今年もWACULのアドベントカレンダー、順調に埋まって、残すところ2日です。
クリスマスイブを担当する、CTOの包です。
なかなか濃い記事がいっぱいあって、よくもまぁこんな人達が集まったなぁという感慨深い感じです。
今日は妻と娘たちとケーキを作って食べました。ホイップクリームを泡立器で作ったら疲れたのでブレンダーがほしいです。
アクセス解析サービスを作ろう
さてさて、今回は、(弊社のような)弱小企業に務めるあなたが、会社の偉い人とかに、Webサイトにいれるアクセス解析ツール作ってね!しかも一人で!
とか言われた時のために、GCPを使った構成を考えて検証してみました。
(あたなが、goとjavaをちょっと書けること前提です!)
検証なので、細かいエラー処理などは省いていますのでご了承を。
アクセス解析ツールの構成部品
Webのアクセス解析ツールを作るにはほんっとざっくり言うと
- 何はともあれ、ログ収集部分
- サイトに入れてもらうjsのタグ開発
- データの収集サーバー ★今回のテーマ★
- とりあえずログをもれなく貯められればあとからなんとかなるはず!
- 中間DB(やりたいことに合わせてクエリしやすいようにデータ加工)
- 生ログから、意味のあるラベルに様々な手法を使ってラベル付けする。 (IPから地域、UAからブラウザ etc... )
- 適宜サンプリングとかがんばる
- データの集計、可視化
- 使いやすいUIつくりましょう
ということになると思います。Google Analytics とかずっといじってる身からすると、PV数が多いサイトに耐えるシステム作るのはそれはそれは大変だな、と思うのですが、偉い人に言われたらしょうがないですね。
Q: で、どのくらいの規模のサイトに導入するんですか?
A: (偉い人)うーん、わかんないけど、将来的には〇〇(巨大ポータル)とか☓☓(巨大EC)に入れたいかな
ということで、月間 1億PV ぐらいのサイトにはポンポンいれたいようですね!
大きい会社に導入することで、全体の処理量が一気に跳ね上がる感じです。ちょっと多めに見積もって、50億PVぐらい捌けるシステムを作らないとですかね。
50億PVっていうのは
50億PV / (30 日 * 24 時間 * 3600 秒) = 1929 PV/s
ぐらいですね。均等にはこないはずなので、 ピーク時には、だいたい 3000 PV/s ぐらい捌ければいいでしょうか。
データ収集サーバーを作ろう
データ収集サーバーに求められることはなんでしょう
- ダウンタイム 0
- ユーザーがブラウザを開いている間しかデータはとれません。サーバーが1瞬でも落ちていると、データは欠損します
- 安いサーバー費
- 大量のデータを処理するので、サーバー費などのコスト意識は重要です、お金かからない方法を探りましょう
- メンテンナンスしやすさ
- とはいえ、一番高いのは人件費です。リソースが少ない中で良いサービスを作るには、日々の運用に取られる時間は最小限にしたいです
ということで、ログを取り逃がさずに低コストでシンプルな作りのシステムにしないといけないようです。
GCP でどう作るか
ということで作ってみた構成がこちらです。
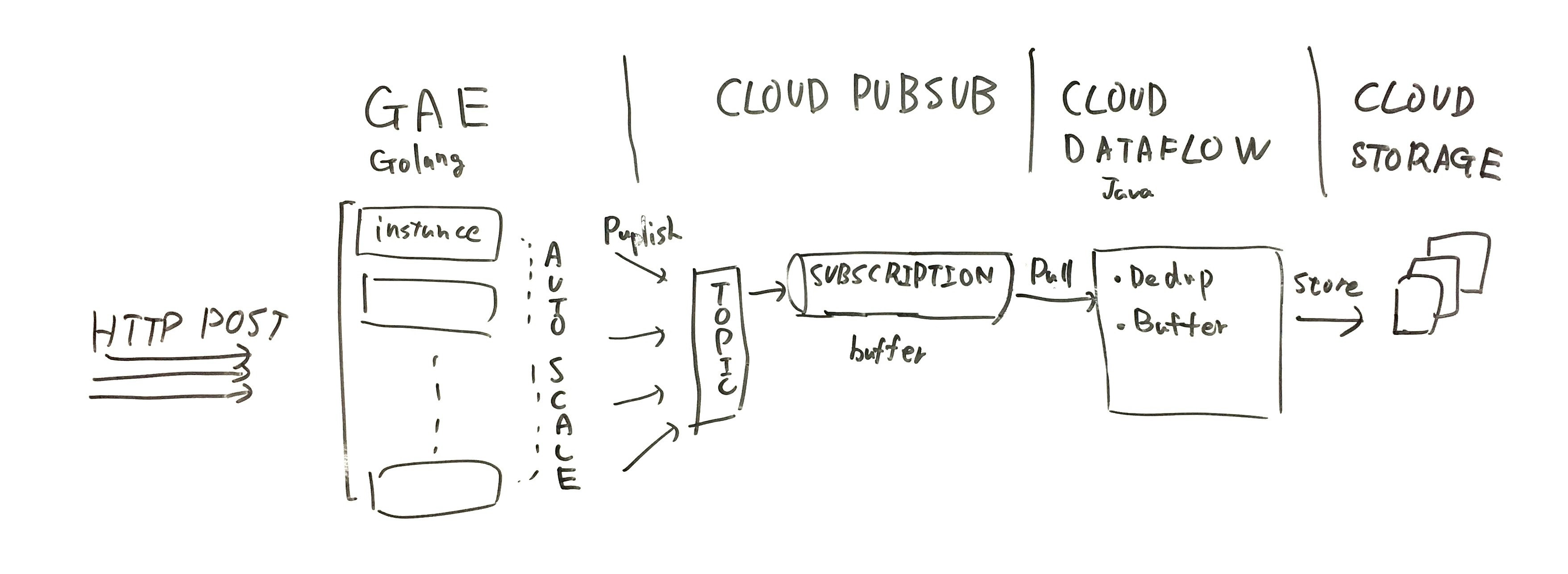
GAE Golang Standard Environment (Webフロントサーバ)
Webサイトに貼り付けたjsのタグからのデータを受け付けるサーバーには
Google App Engine を使うのが良さそうです
今年の中頃に、メルカリさんの子会社のサービス、アッテ が、GAEで動いていることを知りました。
「メルカリ アッテ」を支える Google App Engine と Golang
https://speakerdeck.com/ttsuruoka/merukari-atute-wozhi-eru-google-app-engine-to-golang
GAE自体はすごく古いサービスなのですが、驚いたのが、Goで実装した場合、AppEngineのインスタンス(GCEのインスタンスとは別の概念)は、 数十ms で起動する、ということでした。これによって、リクエスト数に応じて、相当フレキシブルにスケーリングできそうです。
また、デプロイ周りも、新しいバージョンをアップして、数% 新しいサーバーにトラフィックを流してみて、OKそうだったら全部切り替える、なんていう運用ができますので、ダウンタイム0のシステムを目指すには、良い選択肢になりそうです。
ちなみに、App Engine には、Standard Environment と、Flexible Environment というのがあります。紛らわしいんですが、 Flexible Environment のほうはインスタンスの起動に分単位で時間がかかります
