UTF-8をコードポイントに分解する
まずはじめに、コマンドライン引数で入力された文字列を、コードポイントごとに表示するプログラムを作成します。
UTF-8からコードポイントを求める方法は、Wikipedia で説明されているとおりです。
注意: 以下の説明は、Windowsでは動作しません。Linux, FreeBSD, MacOSX (またはCygwin)で試してください。
# include <stdio.h>
/**
* next_codepoint(&ptr);
* ptrを、次のコードポイントの位置に動かす
*/
static int next_codepoint(const char **pp)
{
const char *p = *pp;
int c = -1;
if (*p == 0) {
} else if ((*p & 0x80) == 0) {
c = *p++ & 0xFF;
} else if ((*p & 0xE0) == 0xC0) {
c = *p++ & 0x1F;
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF0) == 0xE0) {
c = *p++ & 0x0F;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF8) == 0xF0) {
c = *p++ & 0x07;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
}
*pp = p;
return c;
}
int main(int argc, char **argv)
{
if (argc >= 2) {
const char *p = argv[1];
int ch;
int count = 0;
while ((ch = next_codepoint(&p)) != -1) {
printf("U+%04X ", ch);
count++;
}
printf("\nCount = %d\n", count);
}
return 0;
}
実行結果は以下のとおりです。「あいうえお」はコードポイント5つから構成されています。
$ ./a.out あいうえお
U+3042 U+3044 U+3046 U+3048 U+304A
Count = 5
グラハム書記素について
例えば、次の文字列の文字数を数えてみましょう。
ポイント
そのままコピー&ペーストして、実行してみると、4文字と判定されます。
$ ./a.out ポイント
U+30DD U+30A4 U+30F3 U+30C8
Count = 4
では、次の文字列ではどうなるでしょうか。
ポイント
そのままコピー&ペーストして、実行してみると、5文字と判定されます。
$ ./a.out ポイント
U+30DB U+309A U+30A4 U+30F3 U+30C8
Count = 5
後者は、「ポ」が正規分解済みなので、コードポイント数は2になりますが、文字数は1になります。
以下の説明では、Unicodeで単一のコードが与えられている文字等を「コードポイント」、一般的に1文字と認識する単位(厳密に言うとグラハム書記素)を「書記素」と表します。
Unicode.orgのデータを利用する
書記素を数えるには、テーブルを参照して書記素の区切り位置を探すしかありません。
現在、最新版のUnicode 7.0.0のGraphemeBreakPropertyが利用できるので、これを利用します。
ftp://ftp.unicode.org/Public/7.0.0/ucd/auxiliary/GraphemeBreakProperty.txt
このテキストファイルは、以下のように書かれています。
(#以降はコメントです)
000A ; LF # Cc <control-000A>
U+000Aは、LFに分類されるという意味です。
3099..309A ; Extend # Mn [2] COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK..COMBINING KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK
U+3099からU+309Aは、Extendに分類されるという意味です。
これらの範囲に含まれないコードポイントは、Otherに分類されます。
以下のサンプルコードを動かすには、GraphemeBreakProperty.txtからgrapheme.datというバイナリファイルを作成する必要がありますので、頑張って作ってください。
grapheme.datは、例えばU+309AがExtendの場合、先頭から0x309Aバイト目が4になります。
# include <stdio.h>
# include <stdlib.h>
enum {
CR = 1,
LF = 2,
Control = 3,
Extend = 4,
SpacingMark = 5,
L = 6,
V = 7,
T = 8,
LV = 9,
LVT = 10,
Regional_Indicator = 11,
};
enum {
MAX_CODEPOINT = 0x10000,
};
/**
* next_codepoint(&ptr);
* ptrを、次のコードポイントの位置に動かす
*/
static int next_codepoint(const char **pp)
{
const char *p = *pp;
int c = -1;
if (*p == 0) {
} else if ((*p & 0x80) == 0) {
c = *p++ & 0xFF;
} else if ((*p & 0xE0) == 0xC0) {
c = *p++ & 0x1F;
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF0) == 0xE0) {
