Rには、分析手法や可視化手法を試すことのできる多くのデータセットが同梱されています。
その数は2016年12月現在で104個にも達していますが、その大半はあまり紹介されることがなく、知る機会も多くはありません。「ヘルプが英語で書かれている」というのもその要因の1つでしょうが、「数が多すぎて、何に使えるのか把握しきれない」という理由も大きいのではないでしょうか。
実は、
- 間瀬先生のR 基本統計関数マニュアル の巻末
- パッケージ 'datasets' の情報 - RjpWiki
- R 3.3.1の datasets パッケージ中のオブジェクトの全ヘルプドキュメント一覧 (Google Docs)
などに情報がまとまっているのですが、アルファベット順に表記されているため、データの「構造」でソートしたものがあってもいいんじゃないかな、とふと思いました。
これらのデータについておおまかに分類して、概要だけでも一覧にしておけば、データの分析や可視化を試したり人に紹介したりする際にも便利なのではないでしょうか。というか、僕にとって便利です。本記事はところどころ文体が乱れていますが、もうすぐクリスマスだしどうかお許しください。いや、まだだけど。
Rの標準データセットはRだけでなく、PythonやJuliaからも使うことができます。方法については、以下の記事を参照して下さい。
なお、Rに組み込まれてるかどうかは問わないからオープンなデータセットとしてどんなものがあるか知りたい! という方は
-
UCI Machine Learning Repository
- 機械学習に使える350個のデータセットが紹介されている。
- UCI Machine Learning Repository をマイニングする(Machine Learning Advent Calendar 12日目) - 糞ネット弁慶
- 統計を学びたい人へ贈る、統計解析に使えるデータセットまとめ - ほくそ笑む
- データセット一覧 : DoDStat@d
- フリーなデータセットへのリンク集 - RjpWiki
- 機械学習に使える、オープンデータ一覧 ※随時更新 - Beginning AI
なども合わせてご覧ください。
以下では、Rの{datasets}パッケージに含まれている標準データセットについて、
「class()関数を適用したときに表示されるオブジェクトのクラス」に従って
- 「表形式」のデータ
- データフレーム
- n次元の分割表
- n次元の配列
- 「表形式」ではないデータ
- リスト
- 時系列データ
- その他
に分けています。ざっくりまとめたので間違いがあるかもしれません。いや、きっとあるでしょう。
識者の方からのご指摘を切にお待ちしております。
Enjoy!
1. 「表形式」のデータ
この記事ではあくまで便宜的に、「行」と「列」をあわせ持っているデータを「表形式」と呼ぶことにします。
Rの組み込みデータや読み込まれたデータが「行(row)」や「列(column)」を持っているかどうかは、データの行数を返すnrow()関数やデータの列数を返すncol()関数で確認することができます。
たとえば、次のようにnrow()およびncol()の結果がNULLになってしまう場合は「表形式」とは呼ばないことにします。
> x <- 1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> nrow(x)
NULL
> ncol(x)
NULL
一方、後ほど紹介するcarsデータに対してnrow()関数とncol()関数を適用してみると、次のようになります。
> nrow(cars)
[1] 50
> ncol(cars)
[1] 2
データについて次元ごとの要素数を出力するdim()関数を使って、次のように確認することもできます。
> dim(cars)
[1] 50 2
これは、carsデータの次元数が2であり、50行2列の要素で構成されていることを示しています。Rでは、ひとつめの次元が「行」、ふたつめの次元が「列」とみなされるからです。
1-1. データフレーム
標準データセットに含まれるデータのうち、データフレームは約4割を占めています。
| class | count | percent |
|---|---|---|
| data.frame | 44 | 42.31 |
| ts | 29 | 27.88 |
| matrix | 9 | 8.65 |
| ... | ... | ... |
| 計 | 104 | 100.00 |
圧倒的に最大派閥ですね。
データフレームには、いくつかの変数 (variables) ごとに、それぞれ同じ数の観測値 (observations) が格納されています。例えば、carsデータには"speed"と"dist"という2つの変数について、50回分の観測値(obs.)が格納されています。
> str(cars)
'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
次のようにしてデータの末尾からn個分の観測値を見てみると、それぞれ1回分の「観測値のセット」が行に、変数ごとのデータが列(speed, dist)に対応していることがわかります。
> tail(cars, n = 5)
speed dist
46 24 70
47 24 92
48 24 93
49 24 120
50 25 85
因子について
標準データセットに含まれるデータフレームのうち半分弱の20個が、因子 (factor) のクラス属性を持った変数(列)を持っています。これは、カテゴリカルデータとしての性質をもつ変数のために用意されたRの機能です。
たとえばirisデータの変数をみてみると、Species(品種)の箇所に"Factor"と書かれています。
> str(iris)
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
属性情報を表示するattributes()関数をSpecies列に対して適用すると、この列には"factor"のclass属性と、("setosa", "versicolor","virginica")のlevels属性が付与されていることが確認できます。このlevels属性で与えられてるものを「水準」と言ったりします。
> attributes(iris$Species)
$levels
[1] "setosa" "versicolor" "virginica"
$class
[1] "factor"
以後、「"factor"のclass属性を持っている」ものを単に因子と呼ぶことにします。
因子を含まない場合
列数が2の場合
長さの等しい2つのベクトルがあったとき、次のようにすると、2変数の散布図が描画できます。
> plot(x = cars$speed, y = cars$dist, xlab = "speed", ylab = "dist")
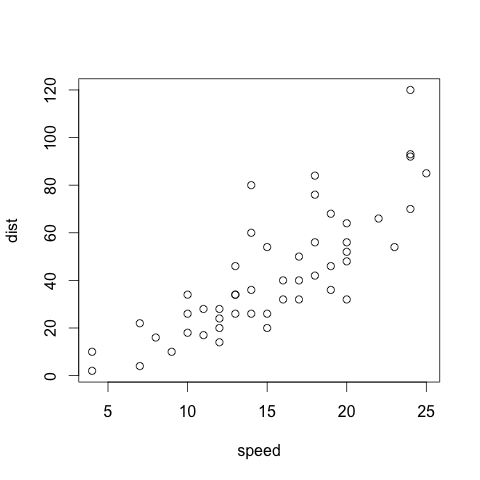
列数が2、つまり2変数からなるデータフレームの場合には左から数えて1, 2列目の変数が自動的にx, y軸として解釈されるため、次のようにしても上と同じ図が得られます。
> plot(cars)
因子を含まないもののうち、carsデータのように列数が2の場合のデータセットは次の6件です。
なお、以降の表は、ncol:列数(NCOL()の結果)およびsize:キロバイト単位のオブジェクトサイズ(object.size()の結果)でソートしてあります。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| women | data.frame | 2 | 15 | 2 | 1.01 | Average Heights and Weights for American Women |
| BOD | data.frame | 2 | 6 | 2 | 1.06 | Biochemical Oxygen Demand |
| pressure | data.frame | 2 | 19 | 2 | 1.07 | Vapor Pressure of Mercury as a Function of Temperature |
| Formaldehyde | data.frame | 2 | 6 | 2 | 1.17 | Determination of Formaldehyde |
| cars | data.frame | 2 | 50 | 2 | 1.54 | Speed and Stopping Distances of Cars |
| faithful | data.frame | 2 | 272 | 2 | 5.02 | Old Faithful Geyser Data |
- women
- 米国の30~39歳女性の身長(インチ)と体重(ポンド)の平均データ。
- 単純にプロットする例には使えるけど、あまり他に使いみちが思いつきません。データ綺麗すぎませんか...?
