はじめに
業務でhadoopについて調べる必要が出て来て参考文献を覗いていたのですが、イマイチわかったようなわからないような・・・。迷っているくらいならやってみるべし。ってことで、AWSのElasticMapReduceを動かしてみました。手元に良いお題がなかったのでapacheのアクセスログを解析してみました。
色々書いていたら長くなってしまいました。EMRだけ知りたい方はJava部分はすっ飛ばして読んでください。
MapReduceのプログラムを書いてみよう。
準備編
MapReduceのプログラムを書くにはhadoop-coreのライブラリが必要です。
依存するライブラリが多く悩んでしまったのでこういうときはmavenに頼ってしまうといいですね。
Eclipseのプロジェクトをmavenプロジェクトに変換後、pomに以下を追加します。
mavenのセントラルリポジトリには2系がなかったので、1.0.3で試してみました。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.3</version>
</dependency>
実際に動かすのに毎回Hadoopなんて動かしてられません。
Hadoop版Junitであるmrunitを使うことでMapのテスト、Reduceのテスト、MapReduce合わせたテストを書くことができます。
こいつもmaven経由でライブラリを取得します。
ここで気をつけなければいけないのがclassifierにhadoopのバージョンを記載する必要があります。これを記載しないとエラーになりますので注意しましょう。
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.0.0</version>
<classifier>hadoop1</classifier>
<scope>test</scope>
</dependency>
Mapのテスト
MapのテストケースはTestFirstで書くとよいでしょう。
JUnitでいうAssertはdriver.withOutputで記載し、一行一行を解析した結果こうなるだろう。という結果を記載します。
inputとなるデータはclasspathからファイルを取得して一行一行をdriver.withInputでMapperに渡しています。
package aws.emr.accesslog;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import junit.framework.TestCase;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.Before;
import org.junit.Test;
public class AccessLogMapperTest extends TestCase {
private Mapper<LongWritable, Text, Text, LongWritable> mapper;
private MapDriver<LongWritable, Text, Text, LongWritable> driver;
@Before
public void setUp() {
mapper = new AccessLogMapper();
driver = new MapDriver<LongWritable, Text, Text, LongWritable>(mapper);
}
@Test
public void testCount() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(
