HiveQLではスピードに難を感じていたため、私もPrestoを使い始めました。
MySQLやHiveで使っていたクエリを置き換える時にハマったTipsをまとめていきます。
執筆時点で最新版であった、Hive4 (Hive 2023.1)と、Presto 350を想定しています。
AWS AthenaでPrestoを使っている方も増えてると思うので、Presto標準関数での記述例も拡充していきます。
Prestoとは
Prestoはオンメモリで動く分散SQLエンジンで、その進化は目を見張る物です。
発表された当時は色々な成約があり使うことを躊躇していましたが、2015年頃からはもう使わない理由はなくなりました。
アドホックに使えるとても高速なSQLエンジンですので、バッチ向けのHiveのように実行結果を待つ時間はほとんどありません。
Hiveですと1つ1つの実行に時間が掛かるので、クエリに慣れていない新参者には辛い物がありました。
しかしPrestoではインタラクティブに実行できますので、トライ&エラーを繰り返しやすい点が良いですね。
また、JDBCドライバ経由でBIツールとPrestoを接続すれば、さらなる価値を見いだせるでしょう。
ハマりやすい挙動の違い
ダブルクォートとシングルクォート
MySQLやHiveではあまり意識することはありませんが、標準SQLを採用するPrestoでは解釈が異なります。
文字列として渡すためにはシングルクォートで囲いましょう。ダブルクォートですとそのそのカラムを探すようです。
-- MySQL・Hiveで使える記法
SELECT "abc" AS name;
SELECT 'abc' AS name;
-- Prestoで使える記法
SELECT 'abc' AS name;
カラム名に別名を付けるAS句についてもケアが必要です。
Prestoではダブルクォートで囲みましょう。
-- MySQLで使える記法
select '日本語' AS `日本語`;
select '日本語' AS '日本語';
select '日本語' AS "日本語";
-- Hiveで使える記法
select '日本語' AS `日本語`;
-- Prestoで使える記法
SELECT '日本語' AS "日本語";
予約語のカラム名を用いる際はバッククォートで囲みます。
-- Hiveの場合
SELECT `date`
-- Prestoの場合
SELECT "date"
IFNULL関数
IFNULL関数は、最初の引数がNULLならば、2番目の引数を返すSQL関数です。
しかしこちら、HiveにもPrestoにもありません。その代わりIF文で表現できます。
例)割引率を格納するdiscount_priceフィールドに値があればそれを、NULLだった時には0と返したい場合
-- MySQLで使える記法
select IFNULL(discount_price, 0) from items;
-- Hive・Prestoで使える記法
select IF(discount_price IS NULL, 0, discount_price) from items;
-- MySQL・PostgreSQL・Prestoで使えるcoalesce関数を使った例は次の通りです
-- この関数は2つ以上の引数を取り、一番最初のNULLでない値を返します
select coalesce(discount_price, 0) from items;
NULLIF関数
Hiveにはまだありませんが、Prestoではnullif関数が使えます。
NULLIF(value1, value2)と用い、value1とvalue2が同じならnullを返し、それいがいはvalue1を返すというものです。
次のように、COALESCEと一緒に使うと便利なケースが多いです。
-- Presto向け:emailが空文字ならtelephoneを返し、そうでなければemailを返すケース
SELECT COALESCE(NULLIF(email,''), telephone) AS contact FROM registration;
-- Hive向け その1
SELECT IF(email = '', telephone, email) AS contact FROM registration;
-- Hive向け その2
SELECT
CASE
WHEN email = '' THEN telephone
ELSE email
END AS contact
FROM
registration;
cf. http://stackoverflow.com/questions/17283978/sql-coalesce-with-empty-string
CONCAT関数
CONCAT関数は、引数の文字列を連結した文字列を返すSQL関数です。
MySQLとHiveは2つ以上の引数でも動き、数値型カラムであれば自動的に文字列型へ変換されます。
配列型の結合にも使えますが重複要素が残るので、重複排除するためにはarray_union()を使います。
-- MySQL・Hiveで使える記法
SELECT CONCAT('string', 100); -- 結果: string100
SELECT CONCAT("string", 100); -- 結果: string100
SELECT CONCAT(pref_name, city_name) FROM shops;
SELECT CONCAT(pref_name, city_name, town_name) FROM shops;
-- Prestoで使える記法
-- concat(array(E), E) E, concat(E, array(E)) E, concat(array(E)) E, concat(varchar) , concat(varbinary)
SELECT CONCAT(pref_name, city_name) FROM shops;
SELECT CONCAT('string', cast(100 AS VARCHAR)); -- 結果: string100
SELECT CONCAT(array[1],array[1,2,3]); -- 結果: ["1","1","2","3"]
-- PostgreSQL・Prestoで使える||演算子を用いると、2つ以上の要素を連結できます
SELECT pref_name || city_name FROM shops;
SELECT pref_name || city_name || town_name FROM shops;
-- Presto v0.113以前で使う記法
SELECT CONCAT(CONCAT(pref_name, city_name), town_name) FROM shops;
-- Prestoで使えない記法
SELECT CONCAT("string", cast(100 AS VARCHAR)); -- ダブルクォートなので、そのカラムを探してしまうが見つからずにエラー
その昔のPrestoはでは引数が2つに限定される他、連結できるのは文字列型のみでしたが、
Presto v0.113からは最大254要素までの各種型の連結に利用できるようになりました。
2019年1月現在のAWS AthenaはPresto 0.172なので、そちらでも使えます。
executing query: select concat('a','b','c')
Query 20150122_020707_00541_693te failed: Unexpected parameters (varchar, varchar, varchar) for function concat.