- pressure
- 温度と水銀の蒸気圧(vapor pressure)のデータ。
- 温度に対して圧力が「指数的」に増加しているので、データを対数変換したらどうなるかを紹介するのに便利です。
- Formaldehyde
- 「濃度が未知の溶液を定量したい時に、同じ溶液で濃度が既知のものをいくつか用意し、目的物質と反応する呈色試薬を混ぜ、吸光度の変化を分光光度計で測り検量線をひく」という大学初年度の生化学実験でありがちなテーマです。
- 2変数間に厳密な比例関係があることが化学式などから予測でき、それを実測から確かめればいいなら
lm()を使って線形回帰を行えば良いことがわかります。
- cars
- 自動車の速度と制動距離のデータ。
- 速度と制動距離は一見比例していそうですが、2変量間の法則性が単純な1次式で表せるようなFormaldehydeに比べるとばらつきが大きいです。そのため、
lm()の説明変数にxをn乗したものを使ってあてはめを試みる例として使われています。
- BOD
- BODとは生物化学的酸素要求量のこと。値が大きければ水質が悪いという指標です。
- Exampleには非線形回帰手法のひとつである非線形最小二乗法(nonlinear least square)を
nls()関数で適用した例が載っています。個人的には、「因子を含む場合」の項で後述するPuromycinデータの方が説明に使いやすそうだなと感じます。
- faithful
- オールド・フェイスフル・ガイザーという別名を持つイエローストーン国立公園の間欠泉のデータ。"faithful"とは本来「忠実」という意味の英単語ですが、この間欠泉が「忠実」にほぼ一定の時間間隔で噴出することによりこの名前がついたそうです。
- 二次元正規分布の紹介に便利そうだなーと思ったらPRML 2.3.9節でまさにその例として使われてました。
列数が3以上の場合
変数(列)の数が2の場合はplot()関数で散布図が描けましたが、変数の数が3以上の場合は各変数間の関係が対散布図として描かれます。
> str(trees)
'data.frame': 31 obs. of 3 variables:
$ Girth : num 8.3 8.6 8.8 10.5 10.7 10.8 11 11 11.1 11.2 ...
$ Height: num 70 65 63 72 81 83 66 75 80 75 ...
$ Volume: num 10.3 10.3 10.2 16.4 18.8 19.7 15.6 18.2 22.6 19.9 ...
> plot(trees)
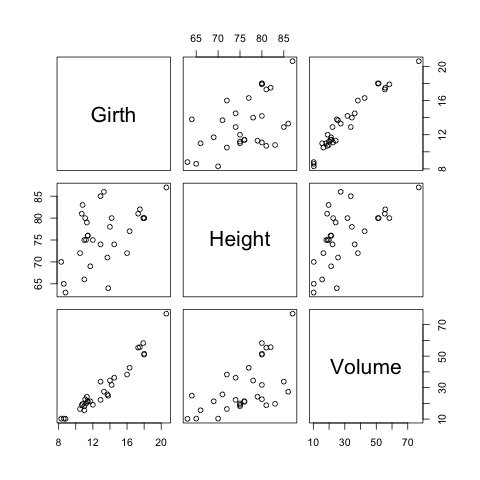
これは実はpairs()関数を呼び出しているだけなので、次のようにもしても同じ図が得られます。
> pairs(trees)
treesデータのように、全ての変数が測定値である場合はよいのですが、変数として記録されている値が単に「カテゴリー」である場合は少し扱いを変えたほうがいい事があります。
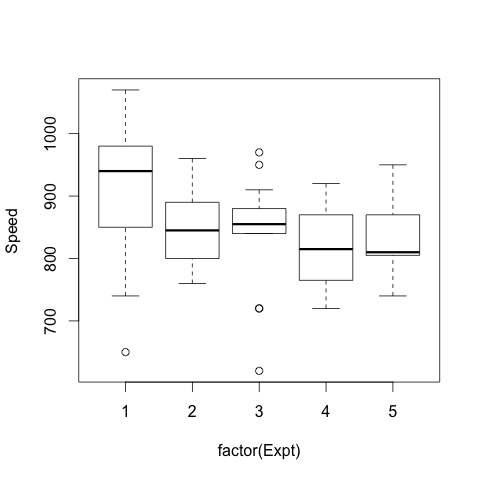
morleyデータは、5回の実験(Expt)ごとに10Run分の測定を行ったデータです。
> str(morley)
'data.frame': 100 obs. of 3 variables:
$ Expt : int 1 1 1 1 1 1 1 1 1 1 ...
$ Run : int 1 2 3 4 5 6 7 8 9 10 ...
$ Speed: int 850 740 900 1070 930 850 950 980 980 880 ...
