Dockerのlogging driver
DockerのLogging Driverには、様々な種類があります。
https://docs.docker.com/engine/admin/logging/overview/
ここでは、そのなかからjson-file syslog journald fluentdの4つを考えてみます。
きっかけは、そもそもDockerのログをどう管理していくかに悩んでいたためです。
ちなみに、環境はUbuntu(xenial)で試しています。
json-file
Logging Driverのデフォルトです。明示的に指定しなかったらこれになります。
docker run --name hello-world hello-world
実体は、 /var/lib/docker/containers/<container id>/<container id>-json.log にあります。
{"log":"Hello from Docker!\n","stream":"stdout","time":"2017-04-08T15:27:02.505963424Z"}
メリット
簡単
なんといっても、docker logs コマンドで気軽に見ることができる、ということでしょう。手元でテストするときにはこれで十分かと思います。
デメリット
ログの集約がしづらい
一方、プロダクション用途ではほぼ使えないと思います。複数のコンテナを管理する場合、ログの集約がしづらいためです。
コンテナIDの部分が常に変わる上、ログファイルの中にはコンテナIDなどの識別する情報がありません。(もちろん頑張れば可能ですが)
なんか障害が起きてる、というときに、docker logsコマンドで1つ1つ見ていくわけにも行きません…。
Dockerホストのディスク容量を消費
ローカルにログを出力するので、当然ディスク容量を消費します。(サイズ制限はできますが)
syslog
OSのログ管理に任せてしまう方法です。
docker run --name hello-world --log-driver=syslog hello-world
/var/log/syslog にメッセージが表示されます。
Apr 8 15:40:47 ubuntu-xenial 50e26b6cd9f2[1030]: Hello from Docker!
メリット
簡単
細かいことを考えなくても、ログを統合的に見ることができます。
他Dockerホストも含めて集約が可能
オプションによって、リモートのsyslogサーバにログを飛ばすこともできます。
信頼性が高い
安全と信頼のsyslogなので、何があってもきっとログは取ってくれているだろうという安心感はあります。(実際どうなんでしょう?)
デメリット
運用で使うレベルで集約管理を行いづらい
1つにまとめられるだけで、これを目的に応じて分けて見るなど、実際に運用で使うのは至難の業です。facilityで分けるという手もありますが、それにしたってsyslogをパースして使える形に持っていくのはなかなか厳しいです(というより、なんでsyslogっていう選択肢を取らなきゃいけないんだっけというレベル)
あと、syslogはOSそのものの挙動などをログ管理するものであって、あんまりミドルウェアプロセスのログを吐かせたくないという気持ちがあるのですが、個人的な気持ちなのでしょうか…。
docker logsコマンドで見られない
docker logsコマンドでは見ることができなくなります。(docker logsコマンドは、 json-fileかjournaldの2つでしか使えない)
Dockerホストのディスク容量を消費
json-fileと同様です。
journald
systemd管理上でのログ管理システムに任せる方法です。Dockerホスト上の全てのコンテナが(logging driverをjournaldに指定すれば)統合管理できます。最近のOSはsystemdが採用されているため、安心感があります。
docker run --name hello-world --log-driver=journald hello-world
ログは、journalctl コマンドで見ることになります。journalctlコマンドは、出力フォーマットを変えたり、特定のサービスだけに絞って表示ができたりと、かなり高性能です。
例えば、以下のような感じで絞ることができます。
journalctl -u docker.service --output=json-pretty CONTAINER_NAME=hello-world
{
"__CURSOR" : "s=a9435ef2c73241af93f59ff19af7688c;i=4ea;b=ba0a48cc450942e3b1f8406fdebece91;m=382cb867;t=54ca5aad769ec;x=15490b2f9c0f4889",
"__REALTIME_TIMESTAMP" : "1491649303112172",
"__MONOTONIC_TIMESTAMP" : "942454887",
"_BOOT_ID" : "ba0a48cc450942e3b1f8406fdebece91",
"PRIORITY" : "6",
"_TRANSPORT" : "journal",
"_UID" : "0",
"_GID" : "0",
"_CAP_EFFECTIVE" : "3fffffffff",
"_MACHINE_ID" : "e5bfbf052b82482e86f3c27a6fae07e2",