参考: https://cloud.google.com/appengine/docs/the-appengine-environments#comparing_environments
Cloud Pub/Sub (データのバッファリング)
GAEで受け取ったデータは、Cloud Pub/Sub に送るだけにしましょう。
Cloud Pub/Sub は、 AWS でいうところの、 SQSとSNSと、Kinesis を足した感じのサービスです。
At least once の配信保証と、7日間のデータをバッファリングしてくれます。
後続のデータ処理については、ある程度停止してメンテナンスする猶予を持たせることができます。
Cloud Dataflow (データのマージ処理)
受け取ったログは、一旦ファイルに書き出して、後から処理できるように保存したいです。
しかし、たとえば1リクエストを1ファイルに保存すると、月間数十億ファイルできてしまいます。
一般的にファイルシステムはそのような想定で作られていないため、複数のリクエストを1ファイルにまとめる必要があります。例えば、5分間分を1ファイルにする、などです。
そういったストリームデータの処理を担うのが Cloud Dataflow です。
こちらは、概念的な部分は、拙著の前回のアドベントカレンダーの記事をご覧ください。
Cloud Storgage (データの保存先)
ファイルの保存先です。 Amazon S3 と同じですね。
一度 Cloud Storage にファイルが出来てしまえば、 BigQuery などには簡単にインポートできます。
いざ実装
GAE からCloud Pub/Subへ
GAEの環境構築などはチュートリアルを見ていただくとして、必要なのは2ファイルです。
また、事前に Pub/Sub に、 collect という名前のトピックを作っておきましょう。
collect.go
goでのサーバーの実装です。
今回は、 collect という Pub/Sub のトピックに POSTで受け取った内容をそのままパブリッシュします。
ちなみに、以下の点はこの先改良する必要がありますが、今回は検証なので放置です。
- bodyの長さ制限
- bodyの内容チェック & 整形
- 後述しますが、最終的にファイルに1行ずつ書き込んでいく関係で改行が入ってると困ることになります
- エラー処理もろもろ
package main
import (
"io/ioutil"
"net/http"
pubsub "cloud.google.com/go/pubsub"
"github.com/rs/cors"
"google.golang.org/appengine"
)
func init() {
mux := http.NewServeMux()
mux.HandleFunc("/collect", collect)
handler := cors.Default().Handler(mux)
// Handle all requests using net/http
http.Handle("/", handler)
}
func collect(w http.ResponseWriter, r *http.Request) {
ctx := appengine.NewContext(r)
// Body の内容をそのまま[]byteに
bs, err := ioutil.ReadAll(r.Body)
if err != nil {
panic(err)
}
// PtojectIDを取得してクライアント作成
client, err := pubsub.NewClient(ctx, appengine.AppID(ctx))
if err != nil {
panic(err)
}
// トピックに配信
tp := client.Topic("collect")
if _, err := tp.Publish(ctx, &pubsub.Message{Data: bs}); err != nil {
panic(err)
}
w.WriteHeader(http.StatusNotModified)
}
func main() {
http.ListenAndServe(":8080", nil)
appengine.Main()
}
app.yaml
App Engine の環境設定ファイルです。
重要なこととしては、 automatic_scaling のパラメータを適宜調整してあげないと、スケーリングにコストがかかったり、逆にレスポンスが遅延したりします。
インスタンスサイズの最適化など、運用の中で調整していく必要がありそうですね。
とりあえずちょっと手元でいじってみた感じ、以下のようなパパラメータでいくことにします。