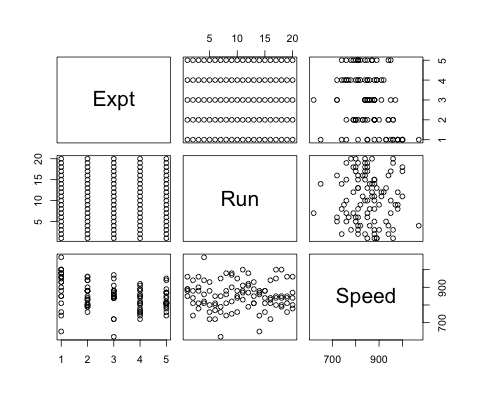
このデータで知りたいのは、実験(Expt)ごとにSpeedのばらつきがないかどうかなので、
> boxplot(Speed ~ Expt, data = morley, xlab = "Expt", ylab = "Speed")
のようにして箱ひげ図や蜂群図を描くほうが可視化としては適切かもしれません。
因子を含まないもののうち、列数が3より多いものは次の18件です。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| trees | data.frame | 2 | 31 | 3 | 1.60 | Girth, Height and Volume for Black Cherry Trees |
| morley | data.frame | 2 | 100 | 3 | 7.51 | Michelson Speed of Light Data |
| randu | data.frame | 2 | 400 | 3 | 10.25 | Random Numbers from Congruential Generator RANDU |
| stackloss | data.frame | 2 | 21 | 4 | 1.65 | Brownlee's Stack Loss Plant Data |
| rock | data.frame | 2 | 48 | 4 | 2.27 | Measurements on Petroleum Rock Samples |
| beaver2 | data.frame | 2 | 100 | 4 | 4.09 | Body Temperature Series of Two Beavers |
| beaver1 | data.frame | 2 | 114 | 4 | 4.52 | Body Temperature Series of Two Beavers |
| USArrests | data.frame | 2 | 50 | 4 | 5.11 | Violent Crime Rates by US State |
| freeny | data.frame | 2 | 39 | 5 | 5.17 | Freeny's Revenue Data |
| LifeCycleSavings | data.frame | 2 | 50 | 5 | 5.91 | Intercountry Life-Cycle Savings Data |
| quakes | data.frame | 2 | 1000 | 5 | 32.34 | Locations of Earthquakes off Fiji |
| airquality | data.frame | 2 | 153 | 6 | 5.37 | New York Air Quality Measurements |
| swiss | data.frame | 2 | 47 | 6 | 5.81 | Swiss Fertility and Socioeconomic Indicators (1888) Data |
| longley | data.frame | 2 | 16 | 7 | 2.19 | Longley's Economic Regression Data |
| attitude | data.frame | 2 | 30 | 7 | 2.95 | The Chatterjee-Price Attitude Data |
| anscombe | data.frame | 2 | 11 | 8 | 2.37 | Anscombe's Quartet of 'Identical' Simple Linear Regressions |
| mtcars | data.frame | 2 | 32 | 11 | 6.58 | Motor Trend Car Road Tests |
| USJudgeRatings | data.frame | 2 | 43 | 12 | 8.55 | Lawyers' Ratings of State Judges in the US Superior Court |
-
trees
- 31本のBlack cherryの倒木の外周長(地面から4フィート6インチの円周)・樹高・容積データ。
- 円周は半径の定数倍なので、「樹木の容積は外周長の2乗と樹高の積に比例しそうだな」と予想できます。Exampleでは
lm()の説明変数に対数変換した外周長と樹高を用い、ステップワイズアルゴリズムで変数選択しながらこれを確かめています。coplot()の使用例もあります。
-
morley
- マイケルソン・モーリーの実験として高校物理の教科書に載ってるやつです。より詳しくはMichelson-Morley の実験 | Haruhiko Okumuraをぜひご覧ください。
- ExptとRunの列は測定値ではなくてラベルなので、因子にするほうがおそらく適切です。
{MASS}パッケージにはこれらの列がちゃんと因子になってるmichelsonというデータがあります。
-
randu
- 乱数からなるデータフレーム。
set.seed()を使うと乱数を使って固定のデータを作れるのですが、これはあくまで擬似乱数なので偏りが生まれています。3次元plotした上で、ある角度から見ると15の平面上に点が偏って存在していることがわかるコードがPlotting randu dataset
で紹介されています。実行してグリグリ動かしてみると楽しいです。
- 乱数からなるデータフレーム。
-
stackloss
- アンモニアを酸化して硝酸を製造する化学プラントでの、21日分の生産効率(損失割合)データ。
- S-PLUSとの互換性のために目的変数と説明変数を分けた
stack.loss(ベクトル)およびstack.x(行列)が用意されています。
-
rock
- 油田の油層でとれた石の透過性(permeability)についてのデータ。油田というのは地下に石油がぷかぷか存在しているわけではなく、多孔性の岩石の空隙に水とともに染みこんで存在しているそうです。そこで、油田の調査においては油層とよばれる「石油が染みこんだ岩石がたくさんある地層」のサンプルを調べることになります。
-
射影追跡回帰(projection pursuit regression)の例として、
ppr()関数のExampleで使われています。
-
beaver1, beaver2
- ビーバーの体温と、その時巣穴の中にいたかどうかを経時的に計測したデータ。1,2というのはそれぞれ別の個体について測定したもので、測定した日時も同時ではありません。beaver1はほとんど巣穴の外で活動しておらず、22:20 のデータが欠損しています。
- これ時刻データはts型にすべきだすし、活動性指標は因子にしたほうがよさそうな気がします。
{MASS}パッケージにはbeav1, beav2としてほぼ同じデータが同梱されており、それぞれのExampleには時刻データをtsクラスに変換してacf()で自己相関をみる例が載っています。beav2のExampleには、{nlme}パッケージのgls()関数で体温を活動性指標で説明できるかを試している例も載っています。
-
USArrests
- 3種の犯罪について、人口10万対の逮捕者率と都市部(urban)住民比率が50州ぶん入ってるデータ。
- クラスタリング・主成分分析などの例に用いられています。とくに
prcomp()関数のExampleをみると、このデータは変数ごとの分散が大きく異なるため、分散が等しくなるようデータをスケーリングする(scale=TRUE)ことの必要性がわかっておもしろいです。ちゃんとスケーリングしたものをbiplotすると、暴行と殺人の逮捕者のベクトルは都市部住民比率とほぼ直交していて、少なくとも「都市化と暴行・殺人の増加」にはあまり関係性がなさそうだとわかります。
-
freeny
- フリーニーによる四半期ごとの歳入データ。目的変数だけを切り出したfreeny.y (ts)というデータと説明変数のカラムだけを切り出したfreeny.x (matrix) というデータもあります。
-
LifeCycleSavings
- 人口に対する年齢構成比率と可処分所得のデータが50カ国ぶん入っている。行(row.names)は国名になっています。
-
quakes
- Fiji(フィジー)を中心に観測されたマグニチュード4以上の地震のデータ。
- 揺れを感じた観測所の数がマグニチュードと相関してて、ああ地震の大きさってほんとにマグニチュードで測れるんだなってのが分かって面白いです。
-
airquality
- ニューヨークのルーズベルト島で観測したオゾン濃度の時系列データ。多変量解析の教科書で時々目にする印象です。月と日でそれぞれ1列ずつ使っています。
-
swiss
- 1888年頃のスイスのフランス語圏47行政区の、0~100で標準化された出生率と、100分率で表された5種類の社会・経済指標データが格納されています。
-
longley
- Longleyによる米国経済の時系列データ。16行7列からなっており第7列めに雇用者数のデータが有る。rownameが年になっている。高い共線性(co-lineality)を示すデータの例として知られています。
-
attitude
- とある金融機関における各部署の職員の意識調査(attitude survey)データ。6つの質問に加えて、全体の満足度(rating)についても訊いており、計7つの質問項目について、各部署で「好意的」な解答をした人の割合を出しています。
- "clerical" って書いてあるから白魔法でも使えるのかなって思ったら"clerical empryoee"で事務職員のことでした。
-
anscombe
- アンスコム先生のデータセット 。x1とy1, x2とy2...がそれぞれ対応しています。「ぜんぜん違うデータに対しておんなじ回帰直線が引けるから単回帰盲信しちゃだめだぞ」ってことがわかるとても教育的なデータセットなのにヘルプが淡白すぎだし列名が美しくない...つらい...
