過去三回に分けて、Zoomdataの導入と利用についてご紹介させて頂きましたが、今回は番外編としてZoomdataが持つ便利な機能としてのFusionをご紹介させて頂きます。
前回までのご紹介の中で、マイクロクエリーという単語が出てきたかと思いますが、この機能が持つもう一つの側面として、必要なタイミングで、必要なだけ、必要なデータソースを見に行くという特性を活かし、異なるデータソース間に存在する、共通のキーを有するデータの仮想結合(実際に結果として実データを書き換える訳ではありませんので)と、その高速な可視化分析の実現が有ります。
また、この機能を上手く利用する事で、適材適所に散在する異なるビッグデータのデータソース間で、共通のキーを上手く設定し、運用しているデータ(この場合はデーターレイクの規模を越えて・・・データオーシャンとでも呼ばなければいけない規模になるかもしれませんが・・・)を透過的に一つのソースとして取り扱う事が出来る様になり、ビッグデータの運用効率の向上や、そこから新たに創造される付加価値の獲得といった事が可能になります。
(1)準備
今回の実験に使うデータは、IoT系のセンサーデータの出力をイメージした物が手元にありましたので、そのデータを幾つかに分割して使う事にします。(基本的な仕組みの確認ですので、以下の手順を参考にしてテストデータを作成してみてください)
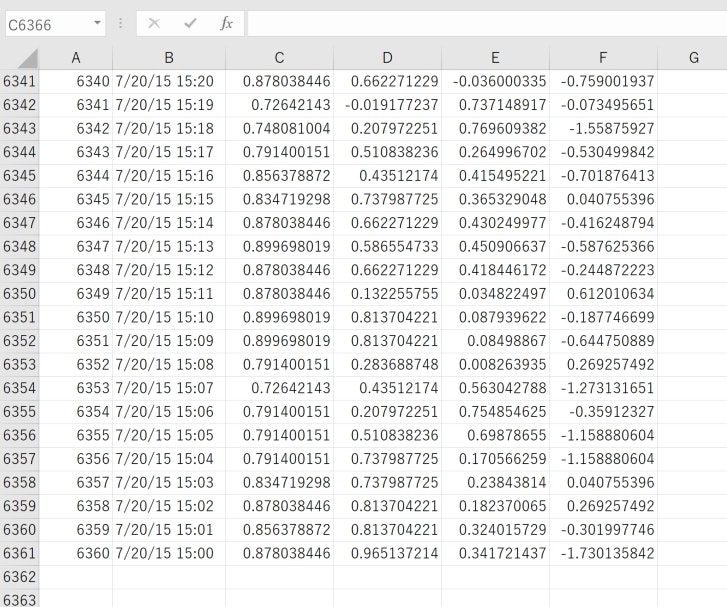
なんちゃってデータ数としては、4個のセンサーからそれぞれ6360個のデータをサンプリングした形になっており、便宜上時系列にシーケンシャルのサンプルIDを付与した形になっています。因みにこのデータをそのまま読み込んで可視化したチャートが
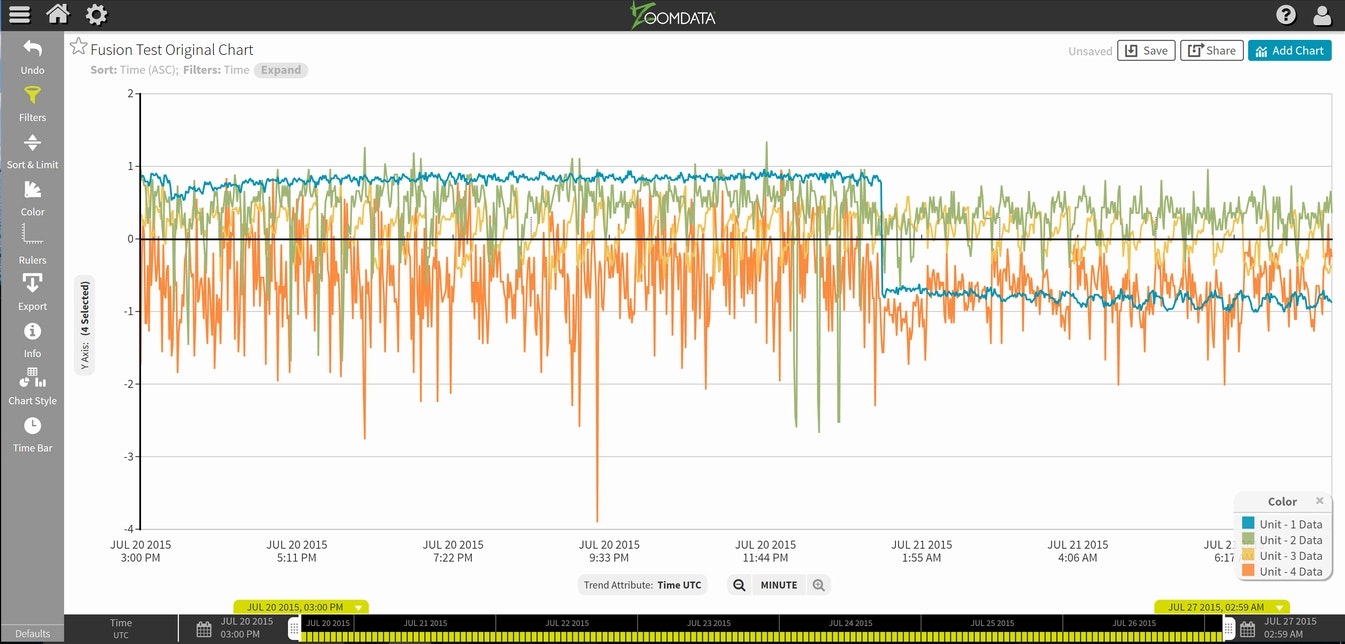