参考: http://qiita.com/sinmetal/items/017e7aa395ff459fca7c
application: <your-app-id here>
version: alpha-001
runtime: go
api_version: go1
threadsafe: true
instance_class: F1
automatic_scaling:
min_idle_instances: automatic
max_idle_instances: 1
min_pending_latency: automatic
max_pending_latency: 300ms
max_concurrent_requests: 100
handlers:
- url: /.*
script: _go_app
Cloud Dataflow で Cloud Pub/Sub から、Cloud Storgae へ
次に、 Cloud Dataflow のコードを書きます。 javaです、環境構築は頑張りましょう。 しかし java はIDEないときついですね。。
事前に、先程つくった、 Pub/Sub の collect トピックに、 collect-store とかいう名前でサブスクリプションを作っておく必要があります。(名前はなんでもよい)
いろいろ調整した結果、以下の用になりました。
オプションで、 以下を指定して実行します。
--project=<プロジェクト名 \
--input=<Pub/Subのサブスクリプション名> \
--outputPath="GCSの、ファイル名のプレフィックス"
--outputBucket="GCSの、バケット名"
--stagingLocation="ステージング用ファイル置き場"
package com.wacul.cloud.dataflow.store;
import com.google.cloud.WriteChannel;
import com.google.cloud.dataflow.sdk.Pipeline;
import com.google.cloud.dataflow.sdk.coders.KvCoder;
import com.google.cloud.dataflow.sdk.coders.StringUtf8Coder;
import com.google.cloud.dataflow.sdk.io.PubsubIO;
import com.google.cloud.dataflow.sdk.options.DataflowPipelineOptions;
import com.google.cloud.dataflow.sdk.options.Description;
import com.google.cloud.dataflow.sdk.options.PipelineOptionsFactory;
import com.google.cloud.dataflow.sdk.options.Validation.Required;
import com.google.cloud.dataflow.sdk.runners.DataflowPipelineRunner;
import com.google.cloud.dataflow.sdk.transforms.*;
import com.google.cloud.dataflow.sdk.transforms.windowing.FixedWindows;
import com.google.cloud.dataflow.sdk.transforms.windowing.Window;
import com.google.cloud.storage.BlobInfo;
import com.google.cloud.storage.Storage;
import com.google.cloud.storage.StorageOptions;
import org.joda.time.Duration;
import org.joda.time.format.ISODateTimeFormat;
import java.nio.ByteBuffer;
import java.util.Iterator;
public class StorePipeline {
private static class DoGCSWrite extends DoFn<Iterable<String>, Void>
implements DoFn.RequiresWindowAccess {
private String path;
private String bucket;
public DoGCSWrite(String bucket, String path){