-
mtcars
- 1974年の「Motor Trend」誌から抽出された32の車種に対するスペック一覧。燃費の他,デザインなどの評価データが含まれている。Transmittionとかはfactorとして扱うべきでは...
-
USJudgeRatings
- コネチカット州地裁の裁判官に対する12種のrating。
因子を含む場合
因子というのをどういうときに使うかというと、グループ間で比較をしたい場合に使うといいんじゃないかと思います。
要するにこのデータはA群のもの、このデータはB群のものというようにラベルを貼っておいて、AとBの違いをみたいときに便利です。べつに2群じゃなくてもn個のラベルを貼ってn群間の比較を行っても良いんですが、n行のデータセットでn個のラベルが張られていたらちょっと変ですよね。それIDじゃん。
というわけで因子の列を含むデータセットには「あらかじめこの群とこの群を比較したい」という意思があると思うのです。
そうそう、データセット中にたまたまそのグループのデータが入ってこない時も、因子の水準に含めておくといいことがあったりします。
水準っていうのは
> levels(iris$Species)
[1] "setosa" "versicolor" "virginica"
これですね。
たとえば47都道府県で売上の群間比較をしたいと思った時に、今月は◯◯県からの売上がたまたまないからといってクロス集計表から◯◯県のカラムが抜け落ちたりしたら不便ですよね。
そういうデータを単純にtable()関数を使って集計すると、データセット中にないラベルは0としてのカウントすらされずに抜け落ちてしまいますが、あらかじめlevels()関数で水準を与えておけばそういう事態は防げます。
脱線してしまった。
因子に順序のない場合
12件あります。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| PlantGrowth | data.frame | 2 | 30 | 2 | 1.64 | Results from an Experiment on Plant Growth |
| InsectSprays | data.frame | 2 | 72 | 2 | 2.28 | Effectiveness of Insect Sprays |
| chickwts | data.frame | 2 | 71 | 2 | 2.30 | Chicken Weights by Feed Type |
| Puromycin | data.frame | 2 | 23 | 3 | 2.04 | Reaction Velocity of an Enzymatic Reaction |
| ToothGrowth | data.frame | 2 | 60 | 3 | 2.51 | The Effect of Vitamin C on Tooth Growth in Guinea Pigs |
| sleep | data.frame | 2 | 20 | 3 | 2.69 | Student's Sleep Data |
| warpbreaks | data.frame | 2 | 54 | 3 | 2.70 | The Number of Breaks in Yarn during Weaving |
| OrchardSprays | data.frame | 2 | 64 | 4 | 3.52 | Potency of Orchard Sprays |
| npk | data.frame | 2 | 24 | 5 | 3.83 | Classical N, P, K Factorial Experiment |
| iris | data.frame | 2 | 150 | 5 | 6.92 | Edgar Anderson's Iris Data |
| attenu | data.frame | 2 | 182 | 5 | 14.23 | The Joyner-Boore Attenuation Data |
| infert | data.frame | 2 | 248 | 8 | 15.48 | Infertility after Spontaneous and Induced Abortion |
- PlantGrowth
- 3群の比較のテストができる
- InsectSprays
- 箱ひげ書いたりaov(analycis of variance model)に使ったり
- 箱ひげじゃなくてstripchartとかbeeswarmがいいって奥村先生がいってました。boxplotでもplotでも、attachしてベクトルそのものを与えるか、
boxplot(count ~ spray, data = InsectSprays)みたいにexpressionにしてあげないとちゃんと解釈してくれないので悲しい気持ちになります。 - ちなみに箱ひげ図はデータ量が多い時にしかたなくやるもので、データ量が少ない時は個々の点をプロットしてもいいと思います。
- chickwts
- ニワトリの体重を、同じ餌を与えたグループごとで測ったもの。
- Puromycin
- ミカエリス=メンテンの式のフィッティングができてるのがわかっておもしろい。ガウス・ニュートン法 - Wikipediaでは非線形最小二乗法の例としてまさにミカエリス=メンテンの式がのっています。Rでは
nls()で非線形最小二乗法の計算ができるし、もっと言えばミカエリス=メンテンのモデルがSSmicmen()として用意されています。 -
attr(*, "reference")= chr "A1.3, p. 269"のように、referenceとして独自の属性が付与されている例でもあります。
- ミカエリス=メンテンの式のフィッティングができてるのがわかっておもしろい。ガウス・ニュートン法 - Wikipediaでは非線形最小二乗法の例としてまさにミカエリス=メンテンの式がのっています。Rでは
- ToothGrowth
- guinea pig (モルモット)の象牙芽細胞の反応を見たデータ。ビタミンC(VC)とオレンジジュース(OJ)の2種の投与量を0.5~2.0の間で振って影響をみています。しかしcoplotのpanel.smoothって中身をよくわからずに書けちゃうのでちょっと怖いですね。
- sleep
-
t.test(extra ~ group, data = sleep, paird = TRUE)で対応のあるt検定の練習ができてべんり。
-
- warpbreaks
- 織物を織るときの縦糸の織機当たり(一定の紡ぎ糸の長さ当たり)の切断数(breaks)。
xtabs()つかうと分割表つくれるよ!
