Zoomdata社は2012年に米国のバージニア州で創業し、ビックデータの可視化・解析に関する、先進的なソリューションを提供している企業であり、その製品であるZoomdataを導入することにより、クラウド環境とオンプレミス環境を透過的に活用可能な、ハイブリッドクラウド対応のビジュアル・アナリティクスを実現する事が出来る様になります。
現在(2017年8月時点)は、試用環境としてクラウド上での期間限定版と、オンプレミス環境上に構築可能な、期間限定のソフトウエアダウンロード版が提供されていて、それぞれの特性を活かした評価戦略によって使い分ける事が可能です。最初からある程度の規模でビッグデータ環境を構築し、その上でPoC等を行うのであれば、クラウド版の試用登録を行って提供元の規約や指示に従い、具体的な環境構築や動作検証・性能評価等を進めて頂けば良いでしょう。
今回の企画では、とりあえずZoomdataって何者?という部分や、何が出来るのか?の感触を掴みたい!といった、「始めの一歩」的な内容として取り纏める方向とさせて頂き、次のステップである、「じゃあ、Zoomdataを使うと・・・」という段階を目指せる様にしたいと思います。
(1)最初に
まず最初に、Zoomdataをインストールする環境をサクッと作ってしまいます。
この部分については、色々な主義・主張・流儀・流派が存在しますので、とりあえずの参考という程度でお読み頂き、最終的にはZoomdataが稼働できる環境要素が連携できる事を目指したいと思います。山登りのルートは、それぞれのスキルや個性によって色々あると思いますが、最終的に必要な作業を終了して安全に山頂(ゴール)到達出来ればOKです。
試用登録のURLリンクは下記より入る事ができます。(2017年8月現在)
本来であれば、Zoomdata社のトップページからいろいろな情報を”つまみ読み”しながら、試用登録のページに到達して頂ければ良いのですが、冒頭に”サクッと”と宣言してしまいましたので、取り急ぎ先を急ぎましょう・・・(汗)
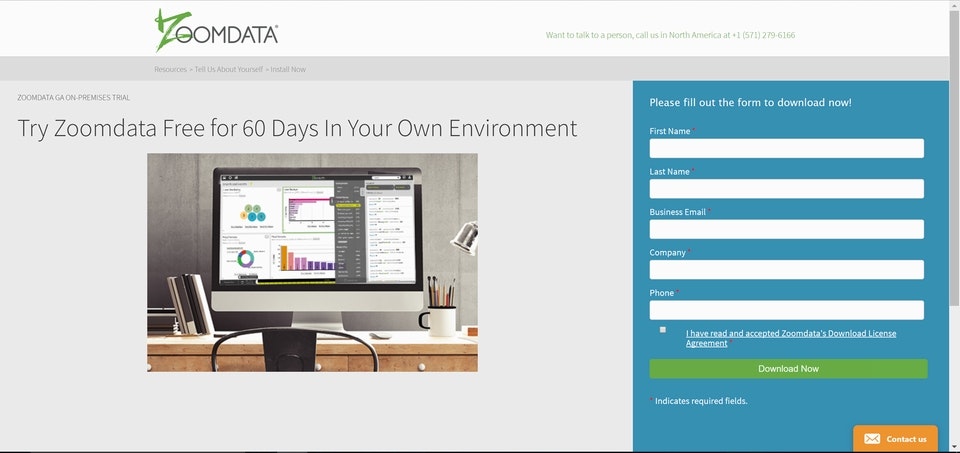
画面右側の各項目を埋めて頂き、
(a)名前
(b)苗字
(c)ビジネス用の電子メールアドレス
このアドレス宛に、最終的なインストールの手順が送られてきます。
(d)会社名
(e)連絡先の電話番号
米国から直接の電話は来ないと思いますが、最近日本支社が設立されましたので、今後は色々な情報提供が国内で始まるかもしれません。
最後にチェックを忘れずに入れて、緑のボタンを押せば終了です。
しばらくすると、登録されたメールアドレス宛にインストールの情報が配信されてくると思いますので、削除しないでキープしておいてください。
(2)試用環境について
インストールに必要な環境に関する情報は、先ほどのメールにURLが埋め込まれていますので、そのメール経由でも確認する事が出来ますが、事前に環境準備を進める話ですので、取り急ぎ下記にリンクを置いておきます。
さて、今回の作業に使うOSですが・・・・・・
特に拘りは有りませんが、とりあえずCentOS 7で行ってみる事にします。設定的にはメモリの大きさがZoomdataの胆なので、出来るだけ大きく確保したいのですが、最低でも8GB程度キープするようにしてください。また、ディスクの容量は40GBとしてスタートする事にします。
それと、重要なポイントなのですが、今回の作業は”とりあえず試す”という点を重視しますので、デスクトップの仮想環境を活用します。
今回は、VMware Workstation 12 Playerを使いますが、Oracle VM VirtualBoxでも基本的には同じ作業になりますので、使い慣れた方を選択されれば良いでしょう。