this.bucket = bucket;
this.path = path;
}
@Override
public void processElement(ProcessContext c) throws Exception {
Storage service = StorageOptions.getDefaultInstance().getService();
String isoDate = ISODateTimeFormat.dateTime().print(c.window().maxTimestamp());
long paneIndex = c.pane().getIndex();
String file = String.format("%s-%s-%s", this.path, isoDate, paneIndex);
WriteChannel writer = service.writer(BlobInfo.newBuilder(this.bucket, file).setContentType("text/plain").build());
Iterator<String> it = c.element().iterator();
while(it.hasNext()){
writer.write(ByteBuffer.wrap(it.next().getBytes()));
writer.write(ByteBuffer.wrap("\n".getBytes()));
}
writer.close();
}
}
public interface MyOptions extends DataflowPipelineOptions {
@Description("Output storage bucket")
@Required
String getOutputBucket();
void setOutputBucket(String bucket);
@Description("Output storage path")
@Required
String getOutputPath();
void setOutputPath(String path);
@Description("Input Pubsub subscription")
@Required
String getInput();
void setInput(String input);
}
public static <OutputT extends com.google.cloud.dataflow.sdk.values.POutput> void main(String[] args) {
PipelineOptionsFactory.register(MyOptions.class);
MyOptions options = PipelineOptionsFactory.fromArgs(args)
.withValidation()
.as(MyOptions.class);
options.setRunner(DataflowPipelineRunner.class);
options.setStreaming(true);
options.setRunner(DataflowPipelineRunner.class);
Pipeline p = Pipeline.create(options);
p.apply(PubsubIO.Read.subscription(options.getInput()))
.apply(Window.<String>into(
FixedWindows.of(Duration.standardMinutes(5)))
.withAllowedLateness(Duration.ZERO)
.discardingFiredPanes()
)
.apply(WithKeys.of((String input) -> "constant"))
.setCoder(KvCoder.of(StringUtf8Coder.of(), StringUtf8Coder.of()))
.apply(GroupByKey.create())
.apply(Values.create())
.apply(ParDo.of(new DoGCSWrite(options.getOutputBucket(), options.getOutputPath())));
p.run();
}
}
はい、できた!
ポイントとしては、Pub/Subからのインプットを、5分間の固定ウィンドウに分割しています。
その5分間分の情報を、GCSに書き込む部分は自前で実装しました。 (デフォルトの TextIOは、ウィンドウごとの書き込みができない(?))