- 織物を織るときの縦糸の織機当たり(一定の紡ぎ糸の長さ当たり)の切断数(breaks)。
- OrchardSprays
- 果樹園(Orchard)になんか散布する
- npk
- 肥料の三要素とも言われる窒素(N)、リン酸(P)、カリウム(K)の有無(2^3 =8通り)で生産量がどれくらいかわったかみたいなのがわかるデータ。どうでもいいけど英語ではカリウムのことpotassiumって表記されるから「なんでkやねん!nppやろ!」って英語圏の学生はブチ切れてるかもなって思いました。ちなみにpotassiumってpot+ashが語源なので灰って意味だそうですが、昔は植物なんかを燃やした灰が肥料に使われてたとかなんとか
- iris
- みんな大好きirisデータ。アヤメ(iris)の3品種各50サンプルに対し、がくと花弁について、それぞれ長さと幅を計測しています。
- irisの正体 (R Advent Calendar 2012 6日目) - どんな鳥もにデータの詳細について書かれています。
- attenu
- カリフォルニアの23の観測所で地震の減衰(attenuation)を調べたデータ。
- infert
- 自然/誘発流産後の不妊(infertility)の比較データ。
glmの例として使われています。
- 自然/誘発流産後の不妊(infertility)の比較データ。
因子に順序がある場合
8件あります。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| Orange | data.frame | 2 | 35 | 3 | 4.79 | Growth of Orange Trees |
| Indometh | data.frame | 2 | 66 | 3 | 5.44 | Pharmacokinetics of Indomethacin |
| DNase | data.frame | 2 | 176 | 3 | 7.72 | Elisa assay of DNase |
| Loblolly | data.frame | 2 | 84 | 3 | 10.79 | Growth of Loblolly pine trees |
| ChickWeight | data.frame | 2 | 578 | 4 | 21.41 | Weight versus age of chicks on different diets |
| esoph | data.frame | 2 | 88 | 5 | 5.49 | Smoking, Alcohol and (O)esophageal Cancer |
| CO2 | data.frame | 2 | 84 | 5 | 9.24 | Carbon Dioxide Uptake in Grass Plants |
| Theoph | data.frame | 2 | 132 | 5 | 9.36 | Pharmacokinetics of Theophylline |
- Orange
- TreeのIDがfactorになっており、観測日と木の周囲ながさの3列からなるデータ。最大直径が大きくなる順に順序付けられている。attrでlabelsとunitsが確認できて便利
- Indometh
- インドメタシン。すばやさがあがるアイテムのことではありません。
SSbiexp()でfittingしてるので参照
- インドメタシン。すばやさがあがるアイテムのことではありません。
- DNase
- 酵素免疫吸着測定法によるネズミ血清の組み換え分解酵素定量データ。DNaseとはDNA分解酵素の意味。実験を行った順番にorderedされています。のこり2列はconcとdensity(比色分析
- Loblolly
- テーダマツのデータ。どの種から由来しているか、が順序付き因子になっている。これもlabelsとunitsのattributeがついてて便利
- ChickWeight
- Chickが順序つき因子になっています。
chickwtsと比較すると、時刻情報がある、トリにIDが振られているなどの違いがあります。
- Chickが順序つき因子になっています。
- esoph
- 食道がん(esophageal cancer)の検査データ。
glm()の例が載っています
- 食道がん(esophageal cancer)の検査データ。
- CO2
- 小文字のco2のほうは時系列データ。
- Theoph
- テオフィリン(Theophylline)の薬物動態。
nls()してる
- テオフィリン(Theophylline)の薬物動態。
1-2. 分割表データ
Rで表形式のデータを格納するもっとも標準的な方法はデータフレームですが、よっぽど集計作業に毒された人以外は、表と言われて思いつくのは「集計後」の分割表なんじゃないだろうかもしかして。
分割表とは、カテゴリカルデータを集計した結果の表です。
因子列を含むデータセットなら、xtabs()を使うことでデータフレームを分割表に変換できます。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| UCBAdmissions | table | 3 | 2 | 2 | 1.77 | Student Admissions at UC Berkeley |
| Titanic | table | 4 | 4 | 2 | 1.91 | Survival of passengers on the Titanic |
| HairEyeColor | table | 3 | 4 | 4 | 1.82 | Hair and Eye Color of Statistics Students |
| occupationalStatus | table | 2 | 8 | 8 | 2.03 | Occupational Status of Fathers and their Sons |
| crimtab | table | 2 | 42 | 22 | 7.75 | Student's 3000 Criminals Data |
- UCBAdmissions
- UCバークレーの入学者データ。6つの学部別,性別の合否結果
- Titanic
- 豪華客船タイタニック号沈没事故時における乗船者の生存/死亡データ。客室、性別、大人/子供、生死の4次元で集計されています。どの状況だったら生きてるか死んでるかを予測するというテーマに使えます。決定木とか...。Kaggleでテストコンペにも使われている題材ですが、Kaggleの方は予測のためにより詳細なデータセットが公開されています。
- HairEyeColor
- なんかの授業の受講者の髪の毛と眼の色をまとめたデータ。市場のシェア可視化みたいなときにも使われるモザイクプロットの例が載っている。※業界地図だとカテゴリ別に集計されてるわけではないので厳密には違います
- occupationalStatus
- イギリスの父子3498例について子供の階級と親の出身階級をしらべたデータ。もとは一般化非線形モデル(generalized nonlinear model)を扱う
{gnm}パッケージに存在していました。
- イギリスの父子3498例について子供の階級と親の出身階級をしらべたデータ。もとは一般化非線形モデル(generalized nonlinear model)を扱う
- crimtab
- 犯罪者の指の長さと身長の著大な分割表データ。行の単位はmmなのに、列の区分がinch区切りにしておけばいいものをわざわざ2.54をかけてセンチメートルになおしてくれているおかげで一見狂ったデータセットになっています。
なお、因子を含むデータフレームを分割表にしたい場合は、以下のようにするとできます。
> tapply(warpbreaks$breaks, warpbreaks[,-1], sum)
tension
wool L M H
A 401 216 221
B 254 259 169
> xtabs(warpbreaks)
tension
wool L M H
A 401 216 221
B 254 259 169
補足1: 高次の分割表をフラットなテーブル(ftable)形式に直す
> stats::ftable(Titanic)
Survived No Yes
Class Sex Age
1st Male Child 0 5
Adult 118 57
Female Child 0 1
Adult 4 140
2nd Male Child 0 11
Adult 154 14
Female Child 0 13
Adult 13 80
