2017年11月1日追記
[Watson] Retrieve and Rankのサービス終了について
概要
自然言語での質問に対して適切な回答を返す「質問応答システム」は、Watsonの最も得意とする分野です。
質問応答システムでは主にRetrieve and Rankサービス(以下R&R)を利用します。
R&Rは機械学習をベースとしたサービスであり、サービス利用者がデータを準備して学習(トレーニング)させる必要があります。
従来は、curlコマンドやPythonスクリプトを実行してトレーニングする必要がありました。
現在では、Retrieve and Rank Web interfaceというブラウザベースの公式ツール(以下公式ツール)を利用することで、視覚的にトレーニングが可能になっています。
本稿では、ツールを利用してR&Rのトレーニングを行い、簡単な質問応答システムを作るまでの手順をシリーズ化して解説します。
(1) R&Rおよび公式ツール利用開始〜回答データ投入 ※この記事で説明する部分
(2) 質問データ投入〜Rankerトレーニング
(3) Node-REDアプリケーションとR&Rの連携
免責事項
本稿におけるWatsonサービスに関する解説は執筆者の個人的な見解であり、公式資料に基づいていない内容を含みます。
また本稿の情報は2017年4月現在のものです。
必ずWatson Developer Cloudなどの公式資料も併せて確認してください。
Retrieve and Rankの全体イメージ
R&Rは2つのコンポーネントを組み合わせてサービスを構成しています。
- Apache Solr : オープンソースの全文検索エンジン
- Ranker : 機械学習アルゴリズムを使用して関連性の高い回答を導き出す仕組み
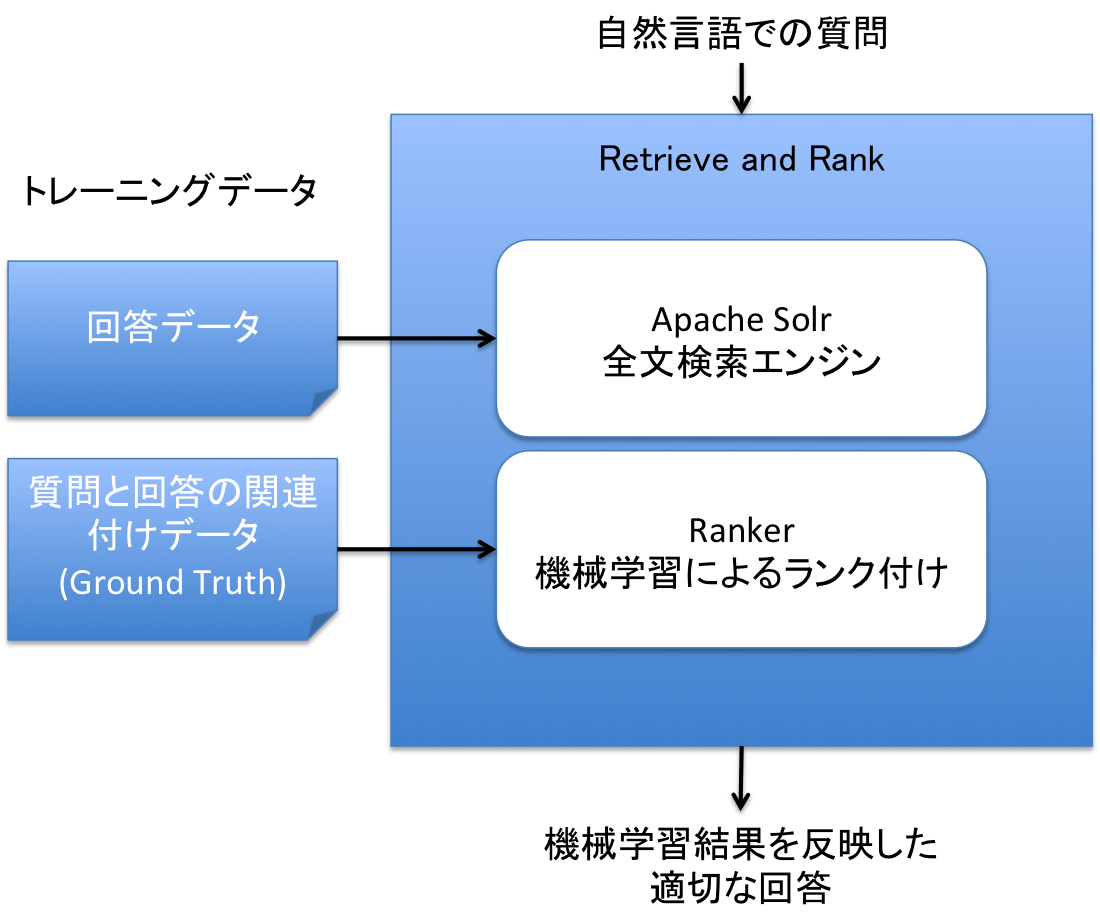
R&Rを利用する上で、この全体像の理解は非常に重要です。
準備
Bluemixアカウントが必要です。
まだお持ちでない方は、簡単にフリートライアルアカウントを取得することができますので、こちらを参照してください。
Bluemix の基礎: フリートライアルを開始する - IBM developerWorks
R&Rの利用開始
R&Rをサービス追加
Bluemixダッシュボードで「サービスの作成」ボタンをクリックすると、以下のような画面になります。
カテゴリーから「Watson」-「Retrieve and Rank」を選択します。
以下の画面で「作成」をクリックします。
Document Conversionをサービス追加
公式ツールを利用する場合は必須ですので、R&Rと同じように追加します。