なので、最終的に4個のなんちゃってセンサーデータをFusionして、同じ表示のチャートに纏まればゴールという事になります。
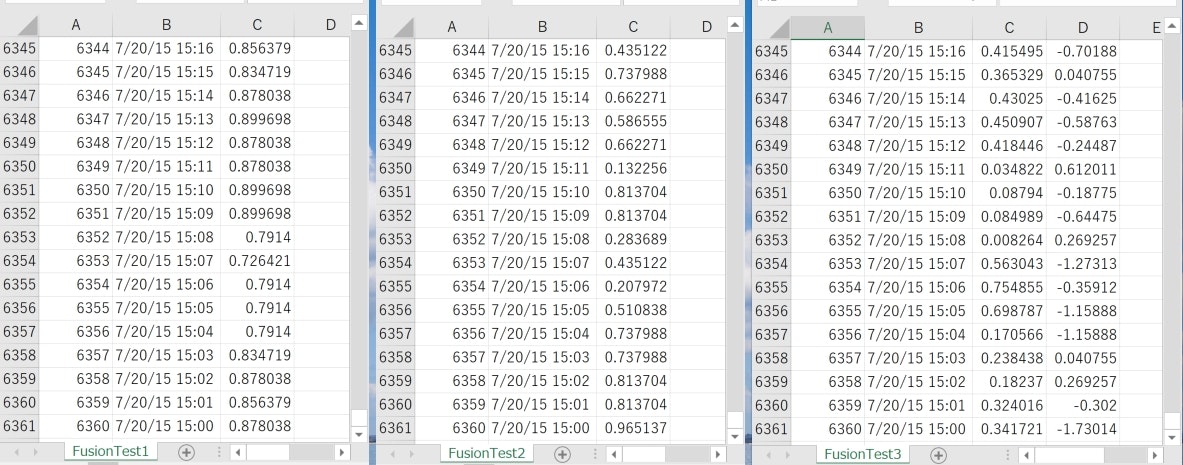
では、まずはデータの分割を行います。今回は、Unit-1,Unit-2,Unit-3&4の3分割としました。
(2)Fusionの設定について
最初にadminでZoomdataに入ってデータソースの設定を行います。(手順等は前回までと同じなので省略)
設定が完了したら、Fusionを選択してください。(Sourceリストの一番左端に有ります)
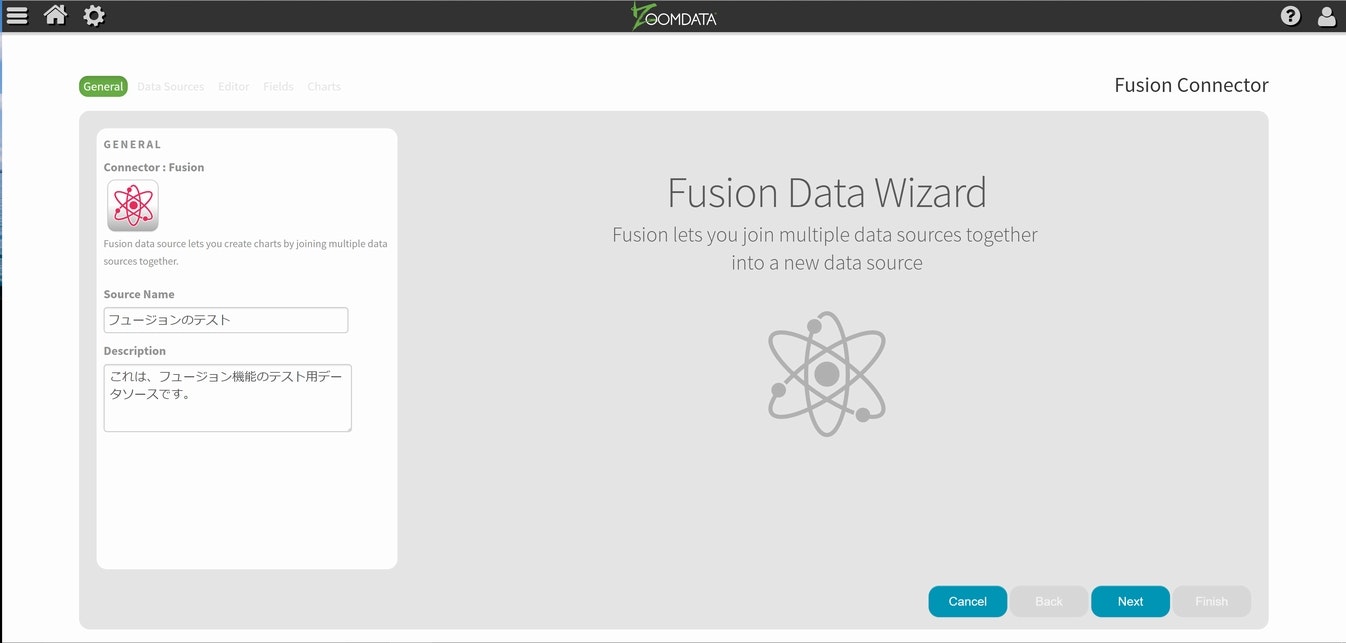
Nextを選択して、Fusion対象のデータを選択します。
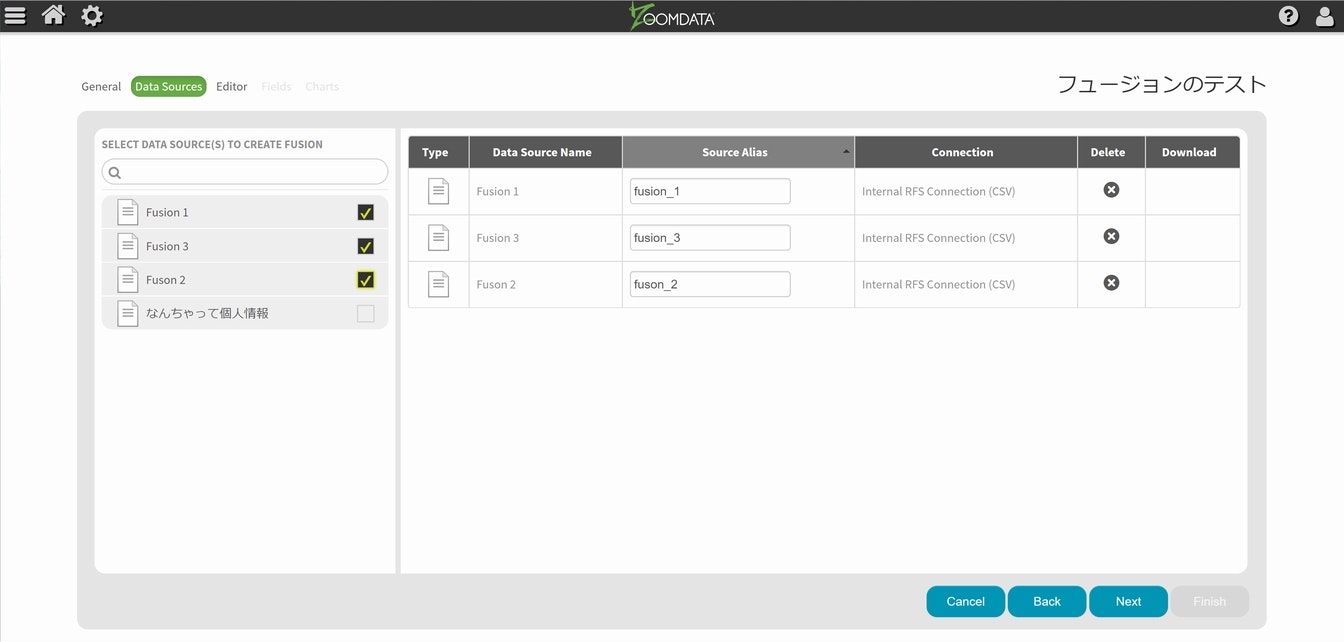
Nextを選択して具体的な設定を開始します。
