この投稿は自分のブログ記事をQiita用に整形したものです。追記事項があればブログの方に書いていきます。
「機械学習ライブラリ SHOGUN入門」 http://rest-term.com/archives/3090/
機械学習ライブラリ SHOGUN入門
The machine learning toolbox's focus is on large scale kernel methods and especially on Support Vector Machines (SVM)
環境
- CentOS 6.4 (x86_64/Intel Xeon 2.9GHz 32コア/96GB RAM)
- gcc 4.4.7
- cmake 2.8.11
- swig 2.0.11
- Python 2.7.5 (+ NumPy 1.7.1)
- SHOGUN (development branch / libshogun.so.14)
インストール
補足: 依存関係ライブラリのインストール
SWIG
BLAS (ATLAS) / LAPACK / GLPK / Eigen3
NumPy
コンパイル時の注意点
hello, world (libshogun)
メモリ管理の注意点
Python Modular
インストール
公式サイトではdebian系OSを前提にセットアップ手順等が書かれていますが、redhat系でも特に苦労なくインストールすることはできます。debian系ならdebパッケージで古いバージョンが配布されていますが、ここではCentOSなのでソースからコンパイル/インストールします。機械学習関連のタスクは長時間に及ぶことが多いため、SHOGUNに限らずこういったソフトウェアは実際に動作させる環境上でビルドして最適な状態で利用することをオススメします。
以前はAutotools(./configure && make)でビルドしていたらしいのですが、最新版パッケージはCMakeに対応していました。ここ数年でOpenCVやMySQLなどCMakeユーザーが増えてきましたね。
$ git clone git://github.com/shogun-toolbox/shogun.git
$ cd shogun
$ mkdir build && cd build
$ cmake -DCMAKE_INSTALL_PREFIX=/usr/local/shogun-2.1.0 \
-DCMAKE_BUILD_TYPE=Release \
-DBUNDLE_EIGEN=ON \
-DBUNDLE_JSON=ON \
-DCmdLineStatic=ON \
-DPythonModular=ON ..
## 依存ライブラリのチェック等が行われ、ビルド構成が表示される
-- Summary of Configuration Variables
--
-- The following OPTIONAL packages have been found:
* GDB
* OpenMP
* BLAS
* Threads
* LAPACK
* Atlas
* GLPK
* Doxygen
* LibXml2
* CURL
* ZLIB
* BZip2
* Spinlock
-- The following REQUIRED packages have been found:
* SWIG (required version >= 2.0.4)
* PythonLibs
* PythonInterp
* NumPy
-- The following OPTIONAL packages have not been found:
* CCache
* Mosek
* CPLEX
* ARPACK
* NLopt
* LpSolve
* ColPack
* ARPREC
* HDF5
* LibLZMA
* SNAPPY
* LZO
-- ==============================================================================================================
-- Enabled Interfaces
-- libshogun is ON
-- python modular is ON
-- octave modular is OFF - enable with -DOctaveModular=ON
-- java modular is OFF - enable with -DJavaModular=ON
-- perl modular is OFF - enable with -DPerlModular=ON
-- ruby modular is OFF - enable with -DRubyModular=ON
-- csharp modular is OFF - enable with -DCSharpModular=ON
-- R modular is OFF - enable with -DRModular=ON
-- lua modular is OFF - enable with -DLuaModular=ON
--
-- Enabled legacy interfaces
-- cmdline static is ON
-- python static is OFF - enable with -DPythonStatic=ON
-- octave static is OFF - enable with -DOctaveStatic=ON