AccessLogMapperTest.class
.getResourceAsStream("/aws/emr/accesslog/access.log")));
String line = null;
while ((line = br.readLine()) != null) {
driver.withInput(new LongWritable(1), new Text(line));
}
driver.withOutput(new Text("/"), new LongWritable(1));
driver.withOutput(new Text("/test"), new LongWritable(1));
driver.withOutput(new Text("/foo/bar"), new LongWritable(1));
driver.withOutput(new Text("/test"), new LongWritable(1));
driver.runTest();
}
}
Mapの実装
テストケースができたので、実装してみます。
Mapではアクセスログの1行の中のpathを取得し、それをキーとしてContextに突っ込みます。アクセスログの解析は正規表現で書いてみました。(ここが実は一番ハマった)
package aws.emr.accesslog;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class AccessLogMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private Text url = new Text();
private static final Pattern PATTERN = Pattern
.compile("^([\\d.]+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+\\-]\\d{4})\\] \"(.+?)\" (\\d{3}) (\\d+) \"([^\"]+)\" \"([^\"]+)\"");
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
Matcher matcher = PATTERN.matcher(line);
if (!matcher.matches()) {
System.err.println("no matches");
}
String path = matcher.group(5).split(" ")[1];
System.out.println("URL:" + path);
url.set(path);
context.write(url, one);
}
}
Reduceのテスト
Reduce前にShuffleした結果こうなって欲しい。というのをdriver.withInputで記載します。ここでは、<"/test":{1}><"/foo/bar":{1,1}>がInputとなり、Reduceした結果、<"/test":{1}><"/foo/bar":{2}>になるようなテストケースを記載しています。
package aws.emr.accesslog;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test;
public class AccessLogReducerTest {