"_HOSTNAME" : "ubuntu-xenial",
"_SYSTEMD_SLICE" : "system.slice",
"_PID" : "3400",
"_COMM" : "dockerd",
"_EXE" : "/usr/bin/dockerd",
"_CMDLINE" : "/usr/bin/dockerd -H fd://",
"_SYSTEMD_CGROUP" : "/system.slice/docker.service",
"_SYSTEMD_UNIT" : "docker.service",
"MESSAGE" : "Hello from Docker!",
"CONTAINER_NAME" : "hello-world",
"CONTAINER_TAG" : "34babc6d9579",
"CONTAINER_ID" : "34babc6d9579",
"CONTAINER_ID_FULL" : "34babc6d9579d234a4ba5f14cc342d4e247f081e2feba36b8a798a27c4e22c04",
"_SOURCE_REALTIME_TIMESTAMP" : "1491649303111731"
}
メリット
簡単
docker logs コマンドで簡単に見ることも出来ます。
集約して見ることもできる
一方で、journalctlコマンドでまとめて見ることもできます。その中から絞って見ることもできるといい事づくしです。
デメリット
リモートからの集約はできない
複数のDockerホストを使っている場合、それらのログをさらに集約する方法は別途考えなければなりません。
Dockerホストのディスク容量を消費
json-fileと同様です。ただ、journaldは圧縮が効くので、そこまで悲観するほどでもありません。
不安定…かもしれない
標準的に採用されているsystemdの中のログ管理なので、安定と信頼の…と思いきや、ここ最近までのDockerだとバグがあって、docker engineごと使えなくなるという問題がありました。これにめちゃくちゃ悩まされました。
GitHub: dockerd died unexpectedly crashreport · Issue #30433
今はどうなんでしょう?
余談
journald側の設定をちゃんとしないと、流量が多すぎると勝手に切り捨てられたりします。
journald.conf(5) - Linux manual page - man7.org
fluentd
fluentdにログを飛ばし、そちらで管理を任せてしまう方法です。
docker run --name hello-world --log-driver=fluentd --log-opt fluentd-address=localhost:24224 --log-opt tag="docker.{{.Name}}" hello-world
fluentd側ではこういう風に見えます。(@type stdoutの例)
2017-04-08 11:25:45 +0000 docker.hello-world: {"container_id":"668f66d702f676323859698766106b53038d0716669d9e325714875ecaba4536","container_name":"/hello-world","source":"stdout","log":"Hello from Docker!"}
fluentd側の設定(参考)
あくまで検証用ですが、こんな感じです。
<source>
@type forward
port 24224
</source>
<match docker.**>
@type stdout
</match>
docker run -p 24224:24224 -p 24224:24224/udp -v /tmp/fluent.conf:/fluentd/etc -e FLUENTD_CONF=fluent.conf --name=fluentd fluent/fluentd
メリット
ログを統合管理しやすい
fluentd(およびその先の何か)にログ周りを任せてしまえばいいので、統合的に管理・分析などが行いやすいです。
Dockerホストのディスク容量を消費しない
そのまま転送するので、ホスト側にファイルを配置したりしません。
デメリット
docker logs コマンドで見られない
syslogと同様です。
fluentdが死んだら終わり
ただ、Docker側のlog-optオプションによって、バッファやリトライなどの設定ができるため、言うほど「終わり」ではありません。fluentd側が再起動後、ちゃんと再送されてくるので、ほとんどは救うことができます。
fluentdが死んだらどうなる?
コンテナ起動時に既にfluentdが死んでいる場合
# docker run --name hello-world --log-driver=fluentd --log-opt fluentd-address=localhost:24224 --log-opt tag="docker.{{.Name}}" hello-world
docker: Error response from daemon: Failed to initialize logging driver: dial tcp 127.0.0.1:24224: getsockopt: connection refused.