-- matlab static is OFF - enable with -DMatlabStatic=ON
-- R static is OFF - enable with -DRStatic=ON
-- ==============================================================================================================
## 問題なさそうならコンパイル後、インストール
$ make -j32
$ sudo make install
C++11の機能をサポートしているコンパイラならいくつかの機能(std::atomicなど)を利用してくれるようです。redhat6.x系のシステムGCC(v4.4.x)だとC++11のほとんどの機能はサポートされません。
僕の環境ではライブラリ本体の libshogun の他にコマンドラインとPython用のインタフェースをインストールしました。スクリプト言語のインタフェースを多く揃えたい場合はSWIGを別途インストールしておく必要があります。
補足: 依存関係ライブラリのインストール
SWIG
SWIGはC/C++で書かれたモジュール(共有ライブラリ)をスクリプト言語などの高級言語から利用するためのバインディングを作成してくれるツールです。僕もたまに業務でWebインタフェース向けにPHPバインディングをSWIGを使って作ることがあります。2013/11現在、yumでインストールできるパッケージはSHOGUNのバージョン要求を満たしていないので、これもソースからコンパイル/インストールしておきます。debian系の場合は $ apt-get install swig2.0 でOKです。
## 依存パッケージ PCRE (Perl Compatible Regular Expressions) が入っていなければ入れる
$ sudo yum pcre-devel.x86_64
## 古いrpmパッケージが入っていれば消す
$ sudo yum remove swig
$ wget http://prdownloads.sourceforge.net/swig/swig-2.0.11.tar.gz
$ tar zxf swig-2.0.11.tar.gz
$ cd swig-2.0.11
$ ./configure --prefix=/usr/local/swig-2.0.11
$ make -j2
$ sudo make install
## PATHの通ったところにバイナリのシンボリックリンクを貼っておく
$ sudo ln -s /usr/local/swig-2.0.11/bin/swig /usr/local/bin
SWIGとバインディングを作りたい言語の処理系を揃えたら再度SHOGUNをビルドしましょう。
BLAS (ATLAS) / LAPACK / GLPK / Eigen3
線形代数関連のライブラリ群。yumでインストールできるパッケージでOKです。ATLASは最適化されたBLAS実装の一つで、簡単にインストールできるので入れておくと良いです(BLASはリファレンス実装)。また、SHOGUNはGLPKの他にCPLEXにも対応しているようなので、業務用に利用する場合はCPLEXを導入するとさらに性能が上がると思われます。稟議書がんばって書きましょう(アカデミック用途であれば無償で利用できるそうです)。Eigen3については2013/11現在、yumでインストールできるパッケージはSHOGUNのバージョン要求を満たしていませんが、もしEigen3が手元になければソースコード(テンプレートライブラリなのでヘッダファイル群)をダウンロードしてくるようCMakeに指示できるようです。CMakeのオプションに -DBUNDLE_EIGEN=ON を付ければOKです。
## 線形代数関連ライブラリをまとめてインストール
## atlas-devel を入れる場合は lapack-devel は不要です
$ sudo yum install blas-devel.x86_64 lapack-devel.x86_64 atlas-devel.x86_64 glpk-devel.x86_64
NumPy
Pythonインタフェースをインストールする場合はNumPyが必須になっています。NumPyについては以前ブログでも紹介しているので参考までに。ちなみに、OpenCV(コンピュータビジョンライブラリ)のPythonインタフェースもNumPyを利用しています。
インストールはpip(A tool for installing and managing Python packages.)を使えば簡単です。
$ sudo pip install numpy
SHOGUNライブラリの全体像は以下の図の通りで、いまいちよくわかりません。
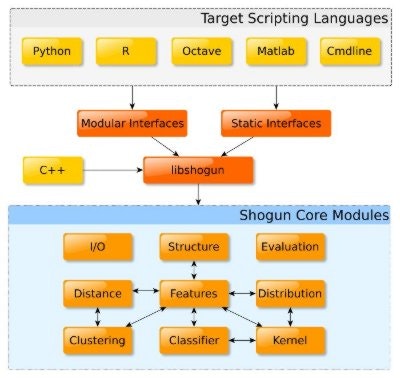
スクリプト言語用のインタフェースはこの図に載っているもの以外にもJavaやRuby, Luaなどもサポートされています。前述の通り、SWIGをインストールして使いたい言語のバインディングを作っておきましょう。
コンパイル時の注意点
物理メモリ/仮想メモリ容量の少ない安物のVPS環境などでSHOGUNをリリースビルドすると、OOM Killer様にcc1plusプロセスを強制的にkillされる可能性が高いです。試しに1GB RAM/2GB Swapの仮想環境で試してみましたが案の定ひどいスコアで殺されてしまいました。。
