はじめに
任意のテキストファイルにどのような特性があるのか?そのテキストファイルに、ネガティブな発言が多いか、それとも、ポジティブな発言が多いかの傾向をざっくりと把握するには、ネガポジ度を分析するとよいです。このTipsでは、とある組織のウィークリーレポートを使って、その内容にどのような特性があるのかを分析してみます。手順としては、①ウィークリーレポートをRMeCabで形態素解析後、②単語感情極性表(注1)からスコアを算出し、③ネガポジ度を三次元円グラフで描画します。単語感情極性とは、その語が一般的に良い印象を持つか(positive) 悪い印象を持つか(negative)を表したものです。例えば、「良い」、「美しい」などはpositiveな極性、 「悪い」、「汚い」などはnegativeな極性を持ちます。
テキストのネガポジ度を分析する
▼サンプルスクリプト
R
# 三次元円グラフライブラリを読み込みます
library(plotrix)
# 日本語形態素解析ライブラリを読み込みます
library (RMeCab)
# 単語感情極性表(Semantic Orientations of Words)を読み込みます
sowdic <- read.table("http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic",sep=":",col.names=c("term","kana","pos","value"),colClasses=c("character","character","factor","numeric"),fileEncoding="Shift_JIS")
# 名詞+品詞で複数の候補がある場合は平均値を採用します
sowdic2 <- aggregate(value~term+pos,sowdic,mean)
# ポジティブとネガティブを調整します(より傾向を出すため)
sowdic2$value <- sowdic2$value + 0.6
# 形態素解析の結果から頻度表を作成します
war2007 <- RMeCabFreq("WAR2007_20140131-1258.txt")
※「WAR2007_20140131-1258.txt」はウィークリーレポートをテキスト化したものです。以下は、テキストの例です。

ネガポジ度を三次元円グラフで描画する
▼サンプルスクリプト
R
# 単語感情極性表に含まれるものを抽出します
war2007 <- subset(war2007,Term %in% sowdic2$term)
# 単語感情極性表の属性をマージします
war2007 <- merge(war2007,sowdic2,by.x=c("Term","Info1"),by.y=c("term","pos"))
# キーワード毎にスコア算出します
score2007 <- war2007[4:(ncol(war2007)-1)]*war2007$value
# 描画用データを作成します
war2007 <-c(sum(score2007 > 0),sum(score2007 < 0))
# 描画用ラベルを作成します
lbls <- c("positive", "negative")
lbls <- paste(lbls, war2007, sep=":")
# 三次元円グラフを描画します
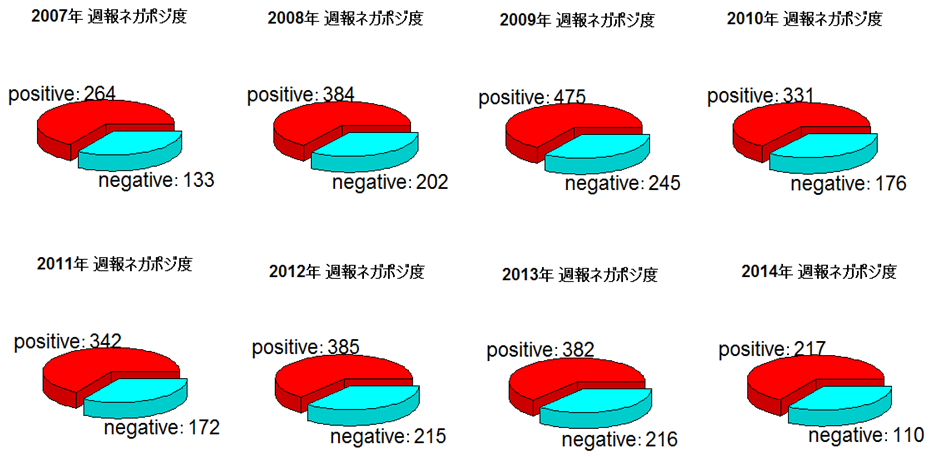
pie3D(war2007, radius=0.9, labels=lbls, explode=0.1, main="2007年 週報ネガポジ度")
▼実行結果例
上記のサンプルコードは、2007年度の1年分をグラフ化したものです。これを2014年度分まで出力したものが次のグラフになります。
注釈
注1 今回の分析で利用させて頂いた、単語感情極性対応表はこちら↓
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html