こんな感じで、起動すらしません。
コンテナ起動後、途中でfluentdが死んだ場合
例えば、こんなコンテナを起動します。
docker run -it --name logging-driver-test --log-driver=fluentd --log-opt fluentd-address=localhost:24224 --log-opt tag="docker.{{.Name}}" --rm alpine ash
起動後、こんな簡易的なシェルスクリプトを回してみます。
for a in `seq 1 1000` ; do
echo "this is $a"
date +"%Y/%m/%d %H:%M:%S"
sleep 0.1
done
このスクリプトの実行途中で、わざとログの受け先となるfluentdを落として、あとで起動します。(だいたい100〜200の間落としてみました)
結果は、「一部欠落する」でした。
(略)
2017-04-08 14:51:35 +0000 docker.logging-driver-test: {"container_id":"b8ead797c7da8e06fbaceac1177a75500330ebb7da39970beb084eb69ce3cd0f","container_name":"/logging-driver-test","source":"stdout","log":"this is 101\r"}
2017-04-08 14:51:35 +0000 [info]: shutting down fluentd
2017-04-08 14:51:35 +0000 [info]: shutting down input type="forward" plugin_id="object:2acd360dce14"
2017-04-08 14:51:35 +0000 [info]: shutting down output type="stdout" plugin_id="object:2acd36327e1c"
2017-04-08 14:51:35 +0000 [info]: process finished code=0
2017-04-08 14:51:46 +0000 [info]: reading config file path="/fluentd/etc/fluent.conf"
2017-04-08 14:51:46 +0000 [info]: starting fluentd-0.12.34
2017-04-08 14:51:46 +0000 [info]: gem 'fluentd' version '0.12.34'
2017-04-08 14:51:46 +0000 [info]: adding match pattern="docker.**" type="stdout"
2017-04-08 14:51:46 +0000 [info]: adding source type="forward"
2017-04-08 14:51:46 +0000 [info]: using configuration file: <ROOT>
<source>
@type forward
port 24224
</source>
<match docker.**>
@type stdout
</match>
</ROOT>
2017-04-08 14:51:46 +0000 [info]: listening fluent socket on 0.0.0.0:24224
2017-04-08 14:51:36 +0000 docker.logging-driver-test: {"container_name":"/logging-driver-test","source":"stdout","log":"this is 103\r","container_id":"b8ead797c7da8e06fbaceac1177a75500330ebb7da39970beb084eb69ce3cd0f"}