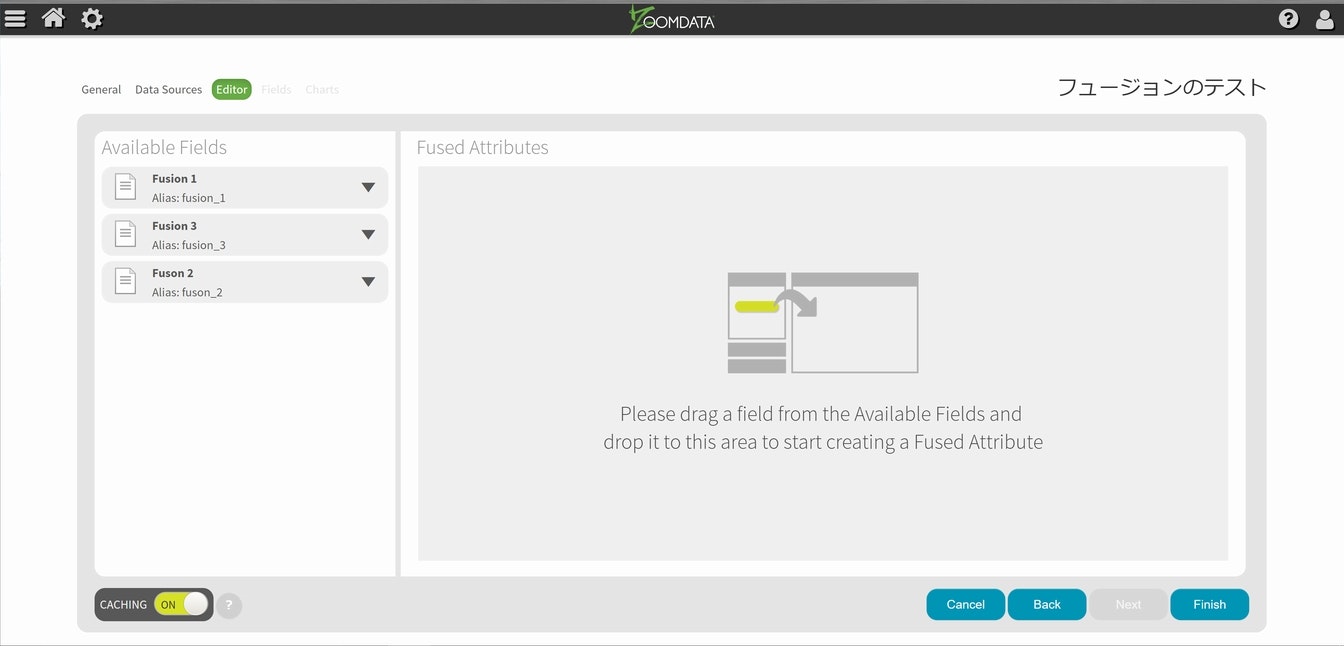
今回はデータIDを共通情報にしますので、それぞれの元データからID属性を取り出してドラッグアンドドロップで登録していきます。
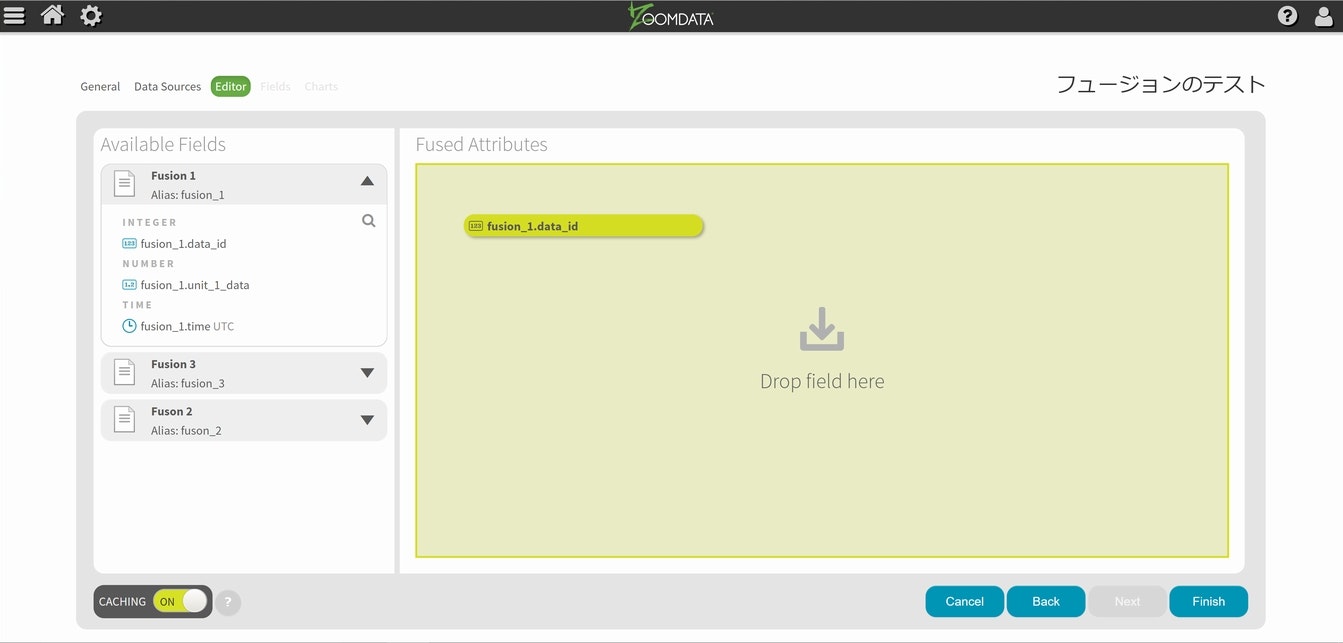
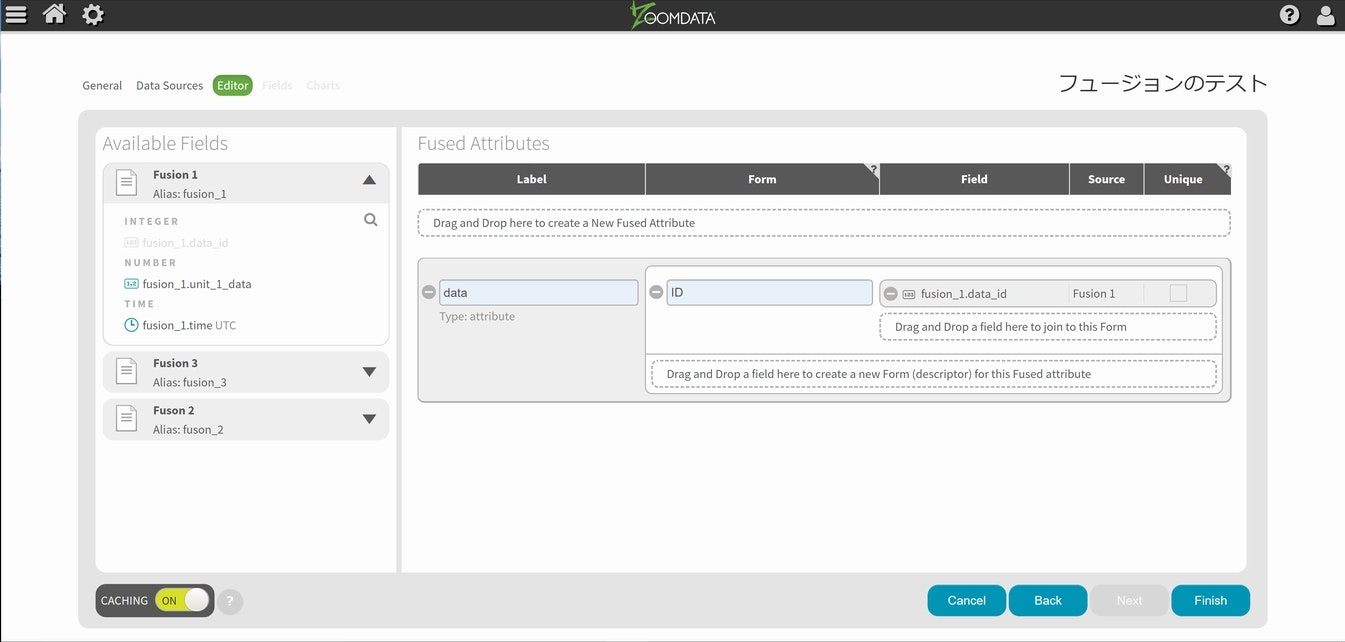
基本構造が自動的に定義されましたので、同様に作業を進めます。
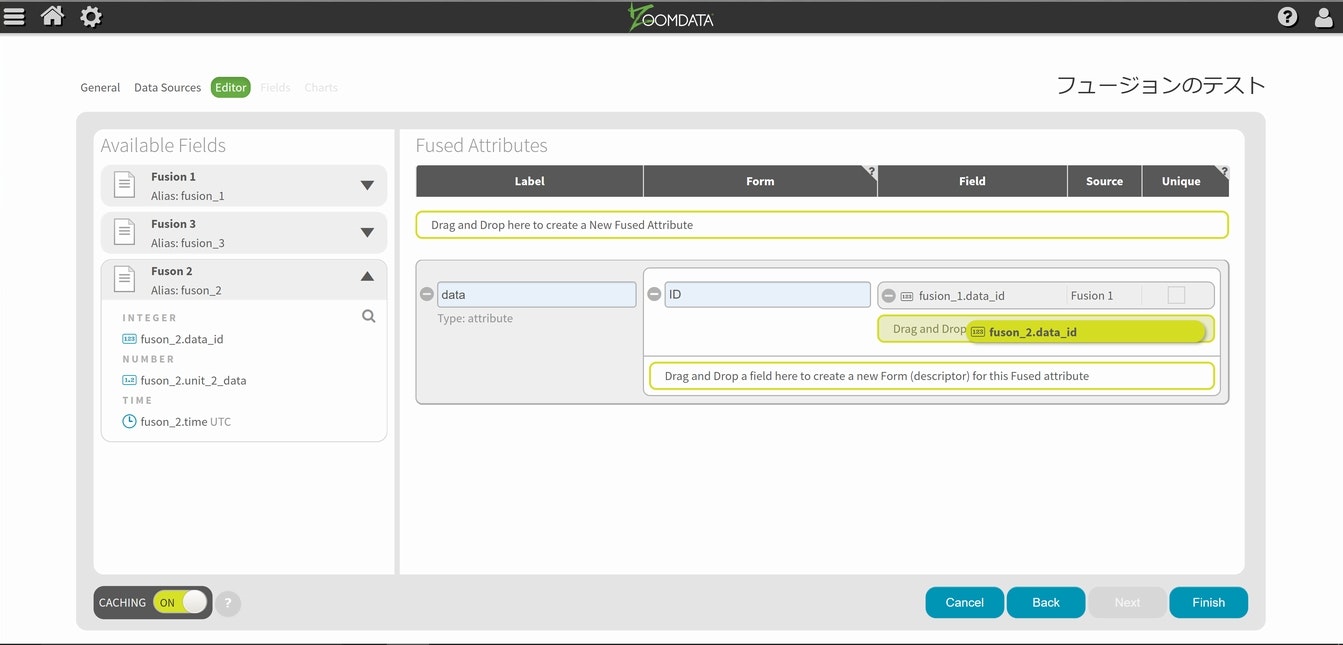
3つのデータソースに対する設定が終わったらNextを選択します。
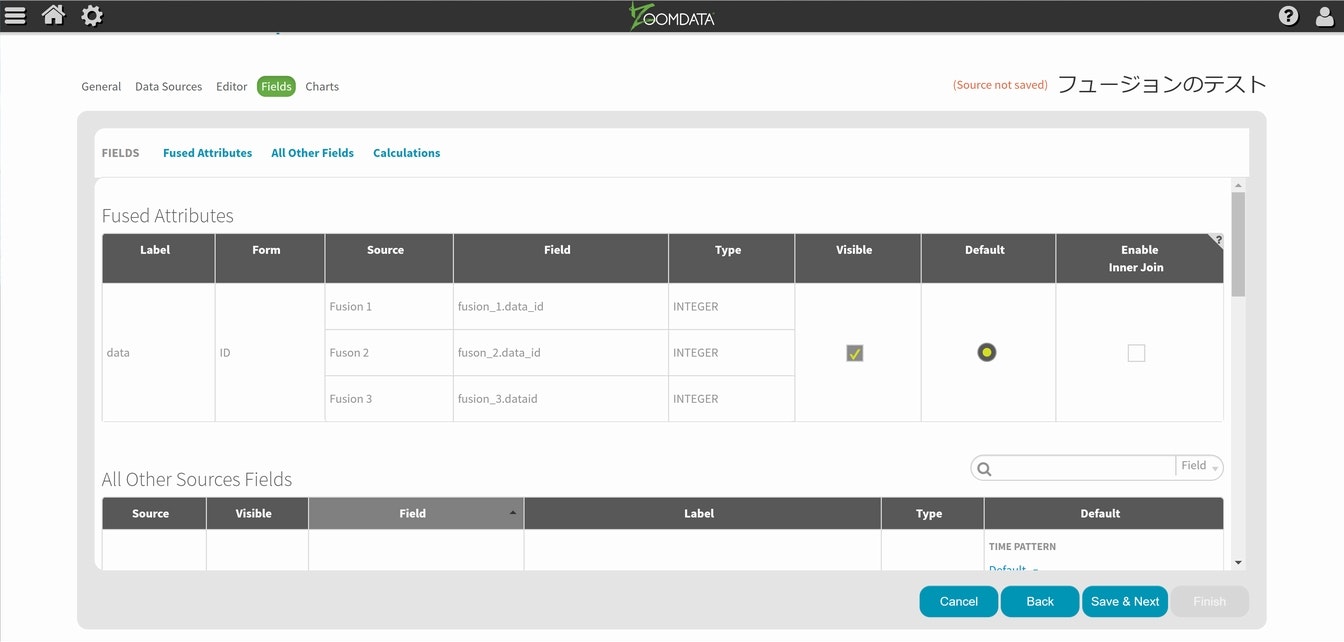
指示に従って生成されたテーブルが表示され、さらに細かい設定が出来るようになりますが、今回はサクッと操作の流れをご紹介する事が目的ですので、そのままSave & Nextを選択します。