公式ツールを起動
Bluemixダッシュボードの「すべてのサービス」にてR&Rを選択すると、以下の画面に遷移します。
「Launch tooling」をクリックすると公式ツールが起動します

「Connect to service」をクリックします。
クラスタ名を指定して「Create」クリックします。
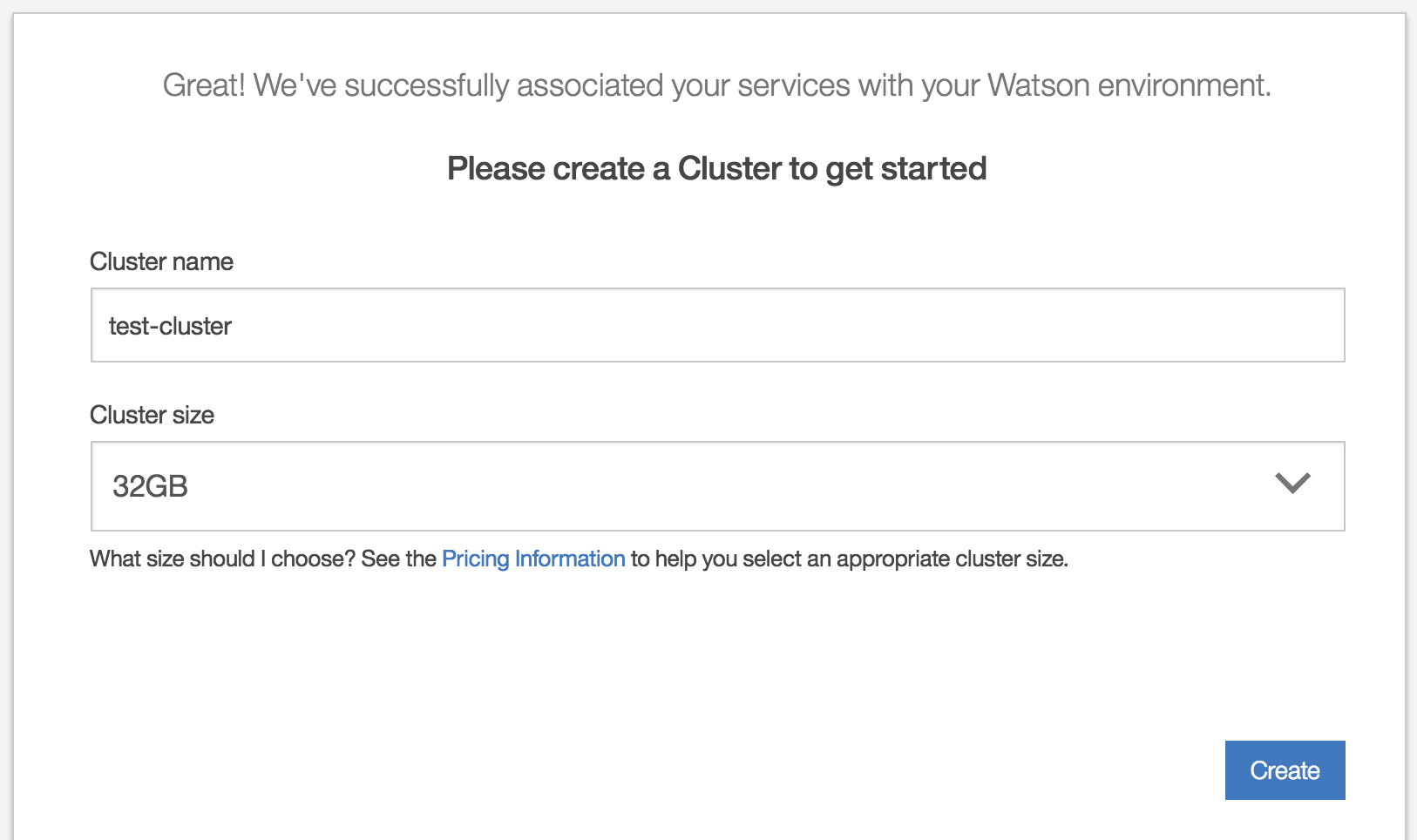
以下の画面に遷移しますが、裏で走っているSolrクラスタ作成処理が完了するまで「Create a new collection」ボタンが押せません。
途中ヘッダーにエラーっぽい表示がでますが、そのうち消えますので気にせず待ちます。
ボタンが有効になったらクリックします。
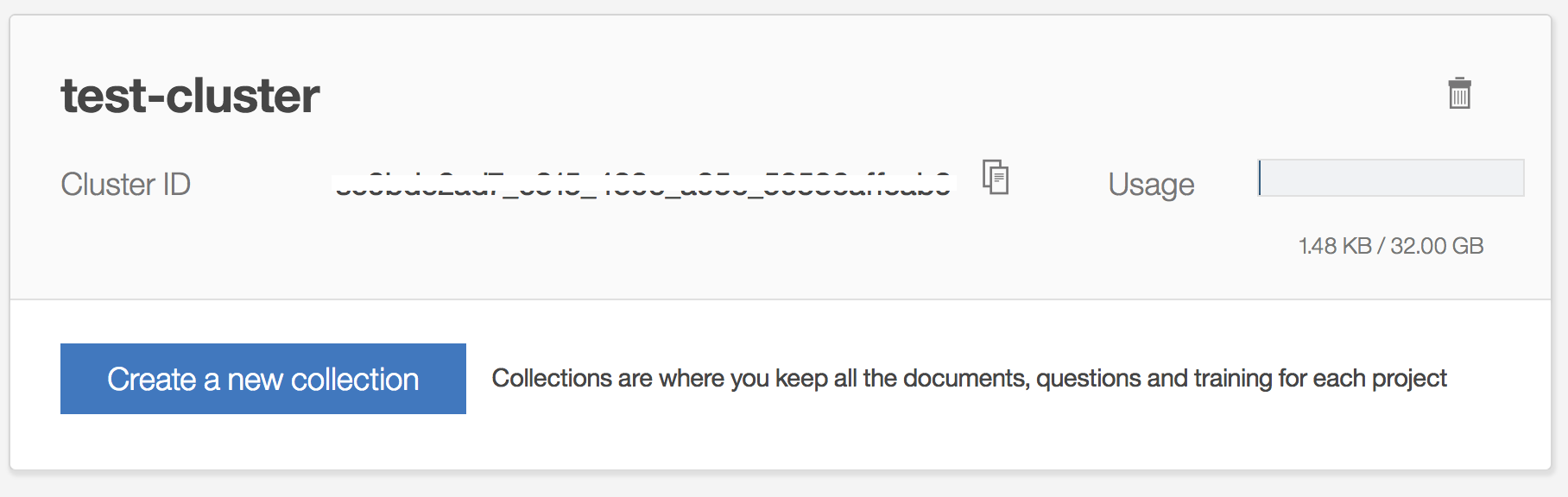
Solrコレクション名と言語を指定して「Create」ボタンをクリックします。
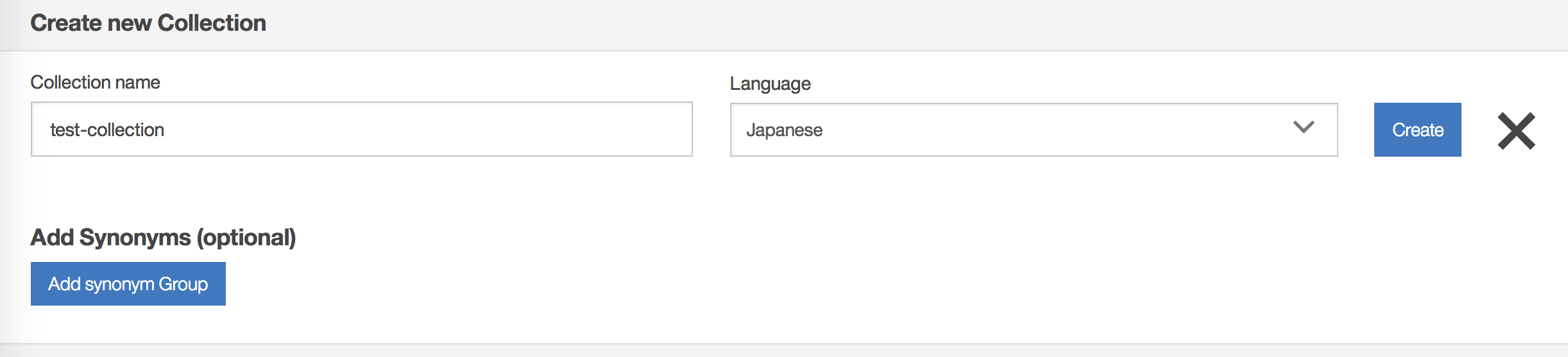
Solrコレクションの作成が完了すると以下の画面に遷移します。
作成したコレクションの「→」をクリックします。
チュートリアルの選択が表示されます。今回は「Start using Watson」を選択します。