動かしてみよう
さあさあ、これで いろいろ試してみましょう。
以下のような雑なgoのプログラムを書いて、リクエストを並列で大量に投げてみます。
package main
import (
"bytes"
"fmt"
"net/http"
"os"
"os/signal"
"strconv"
"sync/atomic"
"syscall"
"time"
)
var client *http.Client
func main() {
msgPerSec, err := strconv.Atoi(os.Args[1])
if err != nil {
panic(err)
}
cnt := int64(0)
sig := make(chan os.Signal, 1)
signal.Notify(sig,
syscall.SIGTERM,
syscall.SIGINT,
syscall.SIGQUIT,
syscall.SIGHUP,
)
transport := &http.Transport{
MaxIdleConnsPerHost: 100,
}
client = &http.Client{
Transport: transport,
}
start := time.Now()
ticker := time.NewTicker(time.Second / time.Duration(msgPerSec))
loop:
for {
select {
case <-ticker.C:
go func() {
n := atomic.AddInt64(&cnt, 1)
post(n)
}()
case <-sig:
break loop
}
}
dur := time.Now().Sub(start)
fmt.Printf("called %d times in %s %f ops/sec\n", cnt, dur, float64(cnt)/(float64(dur)/float64(time.Second)))
}
const url = "https://<GAE上のcollect エンドポイント>"
const tmpl = `[{"u" : "%[1]d-1"},{"u" : "%[1]d-2"},{"u" : "%[1]d-3"}]`