ちなみに今回の検証に使うハードウエアは、D社製ノートのCore i7でメモリ32GBをWindowsで、というハイパーな環境(表の仕事の関係上ですが)を投入します。コア数は多いほど良いのですが、1ユーザで機能チェックという感じあれば、2コア程度を割り振れるハードウエアであれば、何とか対応できると思います。ただし、メモリは確実に多い方が良いので、1ユーザ試用という状況でも8GBは使えるようにした方が良いかと。また、性能の評価をしてみたい!という状況であれば、Zoomdata社が推奨している構成でのトライをお勧めします。
CentOS 7をダウンロードしてきて、仮想環境にインストールする方法は、メモリの設定とストレージ容量を変更する程度で問題ありません。また、CPU数については、元々のCPU仕様に依存する場所でもあるので、確定的な設定が難しい部分なのですが、可能であれば2個以上を設定するようにしてください。他の項目は普通に入れて頂ければ良いので特に説明を省略します。
それと今回は後々便利なので、GUI付きのサーバ構成でインストールする事にします。この辺は自由に選択出来る部分なので、それぞれのケースに合わせて選択されれば良いと思います。
(3)Javaの導入
今回のインストール設定では、初期設定としてOpenJDKが先行導入されていると思いますので、その状況を確認する場合は、以下のコマンドを使います。(コマンドに対する出力は、選択されたバージョン等により異なるかもしれません)
$ java -version
openjdk version "1.8.0_141"
OpenJDK Runtime Environment (build 1.8.0_141-b16)
OpenJDK 64-Bit Server VM (build 25.141-b16, mixed mode)
バージョン的にはサポート範囲に入っているのですが、alternativesコマンドでjava VMを簡単に変更できますので、今回はOracle Java8に変更して構築してみます。
ブラウザーでOracle社のJavaダウンロードに関するページをアクセスし、jdk-8u144-linux-x64.rpm(執筆時点)を入手します。Acceptにチェックをいれてからターゲットをクリックすれば良いでしょう(コマンドラインでも取れると思いますが、GUI付きでインストールしてますので、ブラウザ経由でサクッと進めていきます)
ダウンロードは、標準でホームのダウンロード・フォルダーに入ってくると思いますので、必要があれば作業用のフォルダーにコピーして、以下のコマンドを発行します。
$ sudo yum localinstall jdk-8u144-linux-x64.rpm
サクッと入りますので、次にalternativesコマンドを使います。
$ sudo alternatives --config java
2つのJavaが表示され、OpenJDKが選択されていると思いますので、今回インストールした方の番号を入力して切り替えます。
切り替わったか、コマンドで確認します。
$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
この部分については、一般的な環境変数で行う選択もありますので、進め方はそれぞれ自由に選択されれば良いでしょう。
(4)Sparkの導入
次にSparkの導入を行います。
今回は、GUI付きのサーバ構成ですので、Javaの時と同様にブラウザを駆使してサクッと行きます。
Download Sparkのボタン経由で所定のページへ移動します。
幾つかのバージョンが存在していますが、前述の構成情報に1.5.1のお勧め記述がありますので、今回はその流れの最終版らしき1.6.3を使ってみようと思います。