Expected: concat(varchar, varchar), concat(array<E>, array<E>), concat(array<E>, E), concat(E, array<E>)
PrestoでJSON型やJSON文字列を組み立てるときには、次のように行います。
-- 文字列結合を用いてValidなJSON作るには、次のように記述します。
SELECT json_format(json_parse('{"a":' || '1}'))
-- Prestoドキュメントに記載のクエリ例としてはこのように書いてありますが・・・
SELECT JSON '[1, 2, 3]';
SELECT json_format(JSON '[1, 2, 3]');
-- 例に習って文字列結合を追加すると、次のエラーが発生します
-- Unexpected parameters (json, varchar(10)) for function concat. Expected: concat(array(E), E) E, concat(E, array(E)) E, concat(array(E)) E, concat(varchar) , concat(varbinary)
SELECT json_format(JSON concat('{"a":' , '1}'));
SELECT json_format(JSON '{"a":' || '1}');
CAST関数
型に厳しくないHiveやMySQLでは利用の機会が少ないと思いますが、Prestoでは世話になる機会が増えます。
Prestoでの利用方法を紹介します。本ガイドでは、CONCATを用いる際に利用しております。
- CAST(value AS types)
- TRY_CAST(value AS type) ※ Hiveに存在しない関数
typeに指定できる型は、boolean, bigint, double, varcharの4種類です。
-- Prestoでの利用例
SELECT CONCAT('string', cast(100 AS VARCHAR)); -- 結果: string100
SELECT CONCAT(CONCAT(area, '_'), cast(id AS VARCHAR)) FROM shops; -- 結果: tokyo_1
-- Prestoでは||演算子でも連結して利用できます
SELECT 'string' || cast(100 AS VARCHAR); -- 結果: string100
SELECT area || '_' || cast(id AS VARCHAR) FROM shops; -- 結果: tokyo_1
cf. http://prestodb.io/docs/current/functions/conversion.html
なお、string型向けの関数へCAST関数を用いずに渡すと、Prestoは次のエラーを返します。
executing query: select concat(name, area_id) from pref
Query 20150122_021028_00576_693te failed: Unexpected parameters (varchar, bigint) for function concat.
Expected: concat(varchar, varchar), concat(array<E>, array<E>), concat(array<E>, E), concat(E, array<E>)
数字を3桁のカンマ区切りでフォーマットする
本当はView側でするべきだが、クエリの結果をそのまま表示するために地味に必要になることのある構文です。
Prestoでは浮動小数点型と整数型で結果が変わるので要注意です。それだけでなく、GoogeSheetに書き出す時に数字として書き出すと、整数では無く浮動小数点型として扱われるようです。1京を超えるような数字にて後ろの桁が0に丸められてしまいます。先に文字列として加工してからGoogleSheetに書き出しましょう。
-- Prestoで使える記法
select format('%,d', 125845743760264634); -- 125,845,743,760,264,634
select format('%,.2f', 1258457437602646304.00); -- 1,258,457,437,602,646,270.00 ※丸められる
select format('%,.2f', CAST(1258457437602646304 AS DOUBLE)); -- 1,258,457,437,602,646,270.00 ※丸められる
-- Hiveで使える記法
select format_number(125845743760264634, 0); --
125,845,743,760,264,634
select format_number(125845743760264634, 2); -- 125,845,743,760,264,634.00 ※丸められ"ない"
複数行の結果を集約して使う際に、あらかじめ特定の値を取り除く
複数行の結果を集約して使う際に、あらかじめ重複除去したり特定の値を取り除きたいことがあるでしょう。
PrestoとHiveの大きな違いとしては、HiveではNULL除外が暗黙的に行われることです。
次の中から、求める物を選んでください。
- presto
- NULL残し・重複維持
ARRAY_AGG(name) - NULL残し・重複排除
ARRAY_AGG(DISTINCT name)またはARRAY_DISTINCT(ARRAY_AGG(name)) - NULL除外・重複維持
ARRAY_AGG(name) FILTER(WHERE name IS NOT NULL) - NULL除外・重複排除
ARRAY_AGG(DISTINCT name) FILTER(WHERE name IS NOT NULL)
- NULL残し・重複維持
- hive
- NULL残し・重複維持
COLLECT_LIST(coalesce(name,''))※注: nullは空文字となります - NULL残し・重複排除
COLLECT_SET(coalesce(name,''))※注: nullは空文字となります - NULL除外・重複維持
COLLECT_LIST(name) - NULL除外・重複排除
COLLECT_SET(name)
- NULL残し・重複維持
PrestoのARRAY_AGG()ではDISTINCTだけでなく、ORDER BYにもv0.190から対応しています。
しかし2020年10月現在、AWS AthenaのPrestoはv0.172(2017年リリース)から更新されていないため、ARRAY_DISTINCT(ARRAY_AGG(name))や、ARRAY_SORT(ARRAY_AGG(col))で代替しましょう。
配列から特定の値またはNULLの値を取り除く
Prestoは標準の ARRAY_REMOVE() 関数が便利ですが、nullの除去に非対応という落とし穴があります。
基本的に1つ前のトピックで紹介したARRAY_AGG()で集約するときに、あらかじめ除外しておくべきです。
しかし複数の空配列を含む値を1つのARRAYに入れてFLATTEN()した時など、どうしてもnullが複数含まれることがあります。そんなときには FILTER()を用いて後処理を行います。
Hiveは標準の LATERAL VIEW EXPLODE で配列を行に展開して除外してからまた配列に戻す事をする必要があり、クエリが複雑になります。出来ることならHivemallのUDFをインストールしてARRAY_REMOVE() 関数を導入しましょう。
それでは、[1,null,3,null,5,5]からnullと3を取り除く例を紹介します。
-- Presto の ARRAY_REMOVE() で 3 を取り除く例
SELECT ARRAY_REMOVE(ARRAY[1,null,3,null,5,5], 3);
-- 結果: ["1",null,null,"5","5"]
-- Presto の ARRAY_REMOVE() で null を取り除こうとすると結果が空の NULL となります(要注意)
SELECT ARRAY_REMOVE(ARRAY[1,null,3,null,5,5], NULL);
-- 結果: NULL
-- Presto で配列からnullを取り除くときは、FILTER() を使います
SELECT FILTER(ARRAY[1,null,3,null,5,5], x -> x IS NOT NULL AND x <> 3);
-- 結果: ["1","5","5"]
-- Presto で配列からnullを取り除き、重複排除する例
SELECT ARRAY_DISTINCT(FILTER(ARRAY[1,null,3,null,5,5], x -> x IS NOT NULL AND x <> 3));