func post(n int64) {
_, err := client.Post(url, "application/json", bytes.NewBuffer([]byte(fmt.Sprintf(tmpl, n))))
if err != nil {
fmt.Println(err)
}
}
go run gun.go 100
と実行すれば、引数で指定した req/s になるようにgoroutine を起動しまくって、並列でリクエストします。
終了したときに、実際のスループットを表示します。
100req/s でしばらく様子見
本当はもっと激しく負荷テストがしたかったのですが、手元のマシンからだと、 100req/s ぐらいが限界だったので今回はこれでお茶を濁します。
また、 Pub/Sub にイベントがバッファされる様子をみるため、 Cloud Dataflow は起動せずにおきます。
約9時間ほど、寝てる間に放置してみました。
以下がGAEのアクセス履歴グラフ
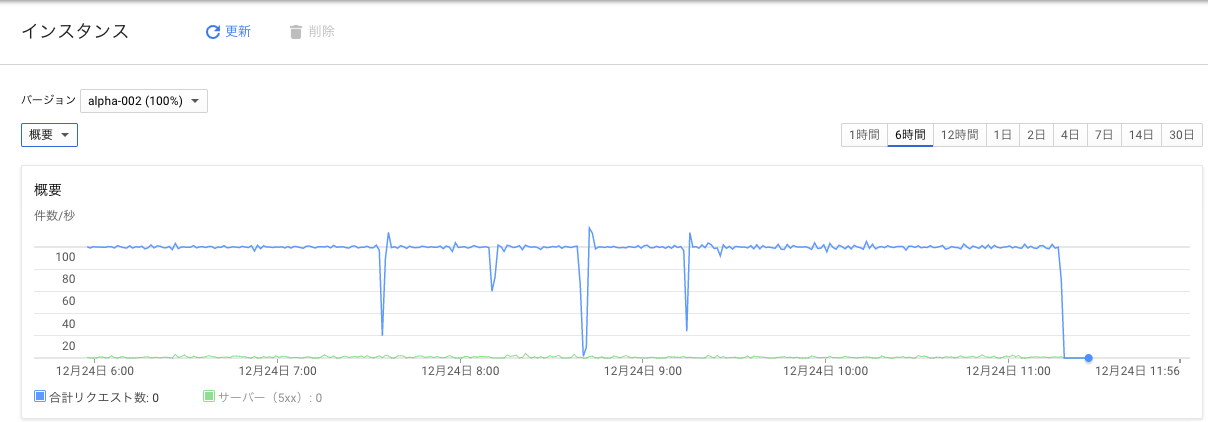
だいたい 100 req/s さばいてますが、なんか途中のグラフが変ですが、捌けてるようにみえます。
たまに、500 エラーが出ているのは、 Pub/Sub のトピックに対して、データを送るときに、rpc error: code = 13 desc = transport is closing というエラーが出ています。 gRPC クライアントが alpha リリースなので、今後に期待です。
インスタンス数の遷移
100 req/s さばいているときの、インスタンス数の遷移が以下です。
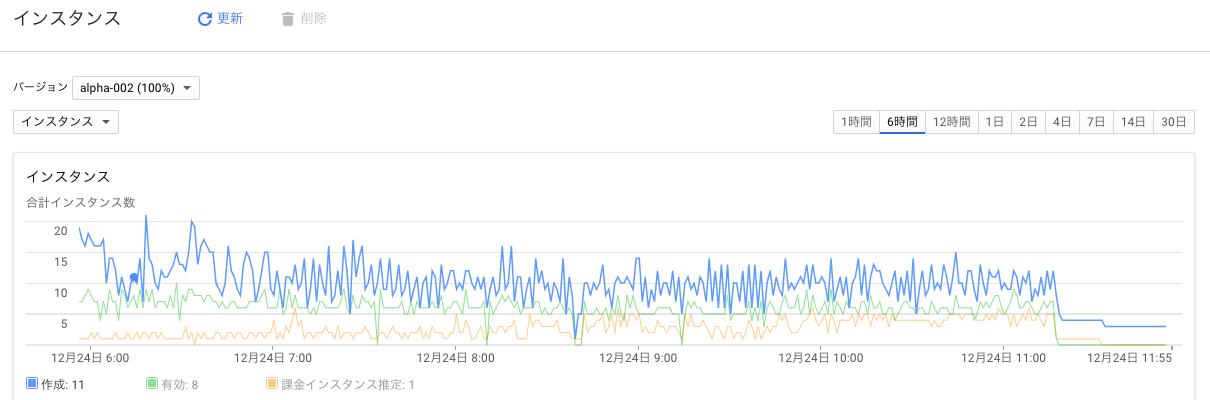
緑の線が、その時にあった有効なインスタンス数なので、だいたい、 7-8 インスタンスで捌けてるようです。
Pub/Sub メッセージ数の遷移
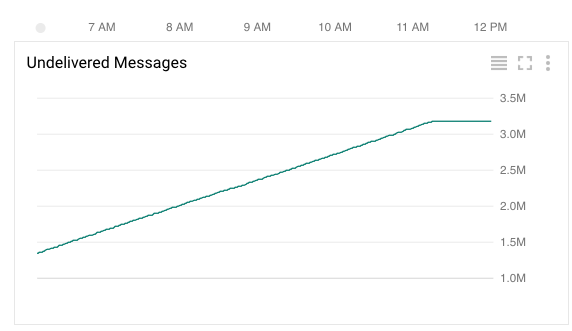
実行中の、Pub/Sub にメッセージが溜まっていく様子です。
きれいに線形に溜まっていって、320万メッセージほど溜まっています