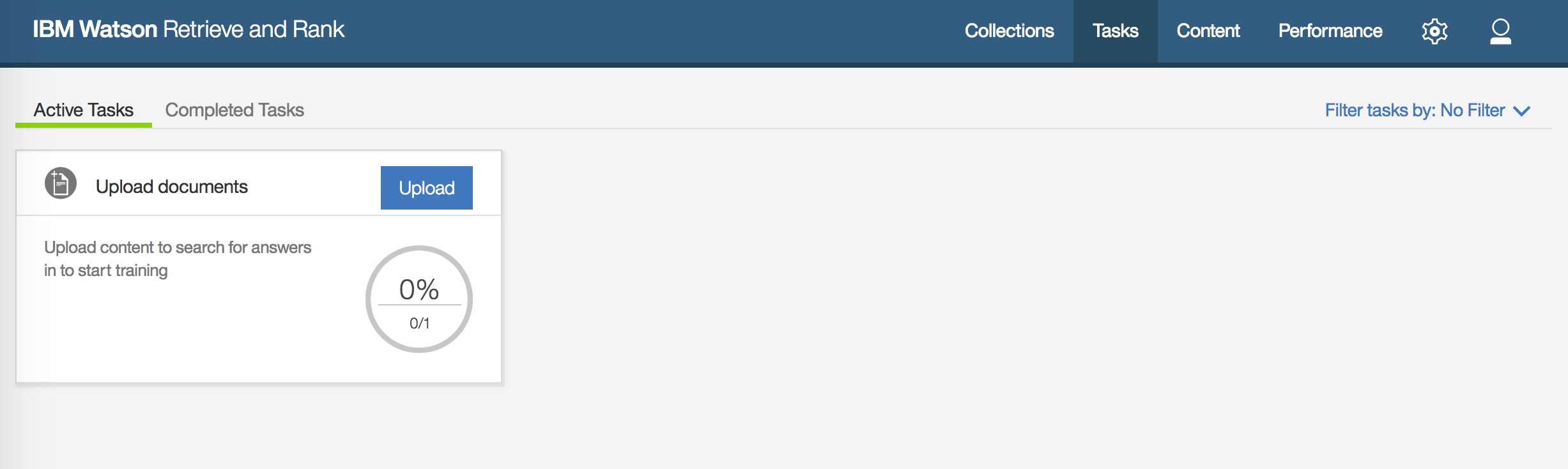
以下のような画面に遷移します。
「Upload」ボタンにて回答データ(正確にはSolrコレクションドキュメント)をアップロードするわけですが、当然、データを準備しなければなりません。
ブラウザでの作業はここで一旦中断し、データを準備します。
回答データの準備
公式ツールからアップロードできる回答データの形式は、PDF、Word、またはHTMLです。
本当はFAQのような、質問と回答がセットになっており、しかもそれなりの数が揃った文書が入手できれば一番なのですが、一個人では著作権の問題もあり、なかなか難しいです。
というわけで私の場合はDBpediaから「北海道の観光地」の一覧を取得してソースとしました。
DBpadiaのエンドポントにアクセスし、以下のクエリを実行します。
prefix dbp: <http://ja.dbpedia.org/resource/>
prefix dbp-owl: <http://dbpedia.org/ontology/>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?title, ?comment
WHERE {
dbp:北海道の観光地 dbp-owl:wikiPageWikiLink ?thing.