-- 結果: ["1","5"]
-- Presto で複数の配列を入れ子にして、展開して、 NULL と 3 を取り除く例
SELECT FILTER(FLATTEN(ARRAY[array[1,null,3,5,5], array[null]]), x -> x IS NOT NULL AND x <> 3);
-- 結果: ["1","5","5"]
長くなりましたので、Hive編は分割して紹介します。
-- Hive にて Hivemall UDF の ARRAY_REMOVE() で 3 を取り除く例
SELECT array_remove(array(1,null,3,null,5), 3);
-- 結果: ["1",null,null,"5"]
-- Hive の ARRAY_REMOVE() で null と 3 を取り除く例
SELECT array_remove(array_remove(array(1,null,3,null,5), null), 3);
-- 結果: ["1","5"]
-- Hive の標準機能で配列から 3 を取り除く例
SELECT
COLLECT_LIST(t_column) -- 重複除外するときは COLLECT_SET() を使います
FROM (
select stack(
1, -- put a number of row count
1, array(1,null,3,null,5)
) as (id, array_column)
) fruits
LATERAL VIEW EXPLODE(array_column) t as t_column
WHERE
t_column <> 3;
-- 結果: ["1","5"]
なお、Presto の ARRAY_REMOVE() で null が消せないのは不具合では無さそうで、明示的に非対応としている記述がコードにありました。
https://github.com/prestosql/presto/blob/fca04a236a6c2dfee639481720e1cad7c8de98a1/presto-main/src/main/java/io/prestosql/operator/scalar/ArrayRemoveFunction.java#L121
条件付きでのカウント
WHERE句で取り出した条件の中で、任意の条件に合致する件数をカウントしたい時に利用する構文です。
count()の条件をそれぞれ違う物で複数回連ねる記法は、1つのクエリでレコードの内訳を詳しく調査できるため便利です。
次は、matching_levelが5以上のレコードの数をカウントする例です。
-- Prestoで動くがHiveでは使えない
count(matching_level >= 5 or null) as count
-- Presto・Hiveで使える
sum(if(matching_level >= 5,1,0)) as count
Hiveの場合はsumを用いたトリッキーな手法を使う必要がありましたが、PrestoならANSI互換なので自然なクエリが書けますね。
参考: https://www.softel.co.jp/blogs/tech/archives/3267
IN()の扱い
次のHiveクエリには制約があり、素直に書くと次のエラーとなります。
そのため冗長な表記となっている場合には、Prestoではシンプルに記述できます。
--Prestoで動くがHiveでは使えない
--Correlating expression cannot contain unqualified column referencesエラーとなる
station_id IN(SELECT station_id FROM other_stations)
--Hiveで動くクエリ
station_id IN(SELECT other_stations.station_id FROM other_stations)
文字列の切り出し
Hiveではsubstringとsubstrがありますが、Prestoではsubstrのみ使えます。
substrで統一しておけば、移植性は高まるでしょう。
--Hive・Prestoで動くクエリ
--substr(文字列, 開始位置, 開始位置からの長さ)
SELECT substr('ABCDE', 2, 1) -- 結果: B
SELECT substr('ABCDE', -2, 1) -- 結果: D
JSON文字列から特定のキーの値を取り出す例
PrestoではJSON_EXTRACT()またはJSON_EXTRACT_SCALAR()を、Hiveではget_json_object()を用います。
よくあるJSON Pathの使い方として、key1を取り出すなら $.key1というような表記をします。
それでほとんどのケースでは事足ります。Hiveの限定的なJSONPathへの対応であっても動作します。
注記:Hiveドキュメントに"A limited version of JSONPath is supported"との記載
Prestoは JSON Path 0.5.0 syntaxに対応しているので、比較的強力です。
例えば、digdagが生成したログにはtd>というキーのJSONが含まれているため、$.td>という表記では取り出せません。
Prestoであれば、$["td>"]というJSON Pathを指定することで、該当の要素の値を取り出せます。
しかしながらHiveはこの表記に対応していないため、どうやら正規表現でも使わないと取り出せなさそうです。
それでは、次の結果を求めるクエリを順番に紹介していきます。

--Prestoで動くクエリ
SELECT
input_json,
JSON_EXTRACT_SCALAR(input_json,'$["td>"]') AS filename, -- 対応
JSON_EXTRACT(input_json,'$["last_job"]') AS last_job, -- 対応
JSON_EXTRACT(input_json,'$.last_job') AS last_job2 -- 対応
FROM
(VALUES json_parse('{"td>":"query.sql","last_job":{"id":"1234","num_records":8}}')) AS t(input_json)
--Hiveで一部動くクエリ
SELECT
input_json,
get_json_object(input_json,'$["td>"]') AS filename, -- 非対応のためNULLとなる
get_json_object(input_json,'$["last_job"]') AS last_job, -- 非対応のためNULLとなる
get_json_object(input_json,'$.last_job') AS last_job2 -- 対応
FROM
(
SELECT '{"td>":"query.sql","last_job":{"id":"1234","num_records":8}}' AS input_json
)t
JSONオブジェクトの一部の要素を除外または上書きして利用したい
Hiveでの書き方はLATERAL VIEW explodeしてから再度MAP型に戻すのですが、collect_set()ではJSONに戻せないので外部のUDFを入れられる環境でなければややこしくなります。数千万行に対して可変長のJSONを展開して戻す処理は基本的に膨大な処理時間の増加の原因になるのでHiveでこういった処理はおすすめできません。
ところが、Prestoでは制約はありながらも手軽に出来るので紹介したいと思います。
それぞれの結果サンプルは次の通りです。注意点としては、型が保持されず全てVARCHAR型となり、順番も維持されないことです。
- input:
{"auth_method":"hoge","api_key":"123456","host":"localhost"} - filtered_map :
{"auth_method":"hoge","host":"localhost"} - transformed_map :
{"auth_method":"hoge","api_key":"[FILTERED]","host":"localhost"}

-- Prestoでの書き方
SELECT
-- 加工前のMAP型のオブジェクト
input,
-- trueとなる要素のみ残す例
MAP_FILTER(input, (key, value) -> key NOT IN('api_key')) AS filtered_map,
-- 特定のキーの場合に値を上書きする例
TRANSFORM_VALUES(input,(k, v) -> IF(k IN('api_key'),'[FILTERED]',v)) AS transformed_map,
