関わることになったメンバーも高速にキャッチアップできます。
サービス単体のビルドやテストにかかる時間も短くなるので、リリースサイクルを高速化することができます。
開発に携わるチームのサイズもコンパクトになるので、コミュニケーションオーバーヘッドも小さくなることが期待できます。
異なるテクノロジーの共存
サービス毎に異なるテクノロジーを採用するのが容易です。
テクノロジー、プログラミング言語、フレームワークにはそれぞれ得手不得手がありますが、それらを適材適所で利用することができますし、最新テクノロジーも導入しやすいです。
もっともfreeeでは、どんどん新しいテクノロジーが導入されるので(特にフロントエンドまわり)、キャッチアップが大変、という声も聞かれます。
効率の良いスケーラビリティ
サービスが適度に分割されていれば、システム全体により高い性能が求められる場合に、ボトルネックとなっているサービスに絞ってリソースを増強することで、効率よく性能を向上させることができます。
ただし、システム全体を構成する各サービスがスケールアップにせよスケールアウトにせよ、十分なスケーラビリティを持っていることは前提になります。
運用の独立性
メンテナンスやデプロイをサービス単位で行うことができるので、新機能やバグフィックスを短いサイクルでリリースできますし、サーバーやネットワークの設定変更や再構成のようなインフラ作業も大規模にはなりにくいです。
また、一部のサービスで障害が発生しても、他のサービスは引き続き稼働し続けられたりもします。
一方で、サービス間に依存関係がある場合も多いので、完全に独立に運用できるわけではなく、特に認証のような共通サービスについては他サービスに与える影響を慎重に検討する必要があります。
サービス分割のデメリット
一方でサービスを分割することにはデメリットもあります。
システム全体を理解するのが困難
全部でどれだけのサービスがあり、それぞれがどのような役割を担っているのかといった基本的なことですらよく分からなくなりますし、それらがどのように協調動作しているのかを理解することはより困難です。
ましてや各サービスの実装詳細についての理解は言わずもがな。特にサービスによって異なるテクノロジーを採用していたりするとそれは顕著になります。
設計・実装の一貫性を維持しづらい
サービスの設計者はそれぞれ異なることも多いですし、そもそもベーステクノロジーが違っていたりもするので、設計や実装は自ずとサービス毎に独自性を持ち始めます。
また、統一的で一貫性のあるUI/UXを提供することすら困難になりがちです。
構成の複雑化
特に場当たり的にサービスを増やしていった場合など、Wikipedia ネットワーク・トポロジーで説明されるところの「フルコネクト型」に近い構成になり、運用・管理も大変になります。
リモートデータベースアクセス
freeeでは主にRuby on Railsを使ってサービスを開発しています。
そしてデータベースにはもちろんActiveRecordでアクセスしています。
面倒なのは他のサービスが持っているリモートデータベースへのアクセスです。
リモートデータベースにアクセスするには、そのデータベースを「所有」しているサービスのAPIを経由します。
そのため、あのシンプルで強力なActiveRecordを使う代わりに、APIにアクセスする大量のコードを書かないといけません。
もちろんRESTfulの流儀に従ってAPIを設計することで、特に単一テーブルに対する基本的なCRUD操作であればコードの共通化・簡素化を図ることはできますが、複数テーブルにまたがる関連データを一括取得したくなったりすると、APIのカスタムメイド化は避けられません。
また、複数のテーブルが同じリモートデータベースに存在していれば、APIではそれらを結合(Join)するクエリーを実行した結果を返すことで性能を最適化することができますが、もしそれらが異なるデータベースに存在するテーブルだったらどうなるでしょう?
何も考えずに実装すると、N+1クエリー問題のAPIコール版が発生することになりかねませんし、それを避けるためにActiveRecordのpreloadのような最適化を行おうとすると、API側もクライアント側も実装が複雑化します。
トランザクション
データベースに関連してもっと困るのはトランザクションです。
更新対象が複数のデータベースにまたがると(分散トランザクション)、途端に管理が難しくなります。
特に障害発生時のリモート処理のロールバックというのは、一般的にはうまく扱うのが非常に難しいです。
それでもローカル更新処理とリモート更新処理に順序的な依存関係がない場合や、ローカル更新を先に行わなければならないケースにはベストプラクティスがあります。
まず最初に、問題発生時には確実にロールバックできるローカルDBへの更新処理をすべて実行してしまいます。それらがすべて成功したら、リモート更新処理(POSTやPUTなどの更新系APIコール)を実行します。
成功したらローカルトランザクションをコミットし、失敗したらロールバックします。
リモートコール後には、一切の更新処理(ローカルもリモートも)を行ってはいけません。
しかしこの手法も、リモート更新コールのレスポンスをローカルDBに書き込む必要があるなど、リモート更新処理をローカル更新処理よりも先に実行しなければならない場合や、更新対象のリモートシステムが2つ以上存在する場合には使えません。
ヒントはエンタープライズの世界に?