項目を選択すると、spark-1.6.3-bin-hadoop2.6.tgzというリンクが出てくると思いま
すので、それをクリックしてローカルにダウンロードします。
$tar -xzvf spark-1.6.3-bin-hadoop2.6.tgz
で展開し、
$ sudo mv spark-1.6.3-bin-hadoop2.6 spark
$ sudo cp -rf spark/ /usr/local/
$ vi .bash_profile
ここでPATHに /usr/local/spark/bin を追加します。
$ source ~/.bash_profile
無事に導入されたか、Sparkを起動してみます。
$ spark-shell
この後にsparkのロゴと一緒に立ち上がってくればOKです。
scala>でexitを入力すれば、通常のコマンドプロンプトに戻ります。
(5)Zoomdataの導入と初期設定
ここまでくれば、Zoomdataのログイン画面と対面できるのも、あと少しの辛抱です。
前述のZoomdata社からのメールに、システムのインストールに関する情報が書かれていますので、その情報を使って最終的な処理を行ってください。無事に全ての処理が終了すると最初のログイン画面を呼び出す作業になります。
Zoomdataの呼び出しは、サポートされているWebブラウザのURLフィールドに
と入力してください。(xxx.xxx.xxx.xxxには、ZoomdataをインストールしたマシンのIPアドレスが入ります。)
署名問題等により、本当に繋ぎますか?という確認がくるかと思いますが、アドレスが間違っていなければそのままプロセスを前に進めてください。接続されると最初のログイン画面が出てきます。

今回は、期間限定の試用になりますので、下部の右側にあるSkip Activationを選択して処理を進めます。

Zoomdataでは、システムとサービスにそれぞれの管理者が存在します。前者はサーバ固有に1アカウントのみ定義されるSupervisorであり、後者はユーザグループ単位で複数定義出来るAdminになります。この画面上でそれぞれにパスワードを設定し、(2回同じ入力が求められます)全ての情報の整合性が無事に揃うとChange Passwordボタンがハイライトされますので、そのボタンを押して導入が終了します。

首尾よく行けば、通常のログイン画面が出てきます。
とりあえず、お疲れ様でした!!
ちなみに初期設定状態で、ファイアーウォールに阻まれてのポート疎通問題が起きると思いますが、事前にGUIツールを使って設定するか、コマンドラインを使って都度設定の追加・変更をするようにしてください。サクッと行く場合は
$ sudo systemctl stop firewalld
で、強制停止を掛けてしまうという方法があります。
(6)最後に
次回以降は、いくつかのパターンを使って、実際にZoomdataを試用してみたいと思います。
Zoomdataの特性を活かすには、時間の推移とデータを連動させて、最終的なデータが確定するまでのプロセスを、事後推測ではなく実際にリアルに発生している状況を高速に可視化分析する事で、新しい戦略や問題解決や競合優位の開発等を、実際に生成・推移している現実(リアル)の中で実施できるという部分に注目する必要があります。
まさに、ビジネスや日々の問題は現場で起きており、その状況は時間軸の上に乗った形で、時々刻々と変化している・・・Zoomdataを活用する事で、その今(リアル)を改革・改善する事が可能となり、未来を能動的・戦略的に変えられる可能性が手に入るかもしれません。もちろん、過去の無い現在は存在しませんが、リアルな今を変えれば確実にリアルな未来は変わる・・・その可能性を秘めたソリューションがZoomdataだと言えるのかもしれません。