Cloud Dataflow を起動する
Pub/Sub にメッセージが溜まったところで、これを処理する DataFlow を起動してみます。
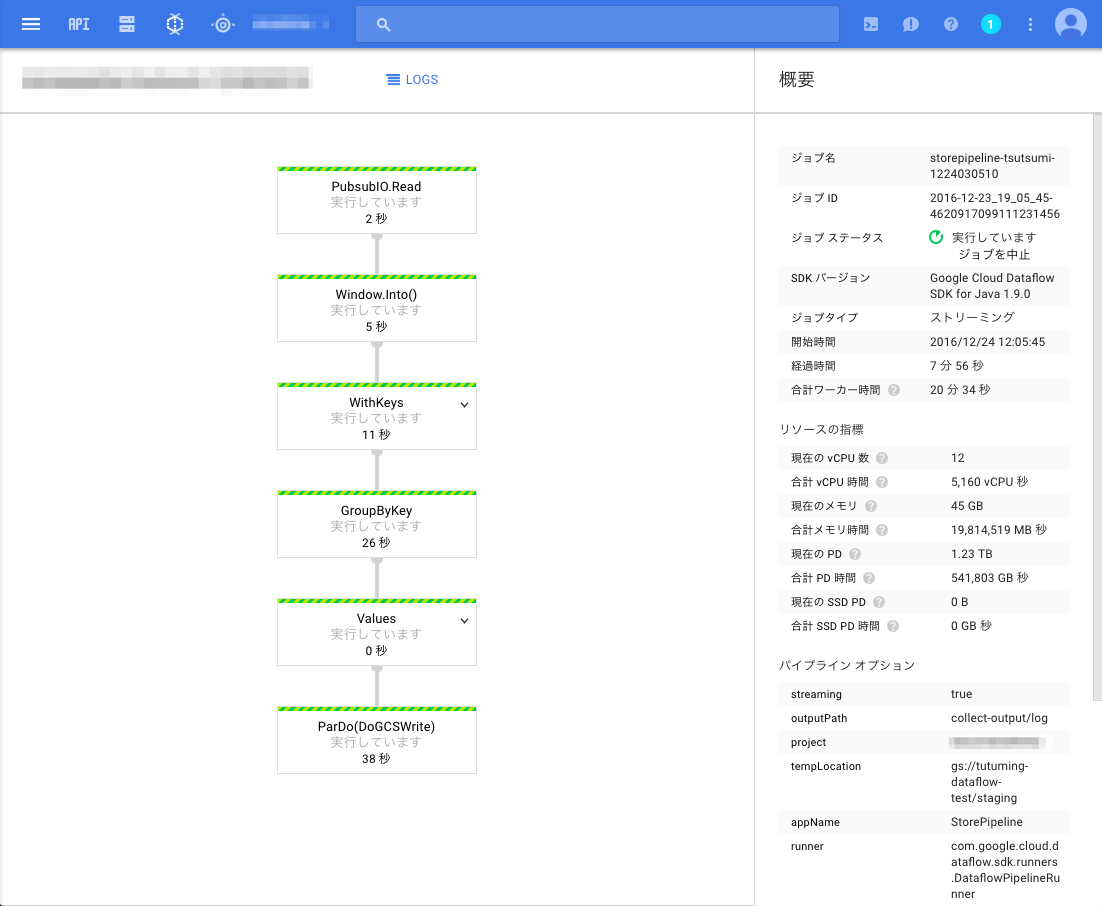
9時間分、330万メッセージを、だいたい5分ぐらいで処理できました(はやい)
このまま起動しておけば、新しく入ってきたメッセージに対しても、順次ストリーミングで処理してくれます。
5分毎のメッセージをまとめてテキストファイルにしたものが、Cloud Storage に保存されています。
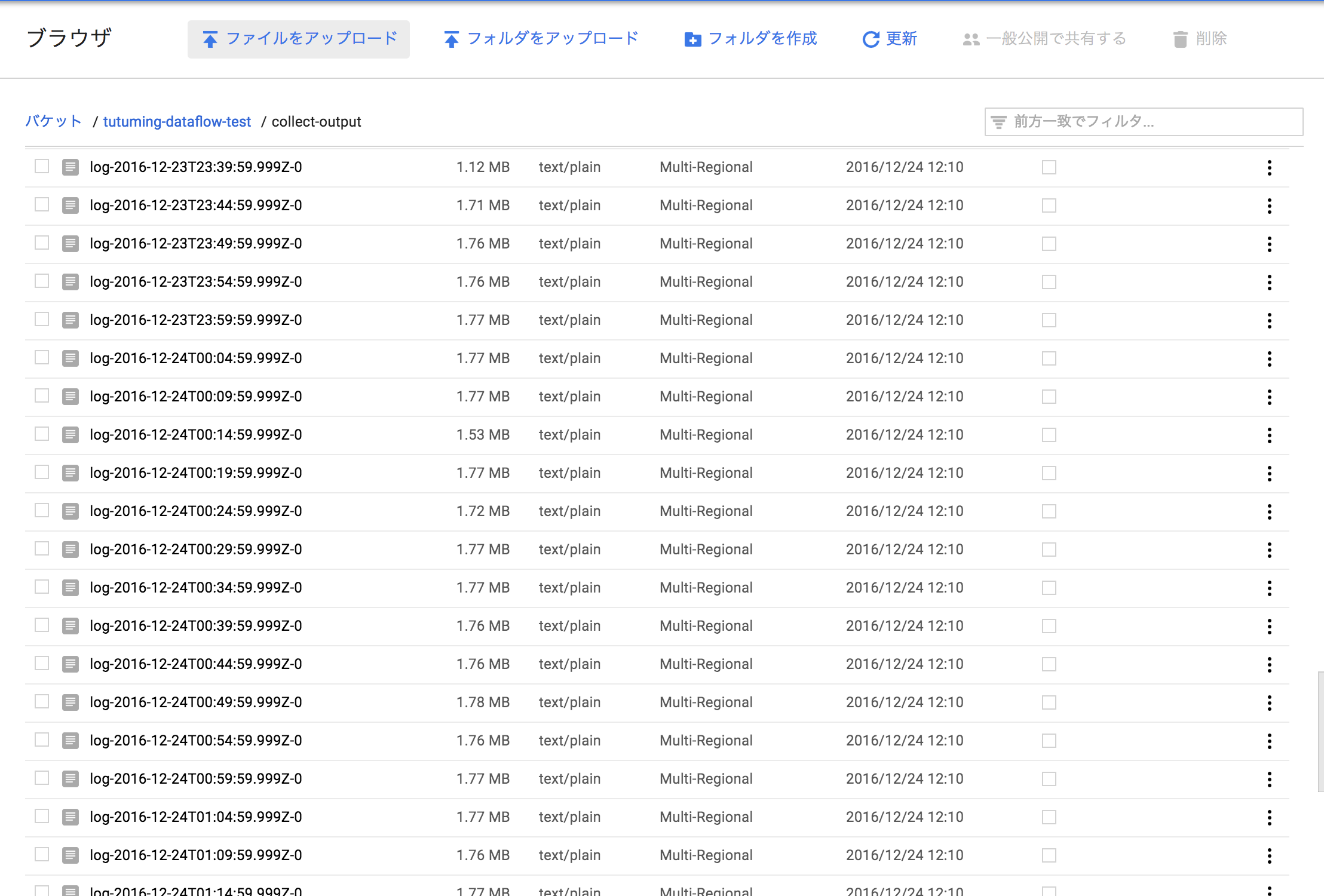
今回はペイロードが小さいので、5分間で、1.7MB ぐらいのファイルにまとまっていますね。
コスト試算
今回、 100req/s のときに必要なリソースが分かったので、目標だった、 月間50億PVをさばく際のコストを試算してみます。
App Engine
GAEは、おそらくリクエスト数に対して線形にスケールするはずなので、100 req/s の時の20倍を想定します。
8インスタンス/時間 * 20 = 160 インスタンス/時間
です、1インスタンス時間あたり、 $ 0.05 なので、
$ 0.05 * (160 * 24時間 * 30日) = $5,760
ですかね。 そんなに安くはないですね、もうちょっとインスタンスサイズなどを調整すると、安くなるかもしれません。
Cloud Dataflow
Dataflowの料金は、
https://cloud.google.com/dataflow/pricing-model
に詳細がありますが、ちょっと複雑です。
今回はストリーミングモードのデフォルトである、
CPU 4 個、メモリ 15 GB、PD 420 GB
で試しました、これが3台起動します。
今回の用途だと、秒間1万メッセージほど捌けていたので、これより多いリソースは実は必要ないはずです。
試算すると 月間
($ 0.056 * 4 + $ 0.003557 * 15 + $ 0.000054 * 420) * 24 * 30 * 3 = $ 648
です。
Cloud Pub/Sub