-- TDにおいて、文字列型のカラムに書き込む場合の変換
JSON_FORMAT(CAST(TRANSFORM_VALUES(input,(k, v) -> IF(k IN('api_key'),'[FILTERED]',v)) AS JSON)) AS transformed_map_as_varchar
FROM
(
VALUES CAST(JSON_PARSE('
{ "api_key": "123456",
"auth_method": "hoge",
"host": "localhost"
}') AS MAP<VARCHAR,VARCHAR>)
) AS t(input);
参考となった記事
https://qiita.com/takat0-h0rikosh1/items/1193c08846fc596a5106
文字列をJSONに変換し、その中の配列の数を数える方法
LATERAL VIEWやUNNESTを用いて行に展開してからGROUP BYする方法をとらずに、要素をカウントできます。
SELECT
cardinality(CAST(JSON_PARSE(input_json) AS ARRAY<ARRAY<VARCHAR>>))
FROM
(
SELECT '[["InvoiceID","string","invoiceid"],["PayerAccountId","string","payeraccountid"]]' AS input_json
)t
)

置換関数
HiveからPrestoやその逆の書き換えが地味に手が掛かる置換関数です。
- Hiveのtranslate関数に対応するPrestoの関数は現状ありません
- replace関数をネストさせて頑張る必要があります
- Prestoのreplaceに対応する関数はHiveにはありません
- regexp_replaceを利用することになります
--1→a, 3→b, 5→cという置換を行う場合
--結果はどちらも`0a2b4c`となります
--Hiveで動くがPrestoでは動かない
SELECT translate('012345', '135', 'abc')
--Prestoで動く互換処理
SELECT replace(replace(replace('012345', '1', 'a'), '3', 'b'), '5', 'c')
--Hive: 単純な置換をする時も regexp_replace を利用するので、メタ文字はエスケープする必要がある
SELECT regexp_replace('012345', '01', 'abz') --結果: abz2345
--Presto: 用途に応じてreplaceやregexp_replaceを使い分けられる
SELECT regexp_replace('01-23-45', '[0-9]', 'Z') --結果: ZZ-ZZ-ZZ
SELECT replace('01-23-45', '-', '') --結果: 012345
translate関数を応用すれば、片仮名(カタカナ)から平仮名への変換もHiveクエリで行えます。
-- Hiveのみで動くクエリ
SELECT
translate(
'ミヤギケンイワヌマシカジバシ',
'アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲンヴガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポァィゥェォャュョッ',
'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをんゔがぎぐげござじずぜぞだぢづでどばびぶべぼぱぴぷぺぽぁぃぅぇぉゃゅょっ'
) -- 結果: みやぎけんいわぬましかじばし
正規表現を用いた関数
HiveではRLIKEを用いますが、Prestoではregexp_likeを使います。
-- Hiveで動くクエリ
SELECT 'abc' RLIKE '^[a-z]{3}$'
-- Prestoで動くクエリ
SELECT regexp_like('abc', '^[a-z]{3}$')
なお、Prestoではcol LIKE '%abc%'はregexp_like(col, 'abc')に内部的に書き換えられています。
もちろんその際にパターン部分はエスケープされているので、メタ文字が含まれても問題なく動きます。
正規表現でメタ文字を利用する際のエスケープ
メタ文字を単なる文字列として扱う際には、エスケープする必要があるのですが、HiveとPrestoで挙動が異なる時があります。
対象となるメタ文字には¥ * + . ? { } ( ) [ ] ^ $ - |があります。 引用元:www.javadrive.jp
一般的にはバックスラッシュを1つとするのが通常なので、Hiveクエリを書く際にはハマるかもしれません。
挙動が同じサンプルは次の通りです
--Hive・Presto共に同じ挙動
select regexp_replace('(仮称)ABC', '[(\(]?仮称?[)\)]', '') --結果: ABC
select regexp_extract('(仮称)ABC', '[(\(]?(仮称?)[)\)]', 1) --結果: 仮称
挙動が異なる実際のサンプルは次の通りです。
ここでは、AAA(BBから(BBを取り出します。
--Hive: エスケープが1つの場合
select regexp_extract('AAA(BB', '(\(BB)$', 1)
--エラー内容 Wrong arguments '1': org.apache.hadoop.hive.ql.metadata.HiveException
--Hive: エスケープが2つの場合
select regexp_extract('AAA(BB', '(\\(BB)$', 1) --結果: (BB
--Presto: エスケープが1つの場合
select regexp_extract('AAA(BB', '(\(BB)$', 1) --結果: (BB
--Presto: エスケープが2つの場合
select regexp_extract('AAA(BB', '(\\(BB)$', 1)
--エラー内容 failed: end pattern with unmatched parenthesis
その他、こういったエラーメッセージの時もあります。
--Hive: エスケープが1つの場合 動かない
select regexp_replace('Hiveビル(B1-7F)', '\(?B?[0-9]+[-〜][0-9][F階]\)?', '')
--エラー内容 Unknown inline modifier near index 2
--Hive: エスケープが1つの場合 動く
select regexp_replace('Hiveビル(B1-7F)', '\\(?B?[0-9]+[-〜][0-9][F階]\\)?', '')
Hiveではバックスラッシュを2つにする必要があるケースがあること、覚えておきたいですね。
どういう条件でそうすれば良いのかまだ分からないので、ご存じの方いらっしゃれば教えてください。
また、例えばあるカラムAにカラムBの内容が含まれているかを調べたいとき、LIKEで部分一致検索することもできます。
しかし正規表現と組み合わせたい時には、メタ文字が含まれている事も考慮してエスケープしなければなりません。
その時に便利なメタ文字が次ぎの\Qと\Eです。
-
\... 正規表現ではないが、次の文字をエスケープする -
\Q... 正規表現ではないが、\E までのすべての文字をエスケープする -
\E... 正規表現ではないが、\Q で開始された引用をエスケープする
引用元: https://docs.oracle.com/javase/jp/7/api/java/util/regex/Pattern.html
バックスラッシュは有名なもので、直後にある意味のある文字をエスケープして単純な文字列として扱う物です。
その後に続く2つはセットで使う物で、\Qから引用文字列として\Eまで、エスケープを行います。
利用サンプルは次の通りです。
ここでは単純に部分一致で見ていますが、正規表現の一部に組み込んで利用することもできます。
- Hiveの例
WHERE building_name REGEXP CONCAT('\\Q', room_name, '\\E') - Prestoの例
WHERE regexp_like(building_name, '\Q' || room_name || '\E')
これを活用することで、激しいエスケープ処理を実装することなくスマートに実装したいですね。
JSONの中身を置換したいときなどにもこのエスケープは有効でしょう。
次の記事で紹介されているテクニックに活用すれば、さらに見やすく出来るはずです。
Replacing a specific element from a JSON object stored as string in Hive - Stack Overflow