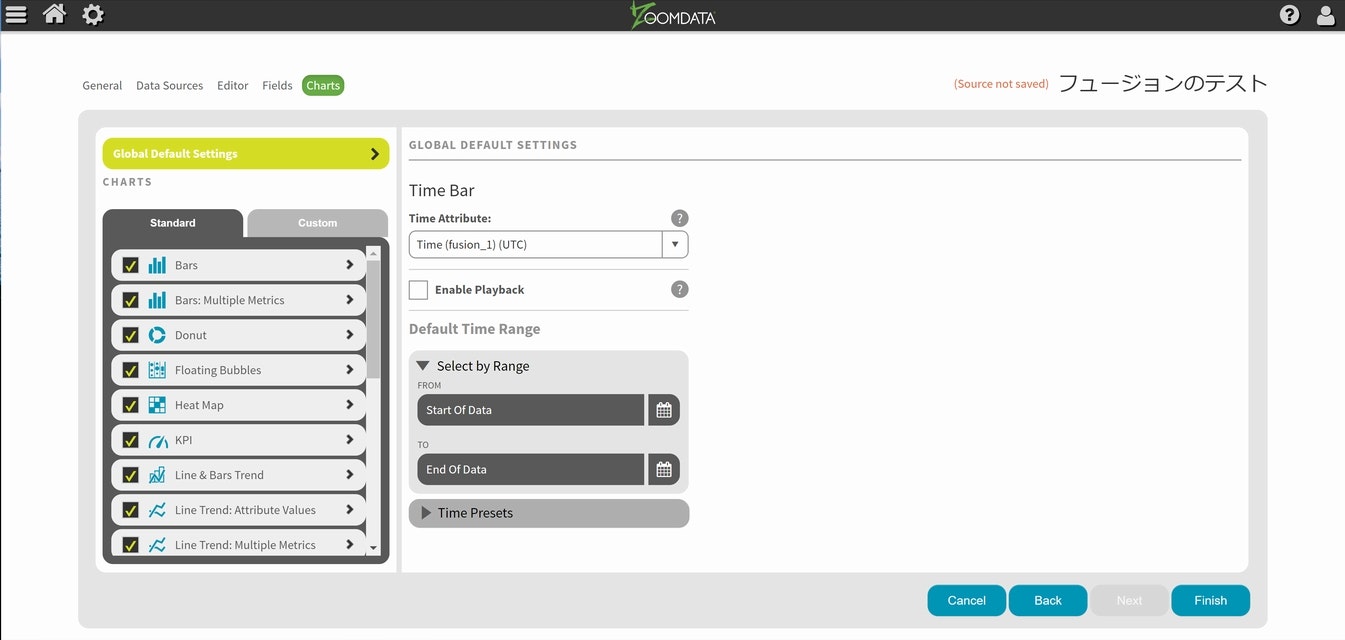
Time Barの設定画面になりますので、今回は便宜上1番目のデータソースの時間データと同期させる設定を行いFinishを選択します。
無事に作業が終了すると、見慣れたデータソースのトップページになります。
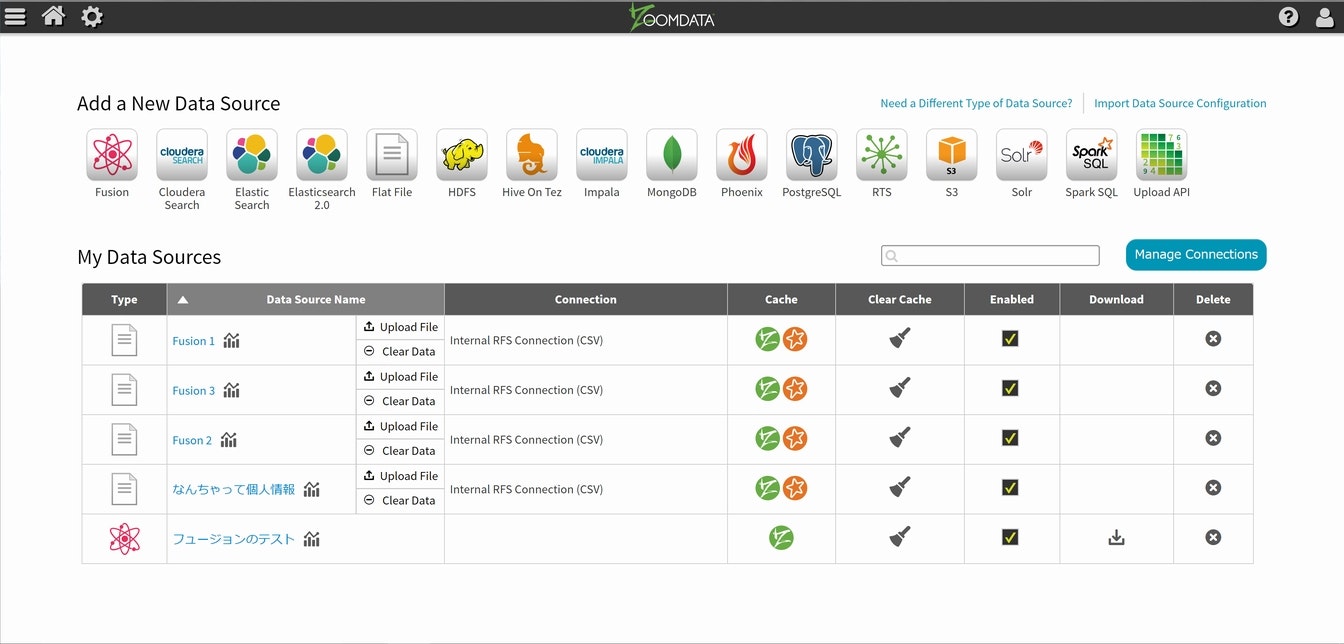
(3)チャートの作成と検証
次に、冒頭の単体でのチャートと同じ出力が得られるかの確認をしてみます。ますは左側上のアイコンで一番左のアイコンを選択し、Data Sourceのリストに先程のFusion Data Sourceが有る事を確認して選択してください。
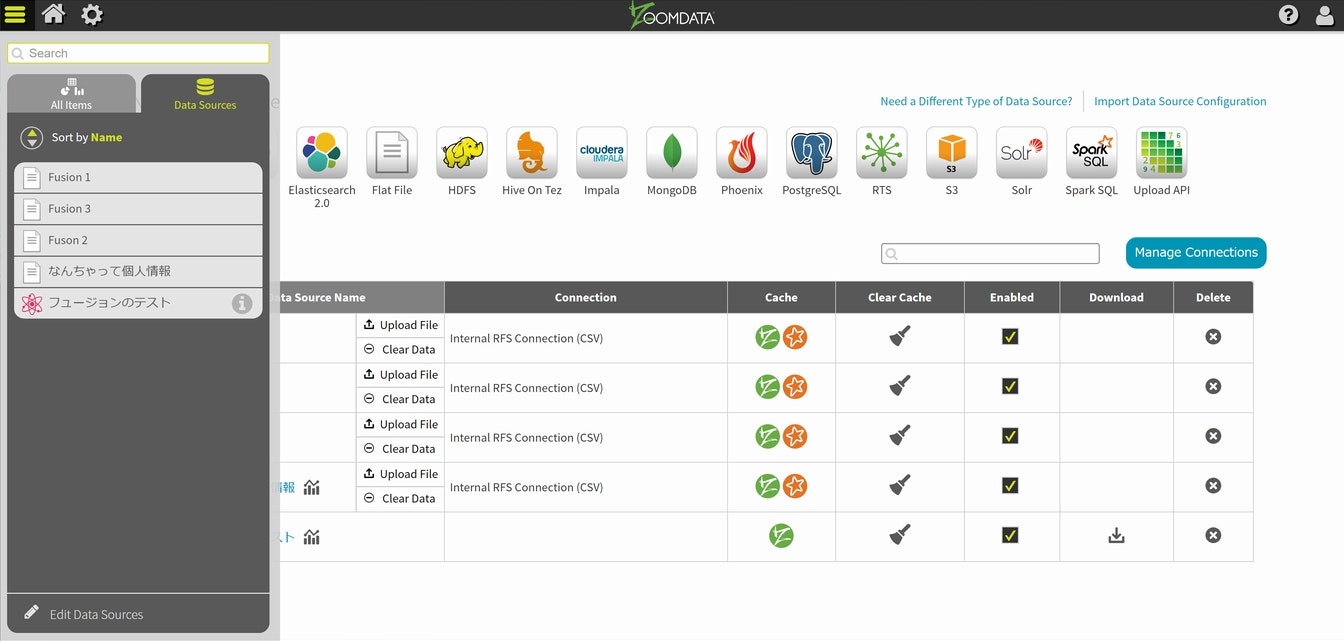