3rd Male Child 35 13
Adult 387 75
Female Child 17 14
Adult 89 76
Crew Male Child 0 0
Adult 670 192
Female Child 0 0
Adult 3 20
補足2: 分割表からデータフレームへの変換
2201行×4列のデータフレームに変換することができます。
> titanic <- vcdExtra::expand.dft(Titanic)
> nrow(titanic)
[1] 2201
> head(titanic, n = 3)
Class Sex Age Survived
1 3rd Male Child No
2 3rd Male Child No
3 3rd Male Child No
1-3. 行列データ
12件あります。
内訳は、
- n次元の配列(array)が1件
- 2次元の配列(matrix)が9件
- 距離行列 2件
です。
実は、matrixはarrayの(n=2)の場合ですし、前段で紹介した分割表はtableクラスを付与されたarrayオブジェクトなのですが、本稿では詳しく紹介しません。
また、距離行列はdistクラスを付与されたmatrixオブジェクトですが、使用目的が単なるmatrixの範囲とは大きく異なるため、項目を分けています。
| item | class | ndim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| iris3 | array | 3 | 50 | 4 | 5.59 | Edgar Anderson's Iris Data |
| stack.x | matrix | 2 | 21 | 3 | 1.09 | Brownlee's Stack Loss Plant Data |
| VADeaths | matrix | 2 | 5 | 4 | 1.12 | Death Rates in Virginia (1940) |
| freeny.x | matrix | 2 | 39 | 4 | 1.90 | Freeny's Revenue Data |
| EuStockMarkets | matrix | 2 | 1860 | 4 | 59.24 | Daily Closing Prices of Major European Stock Indices, 1991-1998 |
| USPersonalExpenditure | matrix | 2 | 5 | 5 | 1.30 | Personal Expenditure Data |
| WorldPhones | matrix | 2 | 7 | 7 | 1.61 | The World's Telephones |
| state.x77 | matrix | 2 | 50 | 8 | 7.00 | US State Facts and Figures |
| euro.cross | matrix | 2 | 11 | 11 | 2.66 | Conversion Rates of Euro Currencies |
| volcano | matrix | 2 | 87 | 61 | 41.66 | Topographic Information on Auckland's Maunga Whau Volcano |
- iris3
-
irisデータの品種列のラベルを3つめの軸にして、元のデータを3次元にしたもの。
-
- stack.x
- stacklossのxデータ。stack.lossが目的変数(従属変数)
- VADeaths
- 1940年のバージニア州の死亡率(人口1000対)
- freeny.x
- freenyのxデータ
- EuStockMarkets
- 1991〜1998年のヨーロッパの主要株式指標の終値。多変量時系列データ(mts)
- USPersonalExpenditure
- アメリカのカテゴリー別個人消費データ(単位:10億ドル)
- WorldPhones
- 世界の電話台数(単位:1000台)
- state.x77
- アメリカ50州の人口、収入、識字率など8種の統計データ。
- euro.cross
- ヨーロッパ通貨の交換比率を示した行列。
outer(1/euro, euro)でつくれる。
- ヨーロッパ通貨の交換比率を示した行列。
- volcano
- 等高線を書くのに使われてたりする
2. 「表形式」ではないデータ
2-1. リスト
「リストとデータフレームが別になってる。この分け方おかしいんじゃないの」、と思ったあなたはたぶん正しい。
この記事では詳しく述べませんが、データフレームは広義のリストに含まれます。
attr(iris, "class") <- NULLとかやって遊ぶと楽しい。
- list 4件
| item | class | dim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| state.center | list | 0 | 2 | 1 | 1.17 | US State Facts and Figures |
| ability.cov | list | 0 | 3 | 1 | 1.90 | Ability and Intelligence Tests |
| Harman23.cor | list | 0 | 3 | 1 | 2.43 | Harman Example 2.3 |
| Harman74.cor | list | 0 | 3 | 1 | 8.93 | Harman Example 7.4 |
- state.center
- アメリカ50州の地理的中心地の緯度経度の2つのベクトルを1つのリストにまとめたデータ。ベクトル同士の長さが同じなんだし、データフレームにしてもいいんじゃないかという気持ちになる
- ability.cov
- 行列と、長さ6の数値ベクトルと、長さ1の数値ベクトルを1つのリストにまとめたデータ。これだよ。こういうのが典型的なリストだよ。
factanal()してる
- 行列と、長さ6の数値ベクトルと、長さ1の数値ベクトルを1つのリストにまとめたデータ。これだよ。こういうのが典型的なリストだよ。
- Harman23.cor
- 心理学研究のデータ。
factanal()してる
- 心理学研究のデータ。
- Harman74.cor
- 心理学研究のデータ。
factanal()してる
- 心理学研究のデータ。
2-2. 時系列 (ts) データ
29件あります。ts型は表形式で表示されることもありますが、内部的には1列のベクトルなので、基本的には次元がありません。
例外として、Seatbeltsは次元があります。これはmts型を同時に持っているからです。
- 季節性のないデータ 13件
- 季節性のあるデータ 16件
季節性のないデータ
| item | class | dim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| uspop | ts | 0 | 19 | 1 | 0.57 | Populations Recorded by the US Census |
| airmiles | ts | 0 | 24 | 1 | 0.61 | Passenger Miles on Commercial US Airlines, 1937-1960 |
| lh | ts | 0 | 48 | 1 | 0.80 | Luteinizing Hormone in Blood Samples |
| nhtemp | ts | 0 | 60 | 1 | 0.89 | Average Yearly Temperatures in New Haven |
| Nile | ts | 0 | 100 | 1 | 1.20 | Flow of the River Nile |
| WWWusage | ts | 0 | 100 | 1 | 1.20 | Internet Usage per Minute |
| discoveries | ts | 0 | 100 | 1 | 1.20 | Yearly Numbers of Important Discoveries |
| LakeHuron | ts | 0 | 98 | 1 | 1.19 | Level of Lake Huron 1875-1972 |
| lynx | ts | 0 | 114 | 1 | 1.31 | Annual Canadian Lynx trappings 1821-1934 |