正規表現で文字列を抽出するときの挙動
マッチしない正規表現でregexp_extractを使うと、Nullが返る物と思っていましたが、Hiveは空文字を返します。
一方。Prestoは期待通りNULLを返します。
--Hive : 空文字が返る
SELECT regexp_extract('example-string', '([0-9]+)', 1) as foo
--Presto : NULLが返る
SELECT regexp_extract('example-string', '([0-9]+)', 1) as foo
そのため、その結果を利用して別のクエリで条件を書く時には考慮が必要です
--Prestoでは動くが、Hiveでは同じように動かない例
SELECT
foo
FROM
(SELECT regexp_extract('example-string', '([0-9]+)', 1) as foo) t
WHERE
foo IS NOT NULL
--Hiveでは空文字での判定が必要です
SELECT
foo
FROM
(SELECT regexp_extract('example-string', '([0-9]+)', 1) as foo) t
WHERE
foo != ''
空文字とするのは気持ち悪いので、Hiveでその結果をNULLとして扱うには次の方法があります。
translate関数やregexp_replaceなどでは対処できず、他に良い方法があれば教えてください。
--Hive: regexp_extractでマッチしない場合にNULLを返す方法
--IF文やCASE文を用い、LIKEやREGEXPを用いて事前に判定する
SELECT
foo
FROM
(
SELECT
IF('example-string' REGEXP '([0-9]+)', regexp_extract('example-string', '([0-9]+)', 1), NULL) as foo
UNION ALL
SELECT
IF('example-string' REGEXP '([a-z]+)', regexp_extract('example-string', '([a-z]+)', 1), NULL) as foo
) t
WHERE
foo IS NOT NULL
今月の日数を算出する
今日までの利用量から、今月末までの利用を推計する時に使いました。
例えば日数が31日ある8月で、20日時点で$40の利用がある時、今月の概算を求めたいとします。
最終的に、今月の概算見積額 = $40 / 今日の日付 * 今月の日数 = $40 / 20 * 31 = $62 という式を組み立ててみます。
第1ステップとして、これに必要な数字をSQLで求めてみましょう。
TreasureData(TD)で使える便利UDFを使うと、PrestoとHiveでクエリの共通化が出来ますが、少々複雑になってしまいました。
--Prestoで動くクエリ
SELECT
day(date '2020-08-20') AS today_day, -- 本日の日付
-- 2020-08-20の月初 → 2020-08-01 → 翌月1日 - 1日 → 2020-08-31
day(date_trunc('month', date '2020-08-20') + interval '1' month - interval '1' day) as date_of_this_month -- 今月の日数
-- Hive 1.2以降で動くクエリ
-- @TD enable_cartesian_product:true
SELECT
day('2020-08-20') AS today_day, -- 本日の日付
-- last_day()は 'yyyy-MM-dd HH:mm:ss' または 'yyyy-MM-dd' の入力に対応しています
day(last_day('2020-08-20')) as date_of_this_month -- 今月の日数
--Hive・Presto共にTDで提供される共通のUDFで記述するとこのようになります
SELECT
-- 本日の日付
CAST(TD_TIME_FORMAT(TD_TIME_PARSE('2020-08-20'), 'dd') AS BIGINT) AS today_day,
-- 今月の日数
CAST(
TD_TIME_FORMAT(-- 31
TD_TIME_ADD(-- 2020-08-31
TD_DATE_TRUNC('month', -- 2020-09-01
TD_TIME_ADD(-- 2020-08-01 + 31 = 2020-09-01
TD_DATE_TRUNC('month', -- 2020-08-01
TD_TIME_PARSE('2020-08-31')
)
, '31d'
)
)
,'-1d'
)
, 'dd'
)
AS BIGINT
) as date_of_this_month

必要な数字を用意できたので、組み合わせてみましょう。
--Prestoで動くクエリ
WITH usage_estimate AS (
SELECT
day(date '2020-08-20') AS today_day,
day(date_trunc('month', date '2020-08-20') + interval '1' month - interval '1' day) as date_of_this_month
), current_month_usage AS (
SELECT 40 as cost
)
SELECT
cost / today_day * date_of_this_month AS estimated_cost
FROM
current_month_usage, usage_estimate
-- Hive 1.2以降で動くクエリ
-- @TD enable_cartesian_product:true
WITH usage_estimate AS (
SELECT
day('2020-08-20') AS today_day,
-- last_day()は 'yyyy-MM-dd HH:mm:ss' または 'yyyy-MM-dd' の入力に対応しています
day(last_day('2020-08-20')) as date_of_this_month
), current_month_usage AS (
SELECT 40 as cost
)
SELECT
-- double型の結果をBIGINTに変換します
CAST(cost / today_day * date_of_this_month AS BIGINT) AS estimated_cost
FROM
current_month_usage, usage_estimate
期待通り $62 という結果を求められました。

2つの日付の期間計算
2つの日付の期間を計算したい時にはdatediffを使います。
引数の順番が異なるので注意しましょう。
--Hiveで動くクエリ
--2つの差分日数の計算のみできる
--datediff(enddate, startdate)
SELECT datediff('2009-03-01', '2009-02-27') --結果: 2
--Prestoで動くクエリ
--第1引数で指定した単位(下記参照)での差を計算できる
--date_diff(unit, starttime, endtime)
SELECT date_diff('day', CAST('2009-02-27' AS DATE), CAST('2009-03-01' AS DATE)) --結果: 2
SELECT date_diff('day', CAST('2009-02-27' AS TIMESTAMP), CAST('2009-03-01' AS TIMESTAMP)) --結果: 2
Prestoでは、date_diffの第1引数に次の値が使えます。
https://prestodb.io/docs/current/functions/datetime.html#interval-functions
| 単位 | 説明 |
|---|---|
| millisecond | ミリ秒 |
| second | 秒数 |
| minute | 分数 |
| hour | 時間 |
| day | 日数 |
| week | 週数 |
| month | 月数 |
| quarter | 四半期 |
| year | 年数 |
Prestoのdate_diffの第2引数と第3引数で扱える型のパターンは次の通りです。
Hiveのように文字列で渡すと、Unexpected parameters (varchar, varchar, varchar)というエラーとなります。
- date_diff(varchar, date, date)
- date_diff(varchar, time, time)