c = *p++ & 0x0F;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF8) == 0xF0) {
c = *p++ & 0x07;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
}
*pp = p;
return c;
}
char *load_grapheme_data(void)
{
FILE *fp = fopen("grapheme.dat", "rb");
char *dat = malloc(MAX_CODEPOINT);
fread(dat, 1, MAX_CODEPOINT, fp);
fclose(fp);
return dat;
}
int main(int argc, char **argv)
{
if (argc >= 2) {
const char *p = argv[1];
int ch;
char *dat = load_grapheme_data();
while ((ch = next_codepoint(&p)) != -1) {
if (ch < MAX_CODEPOINT) {
switch (dat[ch]) {
case CR:
printf("CR ");
break;
case LF:
printf("LF ");
break;
case Control:
printf("Control ");
break;
case Extend:
printf("Extend ");
break;
case SpacingMark:
printf("SpacingMark ");
break;
case L:
printf("L ");
break;
case V:
printf("V ");
break;
case T:
printf("T ");
break;
case LV:
printf("LV ");
break;
case LVT:
printf("LVT ");
break;
default:
printf("Other ");
break;
}
}
}
printf("\n");
}
return 0;
}
実行結果は、以下のようになります。
$ ./a.out ポイント
Other Extend Other Other Other
GraphemeBreakPropertyから区切り位置を探す
ここまで来たらもう一息です。
Grapheme Break Chart の表を見ると、区切り位置がどこかがわかります。
以下の表は、一部を抜粋したものです。
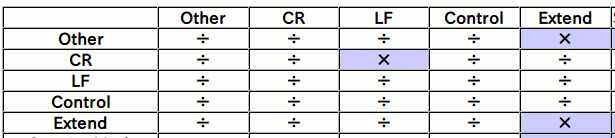
表の縦の列が前のコードポイント、横の列が後ろのコードポイントを表しています。「÷」が書記素の区切り、「×」が書記素の区切りではないことを表しています。
例えば、前のコードポイントがExtend、後ろのコードポイントがOtherなら、「÷」となるので書記素が区切られますが、前のコードポイントがOther、後ろのコードポイントがExtendなら、「×」となるので書記素が区切られません。(前のコードポイントと合わせて一つの書記素を作る)
/*
* main関数以外は、変更していないので省略
*/
int main(int argc, char **argv)
{
/**
* http://unicode.org/Public/UNIDATA/auxiliary/GraphemeBreakTest.html
*/
static const unsigned short grapheme_break[] = {
0x0030,
0x0004,
0x0000,
0x0000,
0x0030,
0x0030,
0x06f0,
0x01b0,
0x0130,
0x01b0,
0x0130,
0x0830,
};
if (argc >= 2) {
const char *p = argv[1];
int ch, type, prev_type = -1;
char *dat = load_grapheme_data();
int count = 0;
while ((ch = next_codepoint(&p)) != -1) {
if (ch < MAX_CODEPOINT) {
type = dat[ch];
if (prev_type >= 0) {
if ((grapheme_break[prev_type] & (1 << type)) == 0) {
printf("| ");
count++;
}
}
prev_type = type;
switch (type) {
case CR:
printf("CR ");
break;
case LF:
printf("LF ");
break;
case Control:
printf("Control ");
break;
case Extend:
printf("Extend ");
break;
case SpacingMark:
printf("SpacingMark ");
break;
case L:
printf("L ");
break;
case V:
printf("V ");
break;
case T:
printf("T ");
break;
case LV:
printf("LV ");
break;
case LVT:
printf("LVT ");
break;
default:
printf("Other ");
break;
}
}
}
if (prev_type >= 0) {
count++;
}
printf("\nCount = %d\n", count);
}
return 0;
}
実行結果は、以下のようになります。書記素ごとに | で区切られます。
$ ./a.out ポイント
Other Extend | Other | Other | Other
Count = 4
最後に
自前で作るより、ICUとかを使いましょう。