実のところ、ここまでに挙げたような状況というのは、エンタープライズシステムの分野では昔から普通に見られたものばかりです。
企業の中には会計、生産、受発注といった複数のシステムが存在しています。それぞれ異なるベンダーのパッケージ製品を採用していたり、COBOLやJavaでカスタム開発したりと、様々なテクノロジーが混在している状況も珍しくありません。
その一方で、それらは相互に連携・データ交換を行っています。
その実現を容易にするために生まれたのがEAIやESBといったテクノロジー/製品です。
各システムはある程度独立に開発・運用されている点や、それに伴うデメリットも相似形です。
分散トランザクションの問題は、X/Open XAインタフェースによる分散トランザクションマネージャーや、SOAPベースのWS-Transactionなどで解決が図られました。
ただ、我々freeeを含むWebサービスにとって、これらエンタープライズ分野で出てきたソリューションがどれだけ役に立つのかと言うと、ヒントにはなるが直接的な解決にはならない、と個人的には思っています。
商用プロダクトで初期コストがかかるとか、自由度が低いとかもありますし、そもそもWebサービス企業は重厚なソリューションをあまり好まないというのがその理由です。
もちろん全てはバランスの問題なので、そのようなソリューションが必要とされるケースもあるでしょうが、たぶんfreeeではないんじゃないかと思います。
じゃあちょいと自分で考えてみるか
というわけで、どのように課題を解決するかを考えてみたいわけですが、全ての課題について考えるのは辛いので、自分が最も興味あるデータベースとトランザクションの問題に絞りたいと思います。
モノリシックデータベース
マイクロサービスの反対語は「モノリシックサービス」です。
全ての機能が単一のシステムに詰め込まれた、一枚岩的な大きなサービスです。
「モノリシックデータベース」というのは、サービスそのものは分割しつつ、データベースだけは単一のものを共有するというアイディアです。
サービスを分割すると、典型的にはデータベースも分割されます。
そして、他サービスが持つDBにアクセスしたければ、そのDBを持つサービスにAPIコールします(下図)。
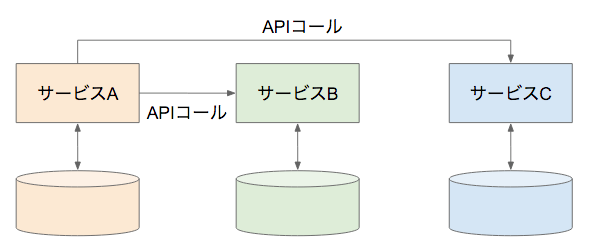
モノリシックデータベースでは、全てのサービスのテーブルはひとつのデータベースに保管されます。
テーブルの中には単一のサービスによってしかアクセスされないものもありますし、複数のサービスからアクセスされるものもあります(下図)。
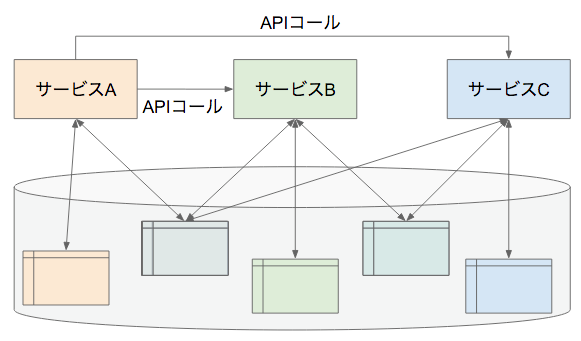
メリット
各サービスは全てのテーブルに対してローカルアクセスできるようになります。
Railsベースのサービスであれば、例えばusersテーブルにアクセスする必要のある全てのサービスでUserモデルを定義することにより、ActiveRecordクエリーでユーザー情報を操作することができるのでAPIプログラミングは不要になりますし、全ての更新はローカルDB処理になるので分散トランザクションの問題も発生しません。
もしサービス間で処理を共通化したい場合、(モノリシックDBのメリットが薄れるものの)APIコールの併用は依然として可能ですし、ActiveRecordのモデルクラス自体をGem化して各サービスにインストールするというやり方も考えられます。
デメリット
データベースサイズが非常に大きくなることと、全てのサービスからのトランザクションが単一のDBに集中することを考えると、システム性能を維持する難易度は上がるでしょう。
Railsで言えば、マイグレーションを実行する時間も長くなる可能性があり、運用管理のスケジュールにもより気を遣う必要があります。
また、構成によってはデータベースが単一障害点となり、耐障害性が低下することになります。