private Reducer<Text, LongWritable, Text, LongWritable> reducer;
private ReduceDriver<Text, LongWritable, Text, LongWritable> driver;
@Before
public void setUp() {
reducer = new AccessLogReducer();
driver = new ReduceDriver<Text, LongWritable, Text, LongWritable>(
reducer);
}
@Test
public void testWordCountReduce() throws IOException {
// <foo : {1,1}>
List<LongWritable> values = new ArrayList<LongWritable>();
values.add(new LongWritable(1));
driver.withInput(new Text("/test"), values);
driver.withOutput(new Text("/test"), new LongWritable(1));
List<LongWritable> values2 = new ArrayList<LongWritable>();
values2.add(new LongWritable(1));
values2.add(new LongWritable(1));
driver.withInput(new Text("/foo/bar"), values2);
driver.withOutput(new Text("/foo/bar"), new LongWritable(2));
driver.runTest();
}
}
Reduceの実装
WordCountとほぼ一緒なので説明省略します。
package aws.emr.accesslog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class AccessLogReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
@Override
public void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
MapReduceのテスト
MapとReduceができたところで、MapReduceのテストを書いてみます。ここまでが理解できていれば大したことありません。setup()でMapperとReducerのインスタンスを作成しています。
テストではファイルを読み込んで得た結果をMap→Reduceして想定される結果を書けばOKです。
package aws.emr.accesslog;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.MapReduceDriver;
import org.junit.Before;
import org.junit.Test;
public class AccessLogMapReduceTest {
private Mapper<LongWritable, Text, Text, LongWritable> mapper;
private Reducer<Text, LongWritable, Text, LongWritable> reducer;
private MapReduceDriver<LongWritable, Text, Text, LongWritable, Text, LongWritable> driver;