利用可能なチャートが出てきますので、Line Trend:Multiple Metricsを選択します。
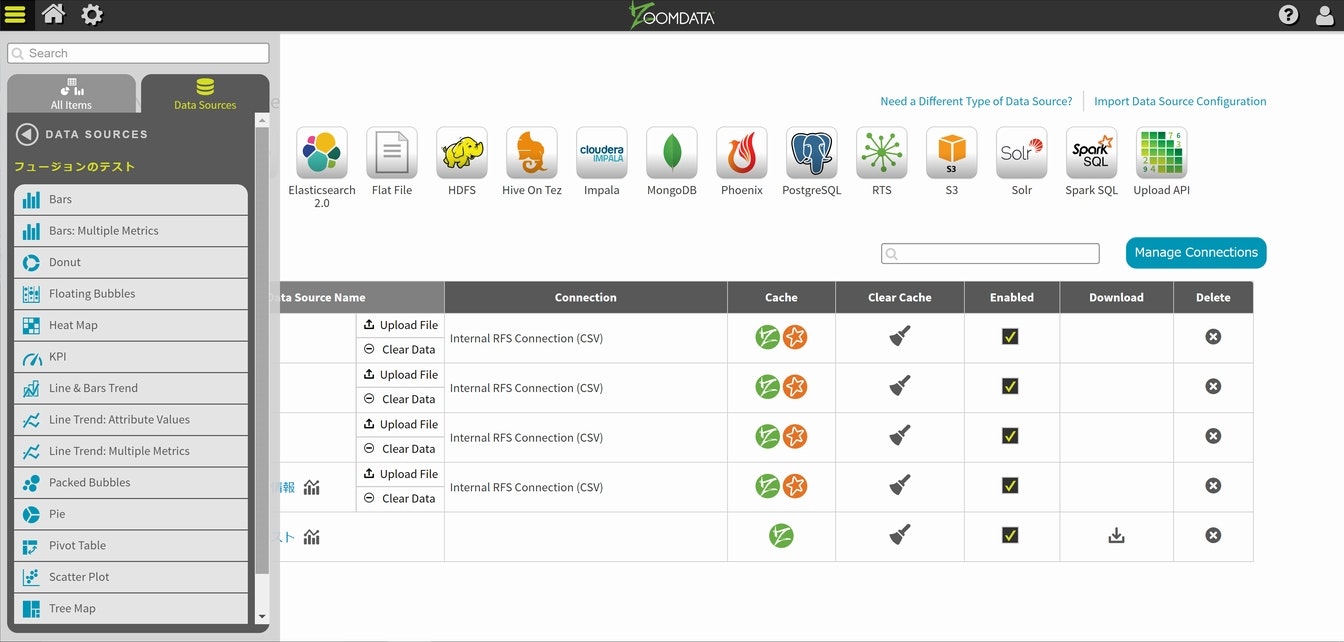
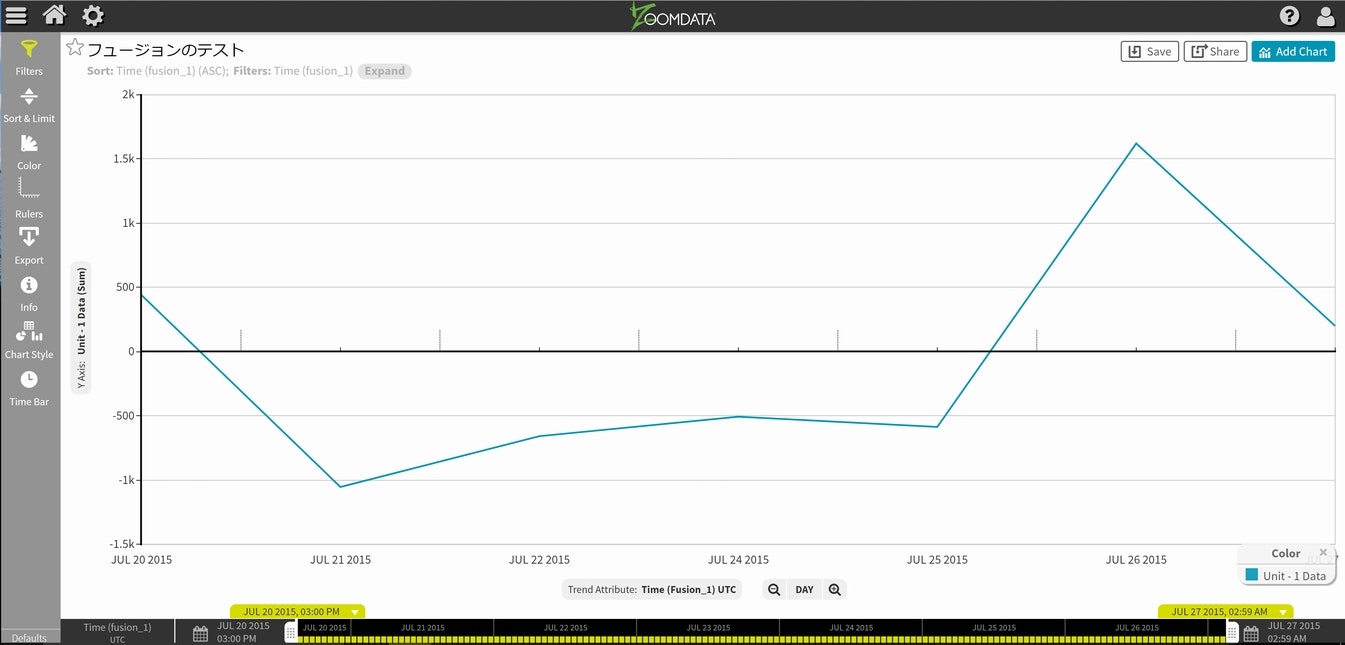
最初のグラフが出てきますので、可視化対象を増やします。
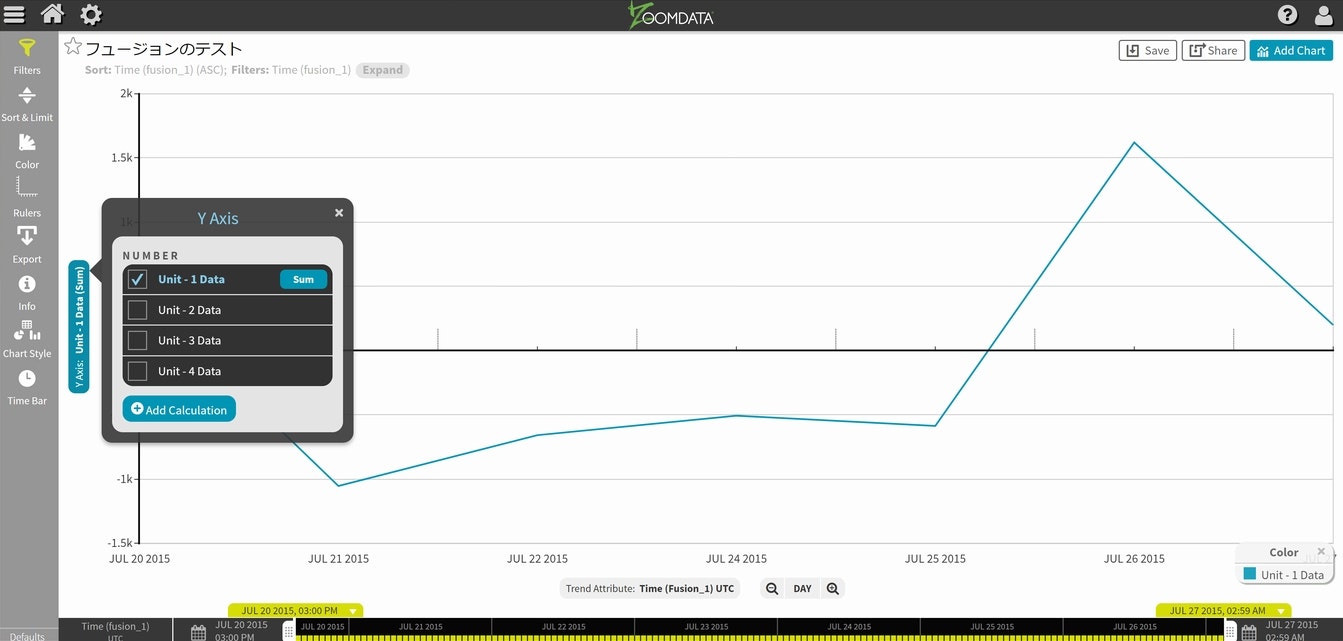
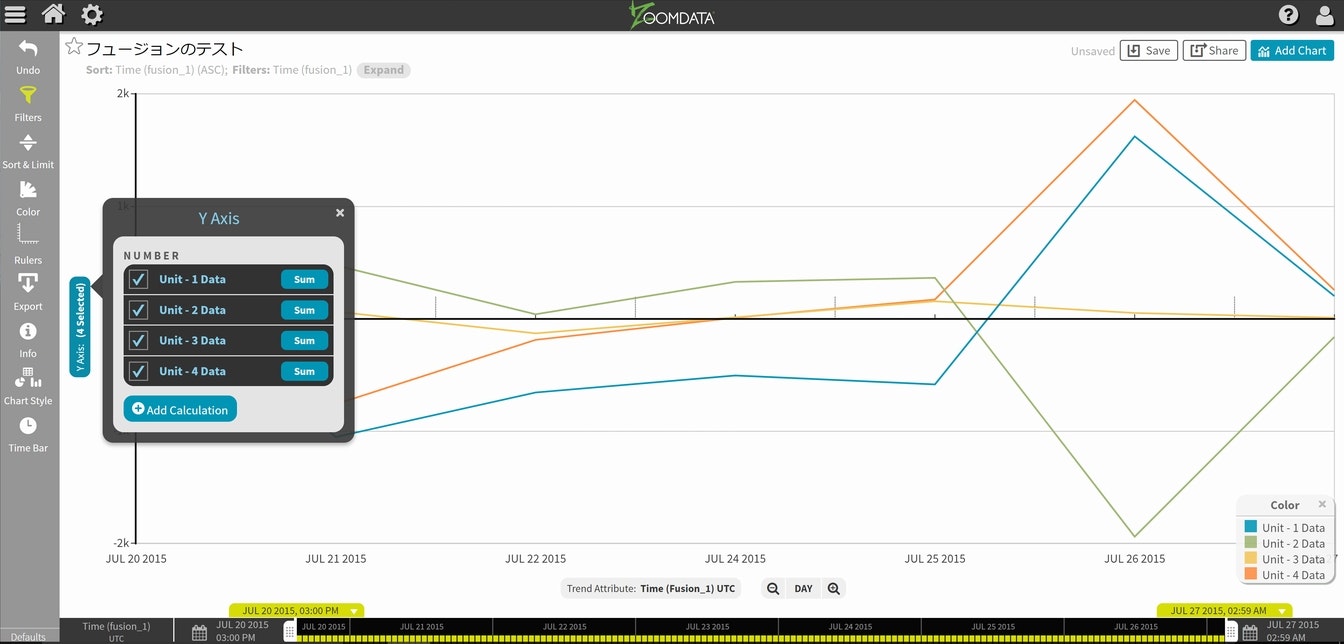
チャート下部にある時間単位をDAYからMINUTEに変更します。
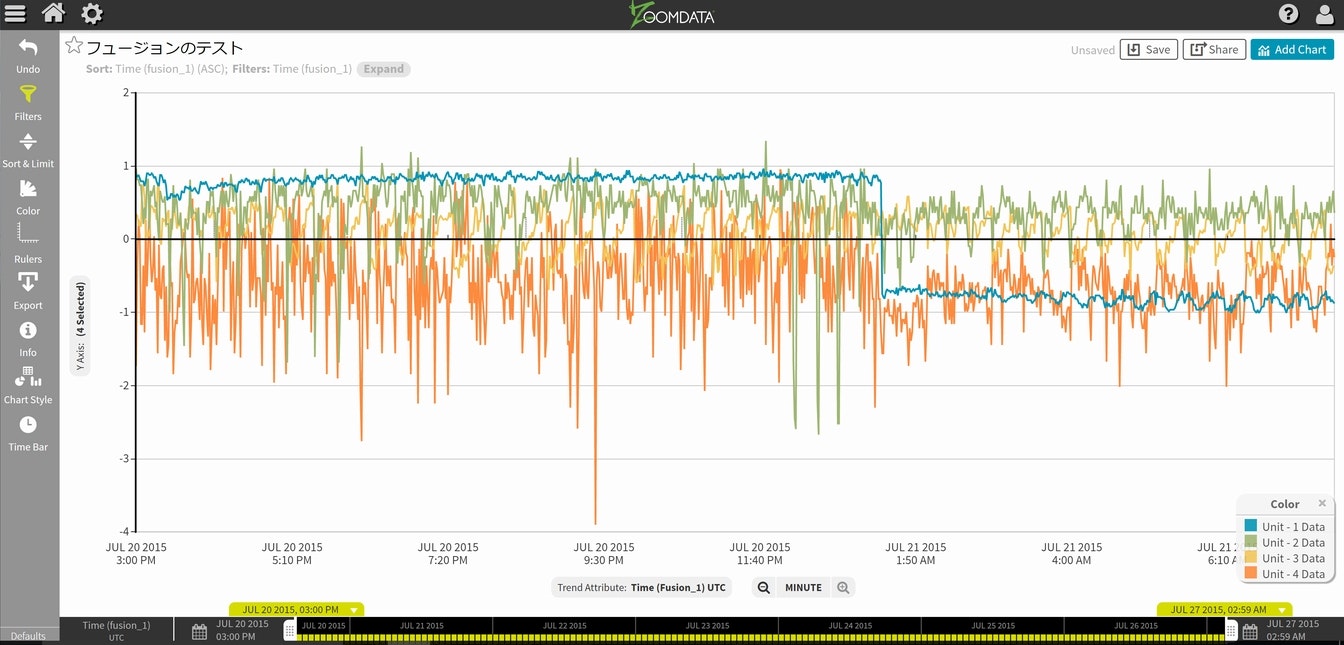
無事に同じ可視化チャートになりました。連携されているかの確認を兼ねて、今度はMINUTEからHOURに変更してみます。
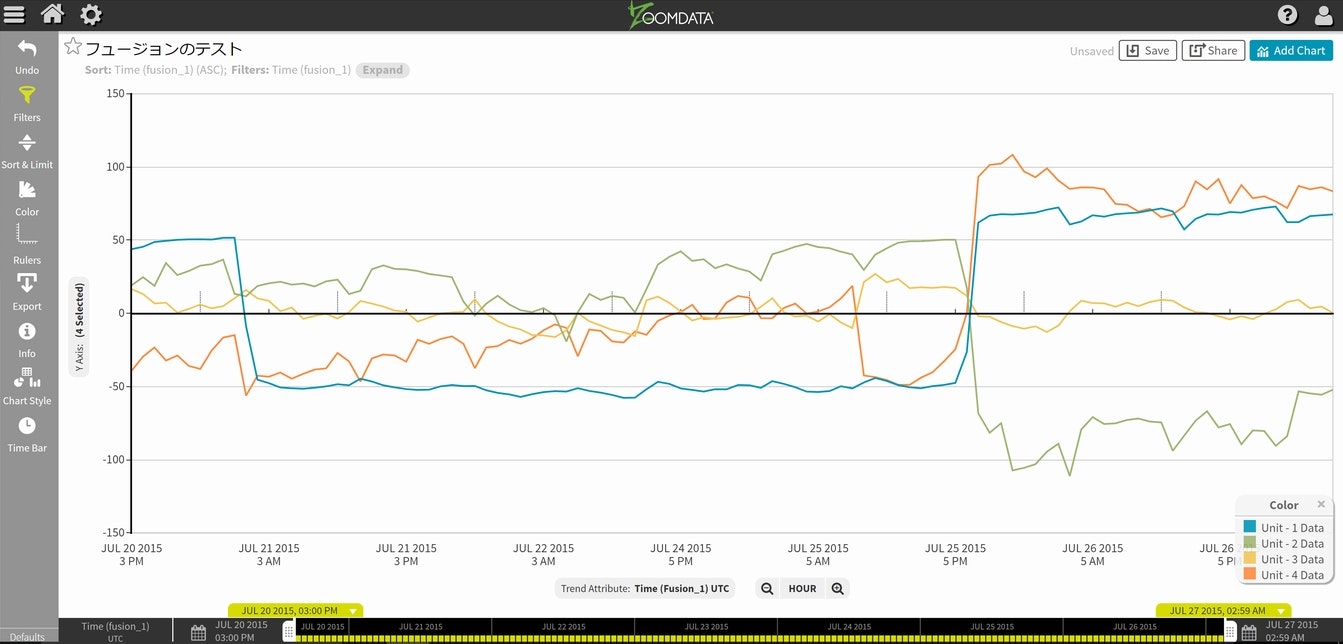