ただ、世界有数(最大?)の規模のSaaSを提供するSalesforceも、インスタンス単位で見れば(クラスタリングされた)単一データベース上で運用されているので、モノリシックデータベースでも十分なサービスレベルを達成することは不可能とは言えないでしょう。
テーブル単位のレプリケーション
巨大なモノリシックデータベースはやはり何かと心配になるかもしれません。
そもそも他サービスのDBにあるテーブルのうち、実際にアクセスしたいテーブルはほんの一部であることがほとんどでしょう。
もし分散トランザクションがそれほど問題にならない場合には、テーブル単位のレプリケーションによってAPIプログラミングの手間を減らすことができるかもしれません。
つまり、リモートデータベースにあるテーブルのうち、ローカル(ActiveRecord)アクセスしたいテーブルのみを、ローカルDBにレプリケートするのです。
例えばMySQLでは--replicate-do-tableオプションなどを使ってテーブルレベルレプリケーションを設定することができます。
ただし完全同期でないレプリケーションでは、最新のデータへのアクセスが保証されない点には注意が必要です。
データベースリンク
データベースリンクというのは元々はOracle用語ですが、ここではより汎用的に、データベース内に他のデータベースへの接続情報を事前定義しておき、SQLから透過的にリモートDBへのアクセスを可能にする技術、としておきます。
例えばOracleの例だと、select ... from remote_table@remote_dbのような記法でリモートテーブルをクエリーすることができます。OracleのDBリンクはなかなか優秀で、ローカルDBとリモートDBの更新を自動的にグローバルトランザクションにして二相コミットしてくれます。
PostgreSQLにもdblinkという似たような機能があります。
調べてみたらdblink_plusという二相コミットをサポートしたやつもあるんですね。詳しくは知りませんが。
MySQLだとFEDERATEDストレージエンジンというやつが類似しているという情報がありますが、どれくらい使われている機能なんでしょうか?
いずれにせよ、DBリンク(に類似した技術)を使うと、ローカルDBに発行したSQLでリモートDBにアクセスできることになるので、うまいことやればActiveRecord経由でリモートテーブルにアクセスできそうです。
PostgreSQLやMySQLはそれ自体は二相コミットをサポートしているし、オープンソースなので、自前で素敵なDBリンクを作るなんて選択肢もあるかもしれませんね!?
おわりに
というわけでまだ答えのない考察をしてみたわけですが、いかがでしたでしょうか。
実はわたくし、freeeのエンジニアメンバーの中では最年長です。
freeeには、意欲さえあれば年齢に関わらずプログラマー/エンジニアとして活躍できる場が用意されています。
豊富な経験と高いスキルを持ち、自分はまだまだ現役でやりたいんだ! という思いをお持ちのあなた!
freeeの最年長エンジニアになりませんか!?
急成長を続けるfreeeのシステムを支えるアーキテクチャーを一緒に考えてみませんか!?
さて、明日はfreeeのコードクォリティーを守る最後の砦、神出鬼没のレビューコメントで糞コードを斬りまくるレビュー侍 @nanjakkun です。
ちなみに弊社のUXエンジニアの @ymd が明日どっかのAdvent CalendarでUXに関する何かを書くという未確認情報がありますので、詳細が分かったら追記します。 → (追記)Sketch 3 Advent Calendar 2015 23日目 「freeeでのSketch運用の実態」
-
この辺りはWEB+DB PRESS Vol.82でも一部を紹介していますので、興味ある方はご覧になってみてください。 ↩