@Before
public void setUp() {
mapper = new AccessLogMapper();
reducer = new AccessLogReducer();
driver = new MapReduceDriver<LongWritable, Text, Text, LongWritable, Text, LongWritable>(
mapper, reducer);
}
@Test
public void testAccessLogMapReduce() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(
AccessLogMapperTest.class
.getResourceAsStream("/aws/emr/accesslog/access.log")));
String line = null;
while ((line = br.readLine()) != null) {
driver.withInput(new LongWritable(1), new Text(line));
}
driver.withOutput(new Text("/"), new LongWritable(1));
driver.withOutput(new Text("/foo/bar"), new LongWritable(1));
driver.withOutput(new Text("/test"), new LongWritable(2));
driver.runTest();
}
}
mainクラスの実装
特に説明すること無いので省略
package aws.emr.accesslog;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class AccessLog {
public static void main(String[] args) throws Exception {
Job job = new Job();
job.setJarByClass(AccessLog.class);
job.setJobName("AccessLog");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(AccessLogMapper.class);
job.setReducerClass(AccessLogReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
jarをつくろう
EMRで動かすときにjarを作っておく必要がありますのでmavenで作成しておきましょう。
mvn install
EMRで動かしてみよう
準備(S3以外)
詳しい説明は省略しますが、最低限下記の設定が必要です。
1.Key-Pairの作成
http://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-key-pairs.html#having-ec2-create-your-key-pair
2.EMRロールの作成
http://docs.aws.amazon.com/ja_jp/ElasticMapReduce/latest/DeveloperGuide/emr-iam-roles.html
S3の設定
EMRのinputとoutputはS3になります。
1.Bucketを作る(uzr.emr.examples)
2.入力ファイル格納場所(input)、jar格納場所(jar)、ログ出力先(logs)を作成します。