?thing rdfs:label ?title.
?thing rdfs:comment ?comment.
}
こんな感じでtableが表示されるので、これを二次加工します。

ブラウザの機能でソースを表示し、テキストファイルとして保存します。
この際、タイトルを<h1>タグ、回答文を<p>タグにするところがポイントです(後述)。
<!DOCTYPE html>
<html>
<!-- 以下抜粋 -->
<h1>小樽運河</h1>
<p>小樽運河(おたるうんが)は、北海道の小樽市にある運河。大正12年(1923年)に完成した。</p>
<h1>層雲峡</h1>
<p>層雲峡(そううんきょう)は、北海道上川町にある峡谷である。大雪山国立公園に位置し、石狩川を挟み約24kmの断崖絶壁が続く。大雪山黒岳山麓にある層雲峡温泉は大型ホテルなどが立ち並ぶ北海道有数の規模を誇る温泉街で、層雲峡および大雪山観光の中心地となっている。</p>
<h1>野寒布岬</h1>
<p>野寒布岬(のしゃっぷみさき)は、北海道稚内市ノシャップにある岬。「ノシャップ岬」とカナで表記することも多い。日本海から宗谷湾を区切る。</p>
<h1>摩周温泉</h1>
<p>摩周温泉(ましゅうおんせん)は、北海道川上郡弟子屈町にある温泉。</p>
</html>
ファイルをUTF-8のHTMLファイルで保存します。
これで回答データの準備は完了です。公式ツールの作業に戻ります。
回答データのアップロード
以下の画面で「Upload」ボタンをクリックします。
以下のダイアログで、先ほど作成した回答データのHTMLファイルを指定し、アップロードします。
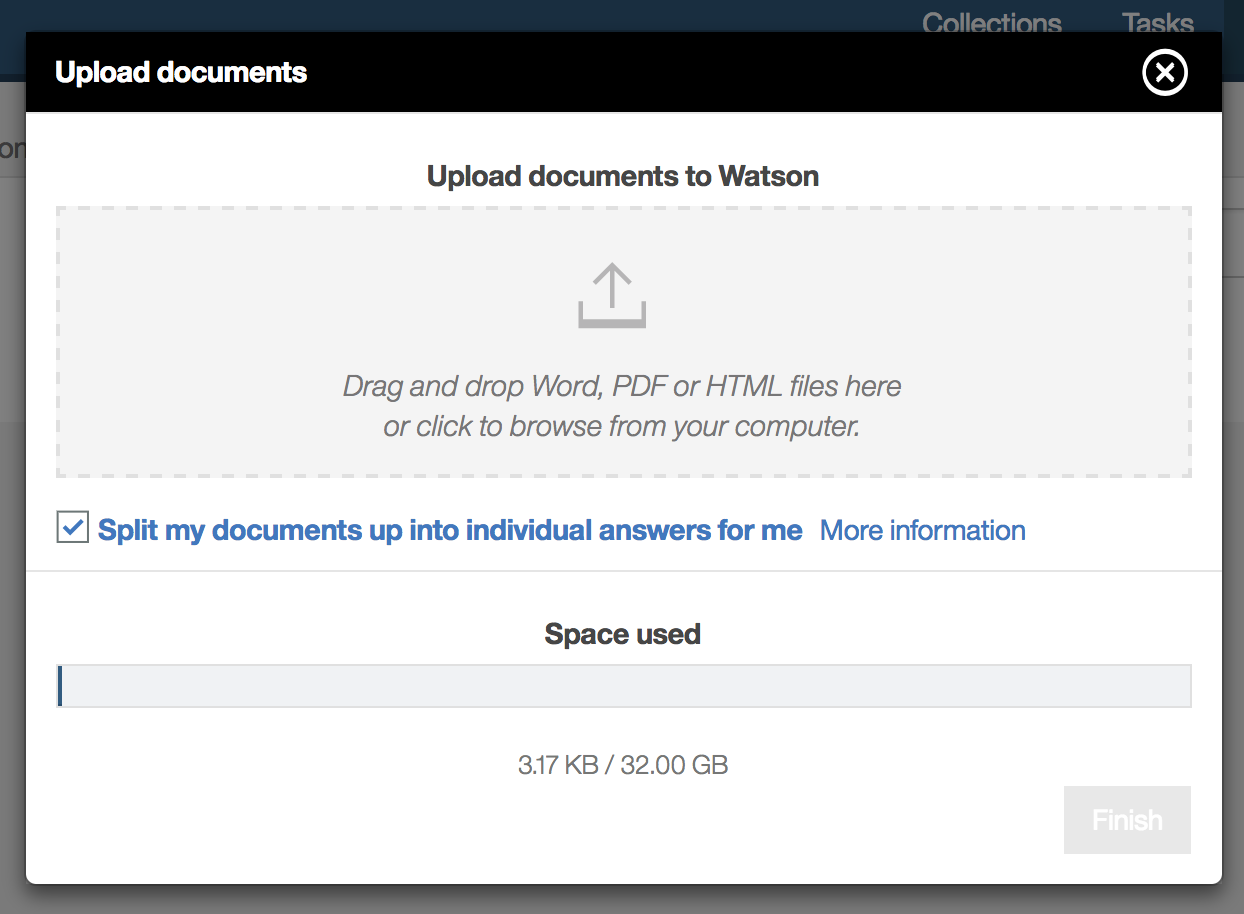
「Split my documents ...」のチェックボックスに注目してください。