- date_diff(varchar, time with time zone, time with time zone)
- date_diff(varchar, timestamp, timestamp)
- date_diff(varchar, timestamp with time zone, timestamp with time zone)
HiveからPrestoへの書き換えは簡単ですが、その逆は厳しい状況です。
なお、Hive 1.2.0から月数の差を求めるmonths_between関数が加わりました。
--Hive 1.2.0以降で使える関数
SELECT months_between('1997-02-28 10:30:00', '1996-10-30')--結果: 3.94959677
型変換
HiveではLL言語のように型が違えどよしなに扱ってくれますが、
Prestoでは型が異なるとエラーとなるので厳格に型を意識する必要があります。
別の型のものを文字列型にしたい時は、次のように行います。
--Hiveで動くクエリ
CAST(col1 AS STRING)
--上記クエリをPrestoで使うと次のエラーとなります
--Unknown type: STRING
--Prestoで動くクエリ
CAST(col1 AS VARCHAR)
--上記クエリをHiveで使うと次ののエラーとなります
--mismatched input ')' expecting ( near 'VARCHAR' in primitive type specification
ORDER BYで使うカラムは必ずSELECTする必要がある
Prestoでは、SELECT句でリストアップしなくてもORDER BY句で使えますが、
HiveではWHERE句で使う物はSELECT句で呼び出す必要があります。
その際は次のようなエラーとなります。possible column names areというのがORDER BY句で使える物です。
Invalid table alias or column reference 'room_name': (possible column names are: building_name, _c1)
パーセンタイルを算出
パーセンタイルを算出する関数は、単語の順番が逆になります。
col列を昇順に並べて小さい方から50%の所、つまり中央値を取る例で記載します。
- Presto:
approx_percentile(col, 0.5) - Hive:
percentile_approx(col, 0.5)
HiveにおけるWITH句のパフォーマンス
WITH句の結果を複数回再利用するクエリの場合、HiveからPrestoにすると相当高速化できます。
Hiveでは利用されるクエリの中でその都度、サブクエリに展開されて評価して処理するため、オーバーヘッドが大きいです。
そういった再利用される箇所は、先にテーブルに書き出してから参照すると良いでしょう。
次の記事が参考になります。
HiveQL で Common Table Expressions (CTE a.k.a. WITH 句) を利用する際に注意すべきこと - k11i.biz
https://k11i.biz/blog/2016/10/19/using-cte-on-hive/
ネストしたWITH句の挙動
ダッシュボードの裏側で生成されそうなものとして、WITH句のネストがあります。
Aという集計のためのWITH句と、Bという集計のためのWITH句をそれぞれ組み上げてJOINして使いたいときに生まれてしまうことがあります。
確かにそれぞれの集約クエリの内容をWITH句の名前を衝突させずにカプセル化できるのですが、これはPrestoのみで動作します。
Hiveでは次のエラーとなり、動きません。
FAILED: ParseException line 5:2 Failed to recognize predicate 'SELECT'. Failed rule: 'queryStatementExpression' in statement
-- prestoで動くクエリ
with summary_a as (
with source as (
SELECT 1 as id, 'a' as a
)
SELECT * FROM source
), summary_b as (
with source as (
SELECT 1 as id, 'b' as b
)
SELECT * FROM source
)
SELECT
*
FROM
summary_a
INNER JOIN summary_b USING(id)
Hiveで動作させるために、次の変更を加えます。
- HiveではUSING句が使えないので、ONを用いる
- WITH句の中にWITH句をネストせず、サブクエリで表現する
-- Presto/Hiveで共に動くクエリ
with summary_a as (
SELECT * FROM (
SELECT 1 as id, 'a' as a
) source
), summary_b as (
SELECT * FROM (
SELECT 1 as id, 'b' as b
) source
)
SELECT
*
FROM
summary_a
INNER JOIN summary_b ON summary_a.id = summary_b.id
業務効率が上がる便利なSQLテクニック
自由自在にデータを操るテクニックを紹介します。
LATERAL VIEW / CROSS JOIN
1つのフィールドにArray型として保存するが、それを行に展開してJOINする時に使う構文です。
hivemallで作った回帰分析のモデルを精度検証する際などのスピードアップにも役立ちます。
Prestoでは次のようにUNNESTを利用します。
-- Hive
SELECT student, score
FROM tests
LATERAL VIEW explode(scores) t AS score;
-- Presto
SELECT student, score
FROM tests
CROSS JOIN UNNEST(scores) AS t (score);
-- Presto (String型でJSON形式の文字列が入ってる時)
-- 配列の中身に準じて ARRAY<BIGINT> や ARRAY<VARCHAR> ARRAY<JSON> などを指定します
SELECT student, score
FROM tests
CROSS JOIN UNNEST(CAST(json_parse(scores) AS ARRAY<BIGINT>)) AS t (score);
動きが分かりづらい構文なので、サンプルも用意しました。
-- Hive
SELECT
id, scores, score
FROM
(
SELECT 1 as id, array(60,70,50) as scores
) tests
LATERAL VIEW explode(scores) t AS score;
-- Presto
SELECT
id, scores, score
FROM
(
SELECT 1 as id, array[60,70,50] as scores
) tests
CROSS JOIN UNNEST(scores) AS t (score);
-- Presto (String型でJSON形式の文字列が入ってる時)
SELECT
id, scores, score
FROM
(
SELECT 1 as id, '[60,70,50]' as scores
) tests
CROSS JOIN UNNEST(CAST(json_parse(scores) AS ARRAY<BIGINT>)) AS t (score);
次のように、行が増えます。
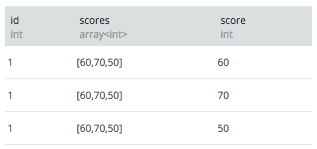
なお、展開した結果にJOINすることはPrestoでは出来ますが、Hiveではできません。
LATERAL VIEWに 続けてINNER JOINなどは書けないのでサブクエリ化する必要があります。
毎日は無いアクティビティのため、欠損値があれば0と扱いたいときに有用です。Google Sheetに書き出す時によく使います。
欠損値を補完することで、複数の処理から同じシートの別々の列に書き出しても、行ズレが起きません。
WITH sequential_date AS (
SELECT
TD_TIME_FORMAT(date_column, 'yyyy-MM-dd') AS day
FROM
(VALUES
(SEQUENCE(TD_TIME_ADD('${session_date}', '-30d'),
TD_TIME_PARSE('${session_date}'),
86400)
)
) AS t1(date_array)
CROSS JOIN UNNEST(date_array) AS t2(date_column)
), api_call AS (