| BJsales | ts | 0 | 150 | 1 | 1.59 | Sales Data with Leading Indicator |
| BJsales.lead | ts | 0 | 150 | 1 | 1.59 | Sales Data with Leading Indicator |
| sunspot.year | ts | 0 | 289 | 1 | 2.68 | Yearly Sunspot Data, 1700-1988 |
| treering | ts | 0 | 7980 | 1 | 62.77 | Yearly Treering Data, -6000-1979 |
- uspop
- 1790〜1970年の10年ごとのアメリカの国勢調査人口。10年ごとの場合
frequency()の返り値は0.1になります。
- 1790〜1970年の10年ごとのアメリカの国勢調査人口。10年ごとの場合
- airmiles
- 1937〜1960年のアメリカ航空会社の旅客マイル
- lh
- 10分ごとの血液サンプル中の黄体ホルモン量
- nhtemp
- 1912〜1971年の,コネチカット州ニューヘブン(New haven)の年平均気温。どうでもいいけど
nottemとデータセットの命名規則揃えてほしい。
- 1912〜1971年の,コネチカット州ニューヘブン(New haven)の年平均気温。どうでもいいけど
- LakeHuron
- 1875〜1972年のヒューロン湖の水位
- Nile
- 1871〜1970年のアスワンにおけるナイル川の年間流量
- WWWusage
- 1分あたりのインターネット利用者数
- discoveries
- 1860〜1959年の年間の「偉大な」発明と科学的発見の数
- lynx
- 1821〜1934年に罠に掛かったカナダ・オオヤマネコの数
- BJsales
- 売上高データ。http://robjhyndman.com/TSDL/ のデータ
- BJsales.lead
- 売上の先行指標データ。BJsalesとからめて相互相関とか出してみたい。
- sunspot.year
- 年ごとの黒点データ。
- treering
- 年輪データ。http://data.is/TSDLdemo を見に行くと年輪データだけで35種類くらいあって驚愕。メトシェラと呼ばれる木が存在する一帯をMethuselah Walkと呼ぶそうなのですが、そのあたりで取られたサンプルのようです。
季節性のあるデータ
frequency = 7 とか frequency = 365 のデータは基本データセットには含まれていません。
| item | class | dim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| freeny.y | ts | 0 | 39 | 1 | 0.73 | Freeny's Revenue Data |
| USAccDeaths | ts | 0 | 72 | 1 | 0.98 | Accidental Deaths in the US 1973-1978 |
| fdeaths | ts | 0 | 72 | 1 | 0.98 | Monthly Deaths from Lung Diseases in the UK |
| ldeaths | ts | 0 | 72 | 1 | 0.98 | Monthly Deaths from Lung Diseases in the UK |
| mdeaths | ts | 0 | 72 | 1 | 0.98 | Monthly Deaths from Lung Diseases in the UK |
| JohnsonJohnson | ts | 0 | 84 | 1 | 1.08 | Quarterly Earnings per Johnson & Johnson Share |
| austres | ts | 0 | 89 | 1 | 1.12 | Quarterly Time Series of the Number of Australian Residents |
| UKgas | ts | 0 | 108 | 1 | 1.27 | UK Quarterly Gas Consumption |
| presidents | ts | 0 | 120 | 1 | 1.36 | Quarterly Approval Ratings of US Presidents |
| AirPassengers | ts | 0 | 144 | 1 | 1.55 | Monthly Airline Passenger Numbers 1949-1960 |
| UKDriverDeaths | ts | 0 | 192 | 1 | 1.92 | Road Casualties in Great Britain 1969-84 |
| nottem | ts | 0 | 240 | 1 | 2.30 | Average Monthly Temperatures at Nottingham, 1920-1939 |
| co2 | ts | 0 | 468 | 1 | 4.08 | Mauna Loa Atmospheric CO2 Concentration |
| sunspots | ts | 0 | 2820 | 1 | 22.45 | Monthly Sunspot Numbers, 1749-1983 |
| sunspot.month | ts | 0 | 3177 | 1 | 25.24 | Monthly Sunspot Data, from 1749 to "Present" |
| Seatbelts | ts | 2 | 192 | 8 | 13.30 | Road Casualties in Great Britain 1969-84 |
- freeny.y
- freenyのデータの目的変数だけを取り出したやつ。
- USAccDeaths
- アメリカにおける1973〜1978年の不慮の事故死者数
- fdeaths
- femaleの死亡数。6年間の12ヶ月分ある。
- mdeaths
- maleの死亡数。
- ldeaths
- 両方あわせたやつ。
- JohnsonJohnson
- 4半期ごと。1960〜1980年におけるジョンソン&ジョンソンのシェアあたりの四半期収益。シェア当たりっていう割り算をしているのが非常に気になるんだけどいいんですかこれ。
- austres
- 4半期ごと。 1971年3月〜1994年3月のオーストラリア居住者数
- UKgas
- 4半期ごと。 1960〜1986年の英国のガス消費量
- presidents
- 4半期ごと。1945年第1四半期〜1974年第4四半期までの,アメリカ大統領の四半期ごとの支持率。欠損値があるところがかわいい。
- Airpassengers
- 1949〜1960年の月別国際航空旅客数
- UKDriverDeaths
- 1969〜1984年の月別自動車運転者の死亡数。1983/1/31にシートベルトの着用が義務付けられた。
SeatbeltsデータセットのDriverKillesと同じ。
- 1969〜1984年の月別自動車運転者の死亡数。1983/1/31にシートベルトの着用が義務付けられた。
- nottem
- イギリスのNottingham Castleという町で記録された、1920年から1939年にわたる20年分の月次平均気温(Temperatures)の時系列データ。異常値検知に使えます
- co2
- ハワイのマウナロア山 山頂での大気中のCO2濃度観測データ
- sunspots
- 1749 to 1983.黒点
- sunspot.month
- 上と違うのは、データがアップデートされるらしい点。現在2013年のデータまで入ってる。Box-Cox変換すると使いやすくなる「バースト性を持つデータ」の例としてとりあげられています。
- Seatbelts
- 英国における1969〜1984年の自動車運転者の死傷者数。期間中の1983年1月31日にシートベルトの着用が義務づけられたそうです。
2-3. その他
10件あります。
内訳は、
- character 2件
- factor 2件
- numeric 6件
です。メタデータを外に出している場合にここに含まれます。
| item | class | dim | nrow | ncol | size | title |
|---|---|---|---|---|---|---|