前述の通り、HTML内の個々の文章に<h1><p>タグをつけ、このチェックボックスをオンにすることで、個別の回答文として分割されます。
そうでない場合は、ドキュメント全体が一つの回答文と扱われます。
アップロードが完了すると以下の画面に遷移します。
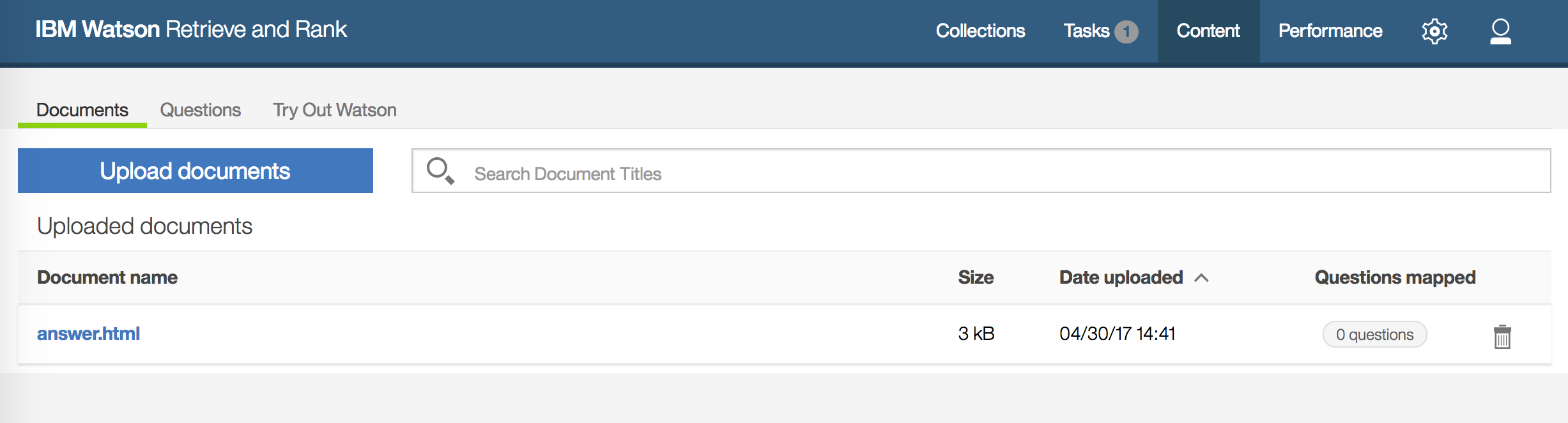
ここまでの作業により、Solrコレクションが完成したことになります。
「Try Out Watson」タブでは、Solrによる全文検索を試すことができます。
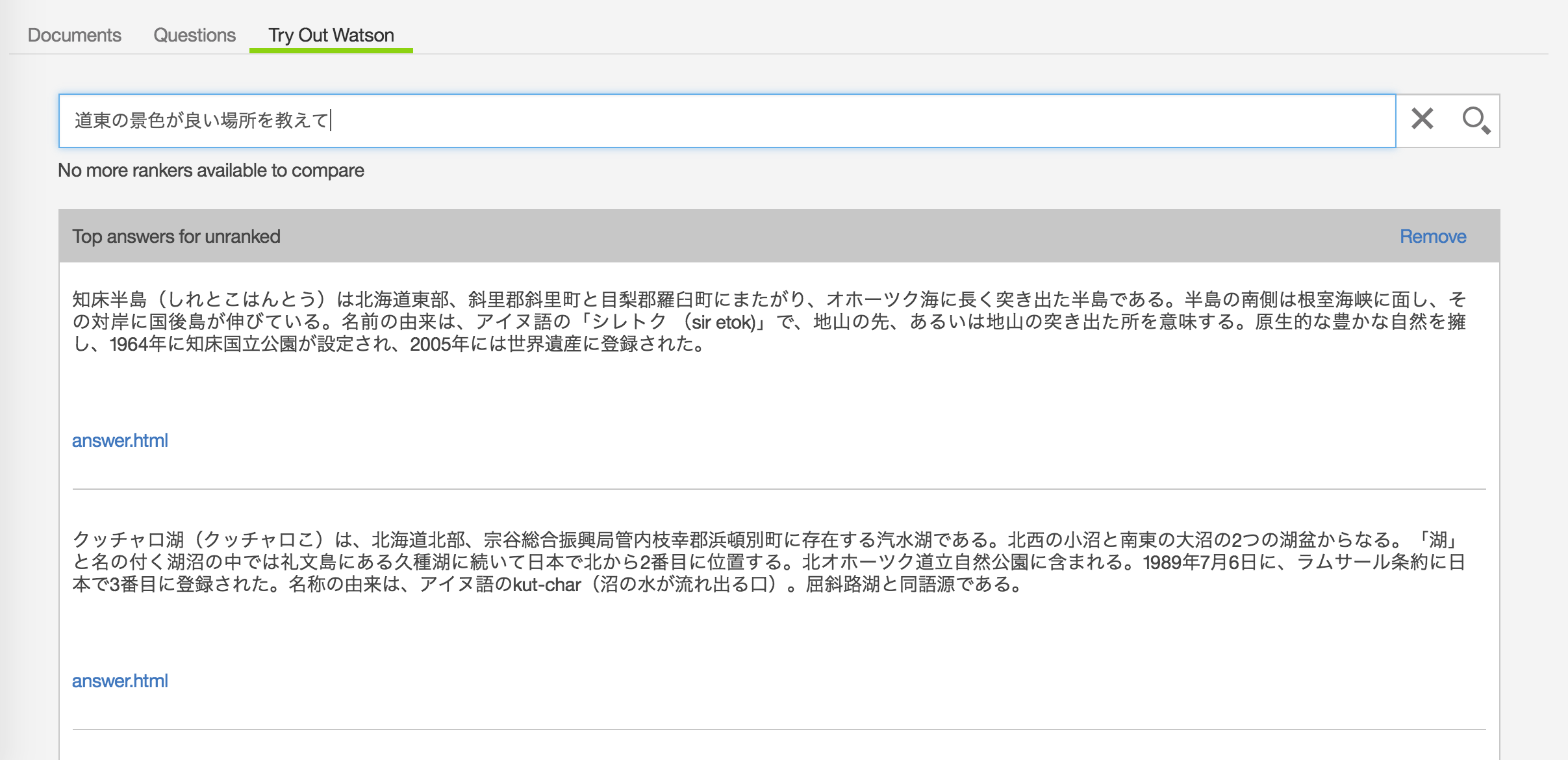
ただしここでの検索結果は、Solrのみによる検索結果です。
これに対してランク付けを行い、期待通りの回答になるように改善できるのが、Retrieve and Rankのミソです。
次回の記事では、質問文の投入と、回答のランク付けの作業を行っていきます。