SELECT day, COUNT(*) AS api_call_count FROM api_log GROUP BY day
)
SELECT
day,
COALESCE(api_call_count, 0) AS api_call_count
FROM
sequential_date
LEFT JOIN api_call USING(day)
ORDER BY
day, customer_id
配列の順番を維持したまま縦に展開し、ソートに使えるキーを付与する
配列の中身を展開したいが、そのままの順番で並び替えて使いたいときは、配列のインデックスを付与する構文を使います。
PrestoではUNNESTにWITH ORDINALITYを付与し、Hiveではexplode()ではなくposexplode()を用います。
後ほど紹介する複数列のデータセットを生成するSQLを用いてソートキーを用いるのも1つですが、この手法を用いることでABC順ではない任意の順番で結果を取り出したい時に有用です。
MYSQLで言うFIELD_IN_SETを用いたORDER BY句のようなことができます。
-- Hive
SELECT
id, scores, score, order_num
FROM
(
SELECT 1 as id, array(60,70,50) as scores
) tests
LATERAL VIEW posexplode(scores) t AS order_num, score;
-- Presto
SELECT
id, scores, score, order_num
FROM
(
SELECT 1 as id, array[60,70,50] as scores
) tests
CROSS JOIN UNNEST(scores) WITH ORDINALITY AS t (score, order_num);

Digdagで1週間単位のデータ処理を行いたい
特定の日から特定の日までの期間を1週間単位で順番にバッチ処理したいことがまれにあります。(バックフィル)
Digdagというワークフローツールでは、td_for_each>:というオペレータがあります。
SQLで実行した結果の行を1つのタスクとして順番に何かしらの処理を呼び出せます。
サンプルではTreasureDataへのクエリ発行をしていますが、MySQL, PostgreSQL, BigQueryなどでも同様のことは可能です。
それでは、Digdagを用いて1週間単位のデータ処理を行う例を紹介します。
まずは日付の範囲をSEQUENCE()を用いて86400秒(1日)単位で自動生成します。
それをCROSS JOIN UNNEST()で展開し、WITH ORDINALITYを指定してインデックス番号も付与して展開します。
もちろん同様のことはWINDOW関数のROW_NUMBER()を用いてもできますが、より完結だと思います。
SELECT
TD_TIME_FORMAT(date_column, 'yyyy-MM-dd') AS day,
index,
index%7
FROM
(VALUES
(SEQUENCE(TD_TIME_PARSE('2011-07-23'),
TD_TIME_PARSE('2020-03-11'),
86400)
)
) AS t1(date_array)
CROSS JOIN UNNEST(date_array) WITH ORDINALITY AS t (date_column, index)
次の結果が得られました。
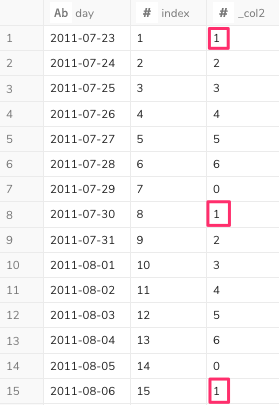
1週間単位の日付を絞り込むため、赤枠の1の行のみ選択します。その条件はindex%7 = 1です。
SELECT
TD_TIME_FORMAT(date_column, 'yyyy-MM-dd') AS start_day,
LEAD(TD_TIME_FORMAT(date_column, 'yyyy-MM-dd'), 1) OVER(ORDER BY date_column) AS end_day,
index,
index%7
FROM
(VALUES
(SEQUENCE(TD_TIME_PARSE('2011-07-23'),
TD_TIME_PARSE('2020-03-11'),
86400)
)
) AS t1(date_array)
CROSS JOIN UNNEST(date_array) WITH ORDINALITY AS t (date_column, index)
WHERE
index%7 = 1
インデックスを7で割ったときの余りが1の日付を抽出できました。しかしend_dayの最終行がNULLです。
これはWINDOW関数を用いて次の行を持ってきているが、最終行は何も取ってこられないのでNULLとなります。
このままでは、末尾数日分の処理が抜けてしまいますので、COALEASEを用いて補完します。
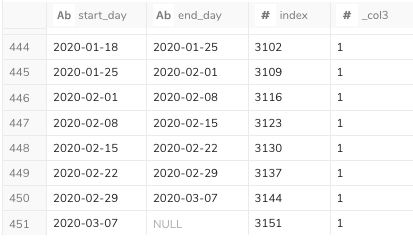
COALEASEは1つ目の結果がNULLだった時に次の引数の結果を用いるものです。
第2条件にELEMENT_ATを用いて、date_arrayの最後の1要素を取り出してきています。
SELECT
TD_TIME_FORMAT(date_column, 'yyyy-MM-dd') AS start_day,
TD_TIME_FORMAT(COALESCE(
LEAD(date_column, 1) OVER(ORDER BY date_column), -- 1つ後ろの行の値を取得
ELEMENT_AT(date_array, -1) -- 大本の日付配列の末尾の1要素を取得
), 'yyyy-MM-dd') AS end_day,
index,
index%7
FROM
(VALUES
(SEQUENCE(TD_TIME_PARSE('2011-07-23'),
TD_TIME_PARSE('2020-03-11'),
86400)
)
) AS t1(date_array)
CROSS JOIN UNNEST(date_array) WITH ORDINALITY AS t (date_column, index)
WHERE
index%7 = 1
ORDER BY
1
次のように、終了日と開始日が重なる形でリストを作ることができました。
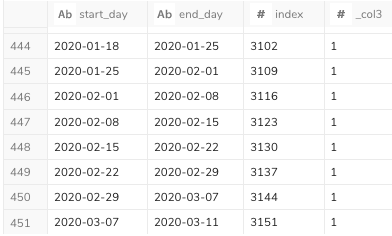
この処理をdigdagのワークフローに書き起こすと、次のようになります。
WHERE句無しでは直列処理となり時間の掛かる処理でも、並列処理で小さい単位に区切れば、大量データの複数連係も短時間で実現できます。
_export:
DEST_DATABASE: example_db
DEST_TABLE: example_table
START_DAY: 2011-07-23
END_DAY: 2020-03-11
td:
database: sample_datasets
+main:
td_for_each>:
query: |
SELECT
TD_TIME_FORMAT(date_column, 'yyyy-MM-dd') AS start_day,
TD_TIME_FORMAT(COALESCE(
LEAD(date_column, 1) OVER(ORDER BY date_column), -- 1つ後ろの行の値を取得
ELEMENT_AT(date_array, -1) -- 大本の日付配列の末尾の1要素を取得
), 'yyyy-MM-dd') AS end_day
FROM
(VALUES
(SEQUENCE(TD_TIME_PARSE('${START_DAY}'),
TD_TIME_PARSE('${END_DAY}'),
86400)
)
) AS t1(date_array)
CROSS JOIN UNNEST(date_array) WITH ORDINALITY AS t (date_column, index)
WHERE
index%7 = 1
ORDER BY
1
_parallel: true
_do:
# 実験の際にはecho>:オペレータでお試しください
#echo>: SELECT * FROM fo_bar WHERE TD_TIME_RANGE(time, 2011-07-23, 2011-07-30)
# td>:オペレータを用いてSQLを実行して外部への書き出しを行う例です
# sh>:オペレータを用いればShell Scriptを呼び出すなど任意の処理を呼び出せます
td>:
query: |
SELECT * FROM fo_bar WHERE TD_TIME_RANGE(time, ${td.each.start_day}, ${td.each.end_day})
result_url: td://${secret:td.apikey}@/${DEST_DATABASE}/${DEST_TABLE}?mode=append