| state.abb | character | 0 | 50 | 1 | 2.77 | US State Facts and Figures |
| state.name | character | 0 | 50 | 1 | 3.02 | US State Facts and Figures |
| state.region | factor | 0 | 50 | 1 | 0.82 | US State Facts and Figures |
| state.division | factor | 0 | 50 | 1 | 1.26 | US State Facts and Figures |
| stack.loss | numeric | 0 | 21 | 1 | 0.20 | Brownlee's Stack Loss Plant Data |
| state.area | numeric | 0 | 50 | 1 | 0.43 | US State Facts and Figures |
| euro | numeric | 0 | 11 | 1 | 0.95 | Conversion Rates of Euro Currencies |
| rivers | numeric | 0 | 141 | 1 | 1.14 | Lengths of Major North American Rivers |
| islands | numeric | 0 | 48 | 1 | 3.41 | Areas of the World's Major Landmasses |
| precip | numeric | 0 | 70 | 1 | 4.88 | Annual Precipitation in US Cities |
| UScitiesD | dist | 0 | 45 | 1 | 2.20 | Distances Between European Cities and Between US Cities |
| eurodist | dist | 0 | 210 | 1 | 3.40 | Distances Between European Cities and Between US Cities |
- state.abb
- アメリカ50州の短縮名
- state.name
- アメリカ50州の名前
- state.region
- アメリカ50州を大きく北東部、南部、中西部、西部の4つに分けた区分。1984以前は中西部(現 Mid West)のことをNorth Centralって言ったけどそれをそのまま使ってます。このregionを群にして、
state.x77のデータを集計するような例を紹介する時にべんり。
- アメリカ50州を大きく北東部、南部、中西部、西部の4つに分けた区分。1984以前は中西部(現 Mid West)のことをNorth Centralって言ったけどそれをそのまま使ってます。このregionを群にして、
- state.division
- アメリカ50州を国勢調査で使ってる9つのdivisionにつけたラベル。
- state.area
- アメリカの各州の面積
- stack.loss
- stacklossデータの目的変数
- euro
- 旧ヨーロッパ通貨の、1ユーロとの交換比率
- rivers
- 北アメリカの141の主要な川の長さ(単位:マイル)
- islands
- 大陸を含まない世界の主要な48の「島」の面積データセット。
- precip
- アメリカの都市とプエルト・リコにおける年間降水量(precipitate)。棒グラフは必ず0から書かないと誤解を招くのですが、州や都道府県のような名義尺度は棒グラフではなく、"Clevelandのドットプロット"と呼ばれる手法による可視化が便利です。
- グラフの例:都道府県別人口(ドットプロット) | Haruhiko Okumura
なお、LETTERS, letters, month.abb, month.name, piなどはヘルプを見ると"constants"と書かれていて別扱いのようで、datasetsパッケージには含まれていませんでした。
距離行列
下三角行列とよばれたりするものですがここに混ぜました。is.matrix(FALSE)なのでデータ構造的にはmatrixではありません。
- UScitiesD
- アメリカの10都市間の距離を格納した行列
- eurodist
- ヨーロッパの21都市間の距離を格納した行列。計量的な多次元尺度法(MDS)の関数
cmdscale()で使われてます。
- ヨーロッパの21都市間の距離を格納した行列。計量的な多次元尺度法(MDS)の関数
おわりに
繰り返しになりますが、
「他にもデータセットまとめた有用な記事あるよ!」とか「このデータセットはこんなに面白いのにぜんぜん書かれていない!」みたいなご指摘、心の底からお待ちしています。
君の推しデータセットを教えてくれ。
...Enjoy!
参考文献
- 細かすぎて使わない R 小技集 - Qiita
- そもそもRってなに、って方へ
- 質的/量的データとか尺度の話
- 可視化
- 他言語からの利用
- Pythonからの利用についてはこちら
- Juliaからの利用についてはこち
この記事を書くのに使ったRのコード
なんかもうちょっとうまい書き方がありそうなので誰か教えてください
library(dplyr)
library(knitr)
pkg_matome <- function(pkgName){
raw_data_sets <- data(package=pkgName)$results
titles <- raw_data_sets[,"Title"]
items <- gsub(
pattern = " \\(.*\\)$",
replacement = "",
x = raw_data_sets[,"Item"]
)
classes <- lapply(
items,
FUN = function(x) paste0(class(eval(parse(text = x))), collapse=", ")
) %>%
unlist(use.names = FALSE)
class <- lapply(
items,
FUN = function(x) tail(class(eval(parse(text = x))), n = 1)
) %>%
unlist(use.names = FALSE)
dims <- lapply(
items,
FUN = function(x) length(dim(eval(parse(text = x))))
) %>%
unlist(use.names = FALSE)
lengths <- lapply(
items,
FUN = function(x) length(eval(parse(text = x)))
) %>%
unlist(use.names = FALSE)
ncols <- lapply(
items,
FUN = function(x) NCOL(eval(parse(text = x)))
) %>%
unlist(use.names = FALSE)
nrows <- lapply(
items,
FUN = function(x) NROW(eval(parse(text = x)))
) %>%
unlist(use.names = FALSE)
sizes <- lapply(
items,
FUN = function(x) as.numeric(object.size(eval(parse(text = x))))
) %>%
unlist(use.names = FALSE) / 1024
data_sets <- data.frame(
item = I(items),
class = class,
ndim = dims,
nrow= nrows,
ncol = ncols,
size = round(sizes, digits=2),
title = I(titles)
) %>%
dplyr::arrange(class,ncol,size)
return(data_sets)
}
res <- pkg_matome("datasets")
res %>%
dplyr::group_by(class) %>%
dplyr::summarise(count=n()) %>%
dplyr::mutate(percent=round(count/sum(count)*100,digits=2)) %>%
knitr::kable()
knitr::kable(res)
markdownでの表が出力できるのほんとべんり。