Fusionされたデータは、完全にZoomdataの管理下に入りましたので、条件を変えての再描画もスムーズに行われる事が確認できます。
(4)今回のまとめ
今回は、お試しの番外編ということなので、シンプルな形でのFusionに関する基本的な手順のご紹介となりました。
ポイントとしては
(1)異なるデータソース間でも同様に利用可能
(2)マイクロクエリー効果でビッグデータ同士の場合でもを高い効率と性能が維持できる
(3)Fusion構造は、運用の途中でも柔軟に変更する事が可能
等があります。
ビッグデータに対して、従来型のフルクエリー経由での扱いを前提とした仕組みの場合、効率的で実用的な取り扱いを定常的に実現する事は非常に難しく、逆にそのような要求が発生しないような設計と運用を工夫して行っているのが実情かと思います。「データの最終形を作り出す過程にこそ、新たな戦略や付加価値、また問題解決の新たな糸口がある」というビッグデータ指向の発想や、実用領域に入った機械学習やAI等との効率的な連携を考えた場合に、データの収集・保存・可視化・解析といった領域へのアプローチも仕方が、今後の企業や団体活動における、データハンドリングの重要なポイントになるステージに来ているのかもしれません。
過去の存在しないデータを取り扱う事は非常に困難ですが、出来るだけデータをリアルタイムで詳細に取り込んで、そのプロセスを高速に可視化分析し、仮設をオンストリームで検証しながら柔軟に修正・変更を加える事により、現場での対応や迅速な判断、行動を支援できるような、新たな仕組みの実現こそが、ビッグデータの新たな未来なのです。
事実は、会議室で起きているのではなく、現場で起きている・・・この現実を制した者が、次の市場制覇や効率的な問題解決を獲得できるのだという事なのかもしれません。
次回は、いよいよビッグデータとの連携についてご紹介したいと思います。