(outputディレクトリはEMRが実行時に作成するので作ってはいけません。Cluster実行時にエラーになります)
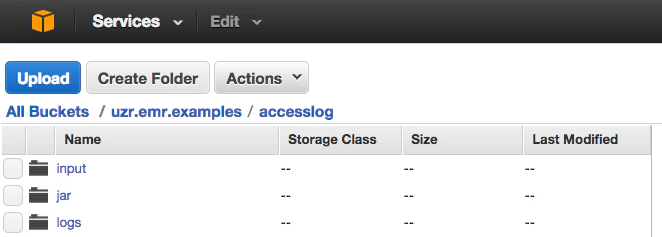
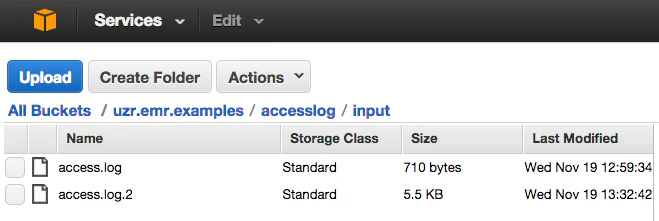
3.inputディレクトリにinputファイルをアップロードします。
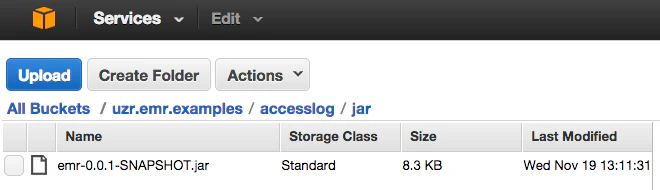
4.jarをアップロード
EMRの設定
やっとここまできました・・・・。EMRの設定を行います。
1.ClusterList画面で、[CreateCluster]を押します。
2.ClusterConfiguration
- ClusterName 適当でいいです。
- Termination protection 消さないように保護するか否か
- Logging ログがでないと失敗した時にさっぱりわからないのでEnableにします。先ほど作ったlogのディレクトリへのs3urlを入力します。

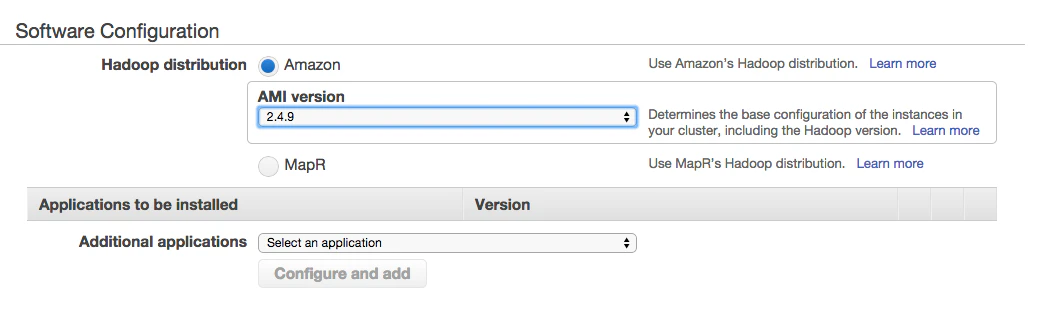
3.SoftwareConfiguration
- hadoopの1.0.3なのでそれに合わせたテンプレートを選択します。
- Applications to be installedではhiveやpigなどが選択できますが利用しないので消しました。
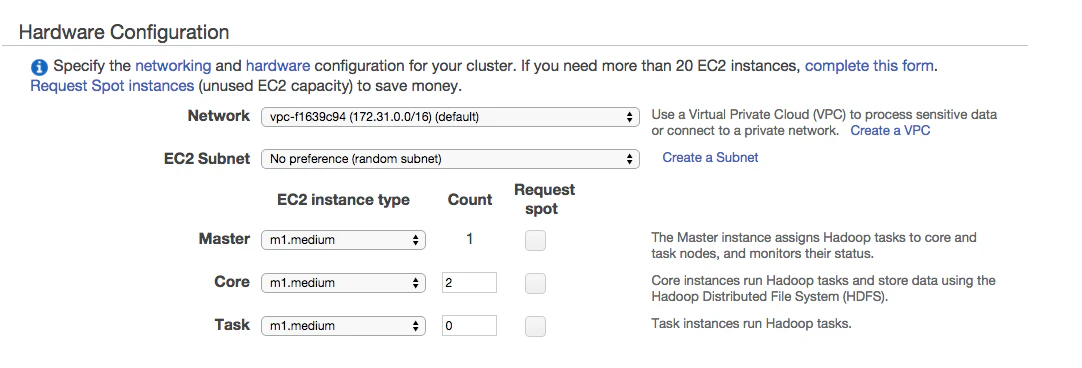
4.HardwareConfiguration
MasterとSlaveのサーバを選択します。どれがよいのかわからなかったので1世代前のお安めのEC2サーバを選択しました。
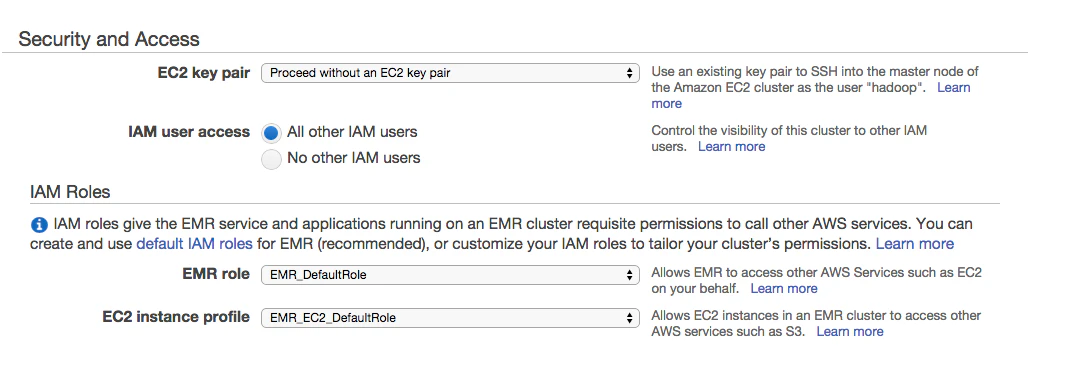
5.key-pairとRollの設定
とくに考えず。選ぶだけです。
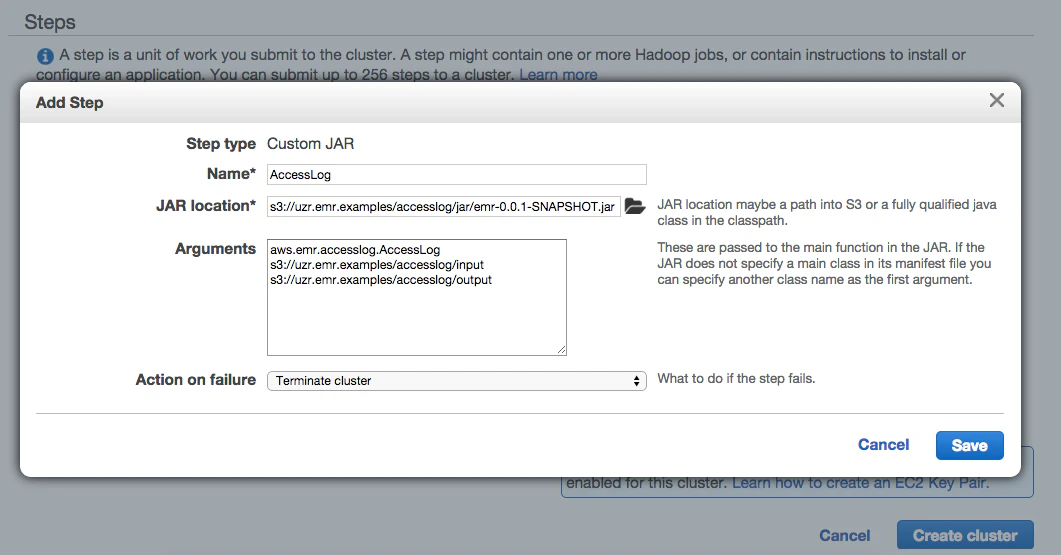
6.Steps(ここポイントです。)
CustomJARを選択すると↓のような画面が出てきますのでこんな感じで設定します。
Action on FailureはClusterがコケた時にどうするか。てことで、EC2も自動で落としておきたいのでTerminatedを選択しました。
動かしてみる
EC2サーバを立上げ→Hadoopのインスタンスを立ち上げ→Stepにしたがって実行。という感じで流れます。
1.CreateCluster
CreateClusterボタンを押すとClusterが起動されます。
まずは画面左下のRunningとなっている部分が、Provisioning→BootStrapping→Runningと変わっていきます。
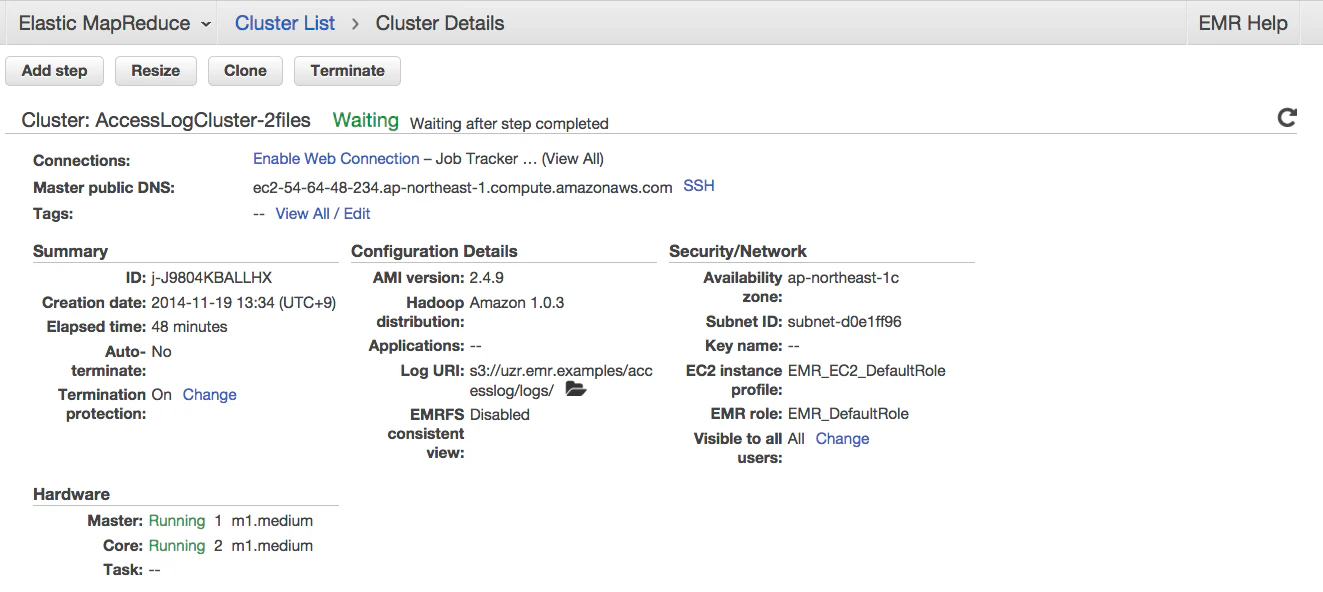
2.次にStep実行が動きます。これがCompleteになれば完了です。
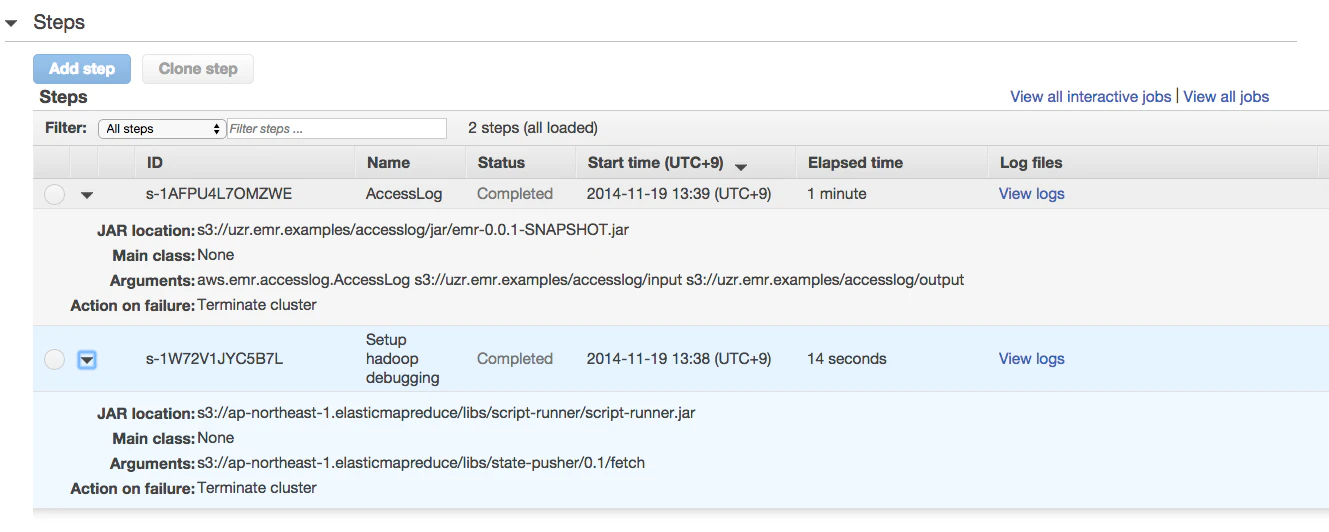
3.結果
結果はS3bucketのoutputディレクトリを覗いてみましょう。こんな感じでファイルができているはずです。
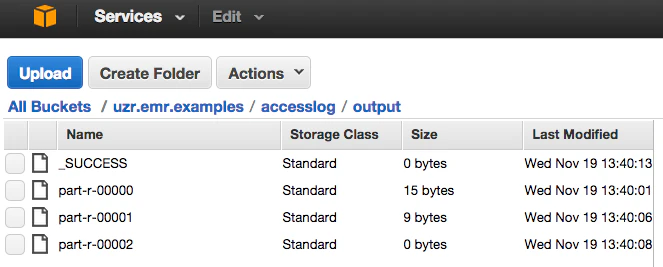
/ 9
/foo/bar 9
/test 18
最後に
EMRはEC2のインスタンス利用料がメインになりますが、1時間使っていなくても1時間使った分の料金が請求されますので気をつけましょう。
(今回のサンプル含め1回3サーバで10回位動かしまして、$2くらいでした。)
参考