kernel: Out of memory: Kill process 30340 (cc1plus) score 723 or sacrifice child
kernel: Killed process 30340, UID 500, (cc1plus) total-vm:2468236kB, anon-rss:779716kB, file-rss:2516kB
kernel: cc1plus invoked oom-killer: gfp_mask=0x200da, order=0, oom_adj=0, oom_score_adj=0
その場合はswap容量を増やすことを検討しましょう。仮に物理メモリが1GBしかない場合はおそらく実メモリ容量の2倍程度では足りないので、一時的に4倍程度確保しておくと安全かと思います。OpenVZの仮想環境だとちょっと諦めた方がいいかもしれません。。
あと、VPSのような仮想環境だとinodeが少ないはずなので、学習データを大量に置くことはできないと思います。素直に物理サーバ上に構築した方が懸命です。ここでは32コア/96GB RAMの環境でビルドしましたが、リソース的には十分でスムーズにビルドすることができました。
ちなみに僕の環境におけるGCCの最適化オプションは以下のようになりました。
-march=core2 -mcx16 -msahf -maes -mpclmul -mavx --param l1-cache-size=32 --param l1-cache-line-size=64 --param l2-cache-size=15360 -mtune=generic
hello, world (libshogun)
まずはlibshogunを使って簡単なタスクを実行してみます。SVM(Support Vector Machine)を用いてデータを分類(Classification)するサンプルです。
/* hello_shogun.cpp */
# include <shogun/labels/BinaryLabels.h>
# include <shogun/features/DenseFeatures.h>
# include <shogun/kernel/GaussianKernel.h>
# include <shogun/classifier/svm/LibSVM.h>
# include <shogun/base/init.h>
# include <shogun/lib/common.h>
# include <shogun/io/SGIO.h>
using namespace shogun;
int main(int argc, char** argv) {
// initialize
init_shogun_with_defaults();
// create some data
SGMatrix<float64_t> matrix(2,3);
for(int i=0; i<6; i++) {
matrix.matrix[i] = i;
}
matrix.display_matrix();
// create three 2-dimensional vectors
CDenseFeatures<float64_t>* features = new CDenseFeatures<float64_t>();
features->set_feature_matrix(matrix);
// create three labels
CBinaryLabels* labels = new CBinaryLabels(3);
labels->set_label(0, -1);
labels->set_label(1, +1);
labels->set_label(2, -1);
// create gaussian kernel(RBF) with cache 10MB, width 0.5
CGaussianKernel* kernel = new CGaussianKernel(10, 0.5);
kernel->init(features, features);
// create libsvm with C=10 and train
CLibSVM* svm = new CLibSVM(10, kernel, labels);
svm->train();
SG_SPRINT("total sv:%d, bias:%f\n", svm->get_num_support_vectors(), svm->get_bias());
// classify on training examples
for(int i=0; i<3; i++) {
SG_SPRINT("output[%d]=%f\n", i, svm->apply_one(i));
}
// free up memory
SG_UNREF(svm);
exit_shogun();
return 0;
}
- コンパイルと実行
## 比較的新しいコンパイラならC++11を有効にしてコンパイルすると良いです。
$ g++ -g -Wall -std=c++0x -L/usr/local/lib64 -lshogun hello_shogun.cpp -o hello_shogun
$ ./hello_shogun
matrix=[
[ 0, 2, 4],
[ 1, 3, 5]
]
total sv:3, bias:-0.333333
output[0]=-0.999997
output[1]=1.000003
output[2]=-1.000005