2017-04-08 14:51:36 +0000 docker.logging-driver-test: {"source":"stdout","log":"2017/04/08 14:51:36\r","container_id":"b8ead797c7da8e06fbaceac1177a75500330ebb7da39970beb084eb69ce3cd0f","container_name":"/logging-driver-test"}
fluentdを落とす直前が101で、起動後は103から拾っているので、102が欠落していることが分かります。が、これはもうどうしようもないかなと思います。
結局、logging driverは何を使うべきか & Dockerコンテナのログ管理はどうするべきか
おそらく、大抵の場合は、(もちろん障害解析のときに、取りこぼさないことが理想ではありますが)「ログを1行たりとも欠損してはならない」という要件はないのではないでしょうか?そうなるとfluentdでログを飛ばして、集約管理するということで済むと思います。
docker logsコマンドでログを気軽に見られないというデメリットはあるにはありますが、そもそもdocker logsに頼って、これを必須の要件として見まくるような状況はそれはそれでヤバイ気がします。
ただ、何かあったときにDockerホストにログが残っているという安心感は変え難く、その場合はjournaldが良さそうな気がします。
ぼくのかんがえたさいきょうのログかんり
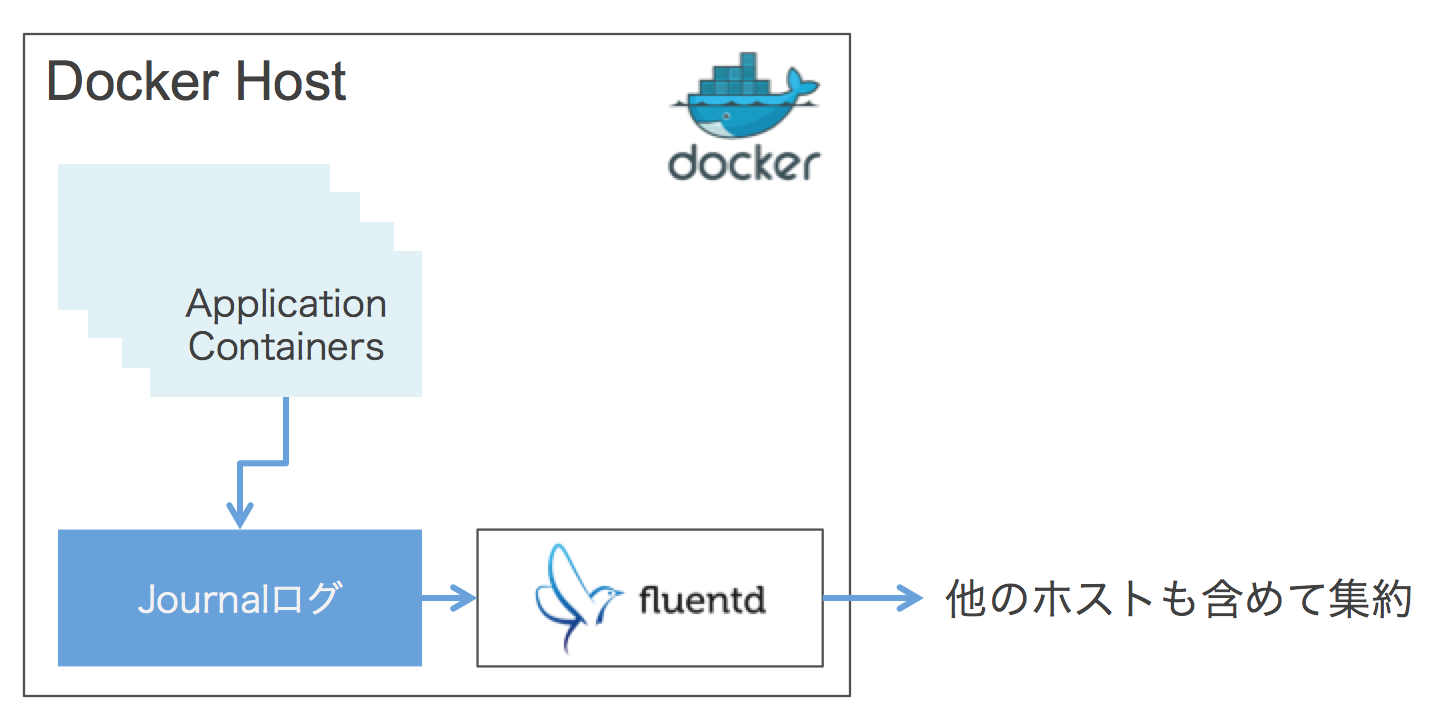
fluentdとjournaldを組み合わせた使い方です。これによって、journald単体でのデメリットを消して、fluentdで全体的に集約を行うこともできるようになります。
journaldは信頼度が高い(はず)なので、ここにまずは記録していくことで、取りこぼしやログの消失を防ぎます。fluentdは、ここから読み込むことで、コンテナとの直接的な関与をなくします。また、fluentd自体がファイルのposition情報を持つことができるので、異常終了したとしても、次回起動時に途中から読み直すことができます。
fluentdは、以下のプラグインを利用しています。
systemd input plugin for Fluentd
これで問題なさそう…なのですが、このアーキテクチャを実現しようとしていたところに、先述のDocker & journald周りのバグにぶつかって死にかけたので、じゃあどういうログ管理がベストなんだろう?と悩んでいます。今ならもうバグを気にする必要はないのかもしれませんが。
おまけ: logspout
Dockerコンテナのstdout/stderrを勝手に拾ってルーティングしてくれるものです。Dockerホスト上に立ち上げておくと、勝手に全コンテナのログを拾って、指定されたところにルーティングしてくれます。
メリット
logging driverを何も設定しなくてもいい
何も設定せず、ただDockerホスト上にlogspoutコンテナを立ち上げるだけで勝手に拾ってくれます。ものすごく簡単です。(もちろん、拾った上でどこにルーティングするかの設定は必要です)
デメリット
ルーティングすることが目的のツール
It's a mostly stateless log appliance. It's not meant for managing log files or looking at history.
ステートレスなので、どこまでログを見たかという情報がありません。なので、ひとたびlogspoutがダウンして、起動し直したら、前回障害時点から遡って読んでくれたりはしません。(細かい挙動は忘れました。ごめんなさい)
開発環境くらいだったら、これくらい気楽につかえてもいいのかなーとは思います。
あと、Rancher ではcatalogとして簡単にlogspoutが使えるのですが、そのときにRancher -> logspout -> fluentd という設定で使ったときは、fluentdを再起動したりすると、漏れなくlogspout側も再起動しないと二度と繋がらないということはありました。それもあって、logspoutは早々に使うのをやめたことがあります。