任意のデータセットをクエリで表現してJOINする
テーブルを作るまでもないデータを組み合わせたいケースに有用なHiveQLのstack関数を紹介します。主なユースケースは次の通りです。
- テーブルにデータを入れるまでもないデータセットを組み合わせたSQL処理を行うとき
- テーブルにデータを入れることなく、ユニットテストを行いたいとき
- クエリロジックのチューニング後に結果が変化しないことをテスト
- テストデータをプログラム側で管理する、アドホックなテスト
-- Hive
select * from (
select stack(
2, -- put a number of row count
1, 'apple',
2, 'banana'
) as (id, name)
) fruits;
-- Presto
SELECT * FROM (
VALUES (1, 'apple'), (2, 'banana')
) as fruits(id, name);
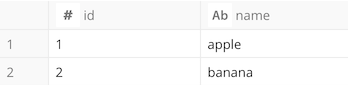
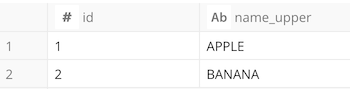
次のようにWITH句を用いて、結果をアドホックに確認する使い方もできます。
このパターンを使うと、サンプルデータをインポートさせずに、コピペで動くクエリ紹介にも使えます。
例では2行・2列で作っていますが、もちろん3つ以上にもできます。
-- Hive
WITH fruits as (
select stack(
2, -- put a number of row count
1, 'apple',
2, 'banana'
) as (id, name)
)
SELECT id, UPPER(name) as name_upper FROM fruits;
-- Presto
WITH fruits AS (
SELECT * FROM (
VALUES (1, 'apple'), (2, 'banana')
) as fruits(id, name)
)
SELECT id, UPPER(name) as name_upper FROM fruits;
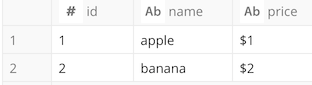
さらに、既存のテーブルに何かのデータをJOINさせて、その結果を手軽に手に入れたいときにも有用です。INSERT文を発行できないような、参照権限ユーザでも使えます。
次の例は、フルーツ商品テーブルfruitsに価格テーブルpriceを結合し、何ドルかの価格を付与するクエリです。
-- Hive
WITH fruits as (
select stack(
2, -- put a number of row count
1, 'apple',
2, 'banana'
) as (id, name)
)
SELECT
fruits.id, fruits.name, price.price
FROM
fruits
left join (
select
stack(
2, -- put a number of row count
1, '$1',
2, '$2'
) as (id, price)
) price on fruits.id = price.id;
-- Presto
WITH fruits as (
SELECT * FROM (
VALUES (1, 'apple'), (2, 'banana')
) as fruits(id, name)
)
SELECT
fruits.id, fruits.name, price.price
FROM
fruits
left join (
SELECT * FROM (
VALUES (1, '$1'), (2, '$2')
) as fruits(id, price)
) price on fruits.id = price.id;
任意の多次元配列のデータセットをクエリで表現してJOINする
多次元配列を可読性の高い形式で表現するためには、複数の型が混在できるROW()を用います。
次の手法の課題を解決する記述方法です。
- ネストさせたARRAYの中にすべて文字列として定義する
- BIGINT/DOUBLE型などを文字列にするためのクォート処理が必要になってきてしまう問題
- 配列のインデックスでアクセスしなければならずミスしやすい問題
- 単なる文字列結合でJSONオブジェクトを定義する
- BIGINT/DOUBLE型などを文字列にするためのクォート処理が必要になってきてしまう問題
-
||での結合が多すぎて視認性が悪くなる問題
次の例では、row()を配列に格納し、それをCROSS JOIN UNNESTで縦に展開する時に型の情報を再付与しています。
-- Hive
未作成。編集リクエストをお待ちしています
-- Presto
SELECT
contry_name,
data.fruit_name,
data.total_amount
FROM
(
VALUES
(
'America',
ARRAY[
('Apple', 40),
('Banana', 80),
('Cacao', 60)
]
),
(
'Japan',
ARRAY[
('Grape', 50),
('Maron', 75)
]
)
) as fruits(contry_name, param)
CROSS JOIN UNNEST(cast(param as array(row(fruit_name VARCHAR, total_amount BIGINT)))) as t(data)
多次元配列を可読性の高いSQL構文で表現し、JOINさせやすいフラットな形式に変換できました。
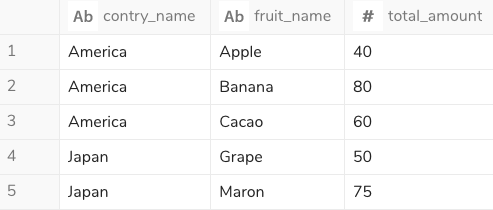
ポイントとして、ARRAY[]を使わない場合はCAST(row(('Grape', 50),('Maron', 75))AS JSON))という具合にROWからJSON ARRAYに変換することになりますが、回りくどいのでARRAYとROWの省略表記で短く仕上げました。
ちなみに、UNNEST()の中でCAST(... AS JSON)すると中の要素数が違うというValues rows have mismatched typesエラーが発生するため、定義した際にJSON ARRAYに即座に変換しています。
TreasureDataのUDFの対応状況
次の2つはHive・Presto共に利用できます。
- TD_TIME_RANGE()
- TD_TIME_ADD()
その他に、HiveではUDFとして用意しない限り無かったが、Prestoでは標準で使える関数もあります。
いわゆるGROUP BYしたものの中で最後にあるレコードを優先するという便利関数です。
ref. http://prestodb.io/docs/current/functions/aggregate.html#max_by
| Hive | Presto |
|---|---|
| TD_LAST() | max_by(url, time) |
| TD_FIRST() | max_by(url, - time) |
-- Hive example for TreasureData
SELECT user, TD_LAST(url, time) AS last_url FROM access_logs GROUP BY user;
-- Presto example
SELECT user, MAX_BY(url, time) as last_url FROM access_logs GROUP BY user;
例えばGROUP BYしたものに紐付くフィールドの中で、文字数が最も長いものだけを取り出したい時には次のように行います。
GROUP BYにはMAX_BYで取り出したいフィールドを指定しないように気をつけましょう。
-- ユーザと、最も文字数の多いコメントを取り出す例
SELECT user_id, MAX_BY(comment, length(comment)) as long_comment FROM comments GROUP BY user_id;
併せて読みたい
以上、MySQL/Hive/Prestoの挙動の違いや、実用テクニックをまとめました。
その他参考になる記事がございますので、こちらもご確認ください。
-
9.1. Migrating From Hive — Presto Documentation
http://prestodb.io/docs/current/migration/from-hive.html -
Presto Query FAQ
https://api-docs.treasuredata.com/en/tools/presto/presto_query_faqs/ -
Hive Hacks (Webアーカイブ参照)
https://web.archive.org/web/20220822110716/https://open-groove.net/hive/hive-hacks/