行列から特徴ベクトル(CDenseFeatures)を抽出、正解ラベル(CBinalyLabels)を設定、ガウシアンカーネル(CGaussianKernel)を使ってSVM(CLibSVM)で学習します。以下、いくつか特徴を。
- 行列のレイアウトはColumn-Major (Fortran Order)で扱われる。
- SVMの学習には内部的に LibSVM や SVMLight などの外部ライブラリを利用している。
- スレッドセーフな独自の参照カウント機構によるオブジェクト管理
特徴ベクトルは OpenGL や CUBLAS などと同様にColumn-Majorで行列から読み出されます(1つの列が1つの特徴ベクトルとなる)。SVMの学習には内部的に LibSVM や SVMLight などの外部ライブラリをSHOGUNのインタフェースから利用できます(shogun/classifier/svm/以下を参照)。
メモリ管理の注意点
上記のコードは明らかにメモリリークしてるように見えますが、valgrindでチェックしてみたところ内部で適切にメモリ管理されているようです。SHOGUNは内部で参照カウントによるオブジェクト管理を行っています。この参照カウントをインクリメント/デクリメントするマクロ(SG_REF/SG_UNREF)が定義されているのでこれを使うのですが、全てのインスタンスに対して手動でカウントを操作する必要はありません。SHOGUNのメモリ管理周りの実装を読んでみたのですが、参照先のインスタンスの参照カウントを参照元のインスタンスが解放されるときに(つまりデストラクタ内)デクリメントしています。参照カウントが0以下になった時にインスタンスは解放されるようになっているため、上記のコードにおいてはSVMのインスタンスを解放すれば連鎖的に他のインスタンスも解放されるようになっています。
注意点としては スコープが外れた時はなにもしない という点で、インスタンスを解放するかどうかの判定は参照カウントの変化があった時のみとなります。小さな親切大きなお世話といった感じですけど、仕方がないので上手くこの仕組みと付き合っていく必要がありそうです。いくつか方針を書いてみます。
-
完全手動参照カウント管理
SHOGUNの参照カウントの支配下に置かれている時に、うかつに自分で delete すると二重解放(double free)の危険が出てきます。そこで、クラスのインスタンスを作ると同時に手動で参照カウントをインクリメント(SG_REF)し、インスタンスが必要なくなったら手動でデクリメント(SG_UNREF)するようにします。ARC offのObjective-C方式ですね。ただし、例外安全なコードを書くのは難しくなります。 -
スマートポインタ + 半手動参照カウント管理
比較的新しいC++コンパイラなら std::unique_ptr/std::shared_ptr などが利用できるのでこれを使う方法です。注意点としては前述のようにSHOGUNの参照カウントの支配下においてはインスタンスの参照カウントが0以下になると内部で delete するため、スマートポインタで包んでいるだけだとこれも二重解放の危険があります。そこで、インスタンスを作ったら参照カウントを手動でインクリメントし、デクリメントは行わないことでSHOGUN内部で delete を実行させないようにします。つまり参照カウントを常に1以上にしてSHOGUNによるオブジェクト管理を実質的に意味のないものにします。これなら SG_UNREF 忘れに怯える必要もなく例外安全なコードを書きやすいというメリットがあります。
// C++標準のスマートポインタを利用してインスタンスを作成後、手動でSHOGUNの参照カウントをインクリメント
std::unique_ptr<CDenseFeatures<float64_t> > features(new CDenseFeatures<float64_t>());
SG_REF(features);
// 参照カウントのデクリメントは行わないこと
次は未知のデータを入力にしてみます。訓練データ/テストデータは以下のようにPythonで適当に生成してファイルに書き出したものを利用します。
import numpy as np
def genexamples(n):
class1 = 0.6*np.random.randn(n, 2)
class2 = 1.2*np.random.randn(n, 2) + np.array([5, 1])
labels = np.hstack((np.ones(n), -np.ones(n)))
return (class1, class2, labels)
注意) 以下のコードは libshogun.so.14 未満では動作しないことを確認済み
# include <shogun/labels/BinaryLabels.h>
# include <shogun/features/DenseFeatures.h>
# include <shogun/kernel/GaussianKernel.h>
# include <shogun/classifier/svm/LibSVM.h>
# include <shogun/io/SGIO.h>
# include <shogun/io/CSVFile.h>
# include <shogun/evaluation/ContingencyTableEvaluation.h>
# include <shogun/base/init.h>
# include <shogun/lib/common.h>
using namespace std;
using namespace shogun;
int main(int argc, char** argv) {
try {
init_shogun_with_defaults();
// training examples
CCSVFile train_data_file("traindata.dat");
// labels of the training examples
CCSVFile train_labels_file("labeldata.dat");
// test examples
CCSVFile test_data_file("testdata.dat");
SG_SPRINT("training ...\n");
SGMatrix<float64_t> train_data;
train_data.load(&train_data_file);
CDenseFeatures<float64_t>* train_features = new CDenseFeatures<float64_t>(train_data);
SG_REF(train_features);
SG_SPRINT("num train vectors: %d\n", train_features->get_num_vectors());
CBinaryLabels* train_labels = new CBinaryLabels();
SG_REF(train_labels);
train_labels->load(&train_labels_file);
SG_SPRINT("num train labels: %d\n", train_labels->get_num_labels());
float64_t width = 2.1;
CGaussianKernel* kernel = new CGaussianKernel(10, width);
SG_REF(kernel);
kernel->init(train_features, train_features);
int C = 1.0;
CLibSVM* svm = new CLibSVM(C, kernel, train_labels);
SG_REF(svm);
svm->train();
SG_SPRINT("total sv:%d, bias:%f\n", svm->get_num_support_vectors(), svm->get_bias());
SG_UNREF(train_features);
SG_UNREF(train_labels);
SG_UNREF(kernel);
CBinaryLabels* predict_labels = svm->apply_binary(train_features);
SG_REF(predict_labels);
CErrorRateMeasure* measure = new CErrorRateMeasure();
SG_REF(measure);
measure->evaluate(predict_labels, train_labels);
float64_t accuracy = measure->get_accuracy()*100;
SG_SPRINT("accuracy: %f\%\n", accuracy);
SG_UNREF(predict_labels);
SG_UNREF(measure);
SG_SPRINT("testing ...\n");
SGMatrix<float64_t> test_data;
test_data.load(&test_data_file);
CDenseFeatures<float64_t>* test_features = new CDenseFeatures<float64_t>(test_data);
SG_REF(test_features);
SG_SPRINT("num test vectors: %d\n", test_features->get_num_vectors());
CBinaryLabels* test_labels = svm->apply_binary(test_features);
SG_REF(test_labels);
SG_SPRINT("num test labels: %d\n", test_labels->get_num_labels());
SG_SPRINT("test labels: ");
test_labels->get_labels().display_vector();
CCSVFile test_labels_file("test_labels_file.dat", 'w');
test_labels->save(&test_labels_file);
SG_UNREF(svm);
SG_UNREF(test_features);
SG_UNREF(test_labels);
exit_shogun();
} catch(ShogunException& e) {
SG_SPRINT(e.get_exception_string());
return - 1;
}
return 0;
}
- 実行結果
training ...
num train vectors: 400
num train labels: 400
total sv:37, bias:-0.428868
accuracy: 99.750000%
testing ...
num test vectors: 400
num test labels: 400
test labels: vector=[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1]
SHOGUNはクラス設計の粒度もちょうど良く、APIも十分抽象化されているのですが、参照カウントの操作が入るとコードが汚くなりますね。。また、学習データは CCSVFile クラスを使ってファイルから読み込ませています。CSVと名前がついてますが、CSV形式ではなくスペース区切りで二次元データが書かれたファイルも読み込むことができます。
SHOGUNとOpenCVと仲良くさせるには、shogun::SGMatrix と cv::Mat を相互変換できるようなアダプタを作ると便利かもしれません。あと、OpenCVはCUDA対応も進んでいるのでSHOGUNもぜひ対応して欲しいところです。
Python Modular
次はSHOGUNのPythonバインディングを使ってみます。python_static と python_modular の2つが提供されていますが、python_modular の方がインタフェースがスマートなのでこちらを使います。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import modshogun as sg
import numpy as np
import matplotlib.pyplot as plt
def classifier():
train_datafile = sg.CSVFile('traindata.dat')
train_labelsfile = sg.CSVFile('labeldata.dat')
test_datafile = sg.CSVFile('testdata.dat')
train_features = sg.RealFeatures(train_datafile)
train_labels = sg.BinaryLabels(train_labelsfile)
test_features = sg.RealFeatures(test_datafile)
print('training ...')
width = 2.1
kernel = sg.GaussianKernel(train_features, train_features, width)
C = 1.0
svm = sg.LibSVM(C, kernel, train_labels)
svm.train()
sv = svm.get_support_vectors()
bias = svm.get_bias()
print('total sv:%s, bias:%s' % (len(sv), bias))
predict_labels = svm.apply(train_features)
measure = sg.ErrorRateMeasure()
measure.evaluate(predict_labels, train_labels)
print('accuracy: %s%%' % (measure.get_accuracy()*100))
print('testing ...')
test_labels = svm.apply(test_features)
print(test_labels.get_labels())
if __name__=='__main__':
classifier()
- 実行結果
training ...
total sv:37, bias:-0.428868128708
accuracy: 99.75%
testing ...
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
... 省略
C++(libshogun)版と同じ結果が得られました。分類結果をmatplotlibを使って可視化してみます。
import numpy as np
import matplotlib.pyplot as plt
## 分類境界を取得
def getboundary(plotrange, classifier):
x = np.arange(plotrange[0], plotrange[1], .1)
y = np.arange(plotrange[2], plotrange[3], .1)
xx, yy = np.meshgrid(x, y)
gridmatrix = np.vstack((xx.flatten(), yy.flatten()))
gridfeatures = sg.RealFeatures(gridmatrix)
gridlabels = classifier.apply(gridfeatures)
zz = gridlabels.get_labels().reshape(xx.shape)
return (xx, yy, zz)
## 描画範囲と分類器を指定して分類境界を得る
xx, yy, zz = getboundary([-4,8,-4,5], svm)
## 分類境界を描画
plt.contour(xx, yy, zz, [1,-1])
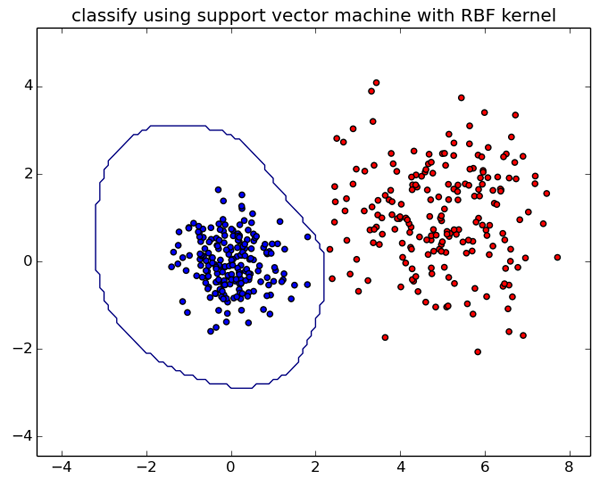
とりあえず、C++とPythonでの簡単な使い方を整理しました。SHOGUNにはSVMだけでなく様々な機械学習アルゴリズムが実装されているので、より実践的なタスクを使って検証を進めていきたいと思います。