Cloud Pub/Sub の課金は、オペレーション単位です
https://cloud.google.com/pubsub/pricing
月間 50 億のメッセージが Pub/Sub を通過することになりますが、それぞれ、 Publish, メッセージのPull, メッセージの処理完了レスポンス 分のオペレーションがかかるので、150億オペレーション、ということになります。
最初の 17.5 億オペレーションまでは、段階的な料金が設定されており、月 $ 300 です。
残りの、 132.5 億オペレーションは、 100万オペレーションあたり、 $ 0.05 ですので
13250 * 0.05 = $662.5
です。ごうけいして、 $ 962.5 ぐらいですね
その他
Cloud Storage の料金がかかります
また、GAEからの外向きの通信にもお金がかかりますが、今回は、レスポンスを返す必要がそもそも無いので、誤差程度です。
合計
- App Engine $ 5,800
- Pub/Sub $ 960
- DataFlow $ 650
で、 月 $ 7,410 ぐらいになりそうです。
App Engine のところは、もうちょっと工夫して安くできる感じもしますが、いったん見積もりとしてはこのくらいみておくべきでしょう。
まとめ
GCP を使って、アクセス解析を作るシミュレーションとして、まずはデータを収集する部分を構築して検証しました。
今回の構成の魅力は、なんといっても、オペレーションの簡単さです。
インフラの設定などはいっさい 必要ないです。今回のプロトタイプは1日でできましたが、このままの状態でも、目標の50億PV/月 を捌けそうです (実際にはエラー処理やら、運用のことを考えないとはいけないですが)。
また全体的に、Dataflowの部分以外はアクセス数に応じて純粋な従量課金になっています。
なので、小さく始めてそのままのアーキテクチャでほぼ無限に(お金さえあれば)スケールします。
スケールが必要になる、ということはビジネスとしてうまくいっているはずなので、これは理にかなっています。
実際にこの構成がどのくらいイケてるのかは、他の手段のコスト感と比較してみないとわかりませんが、なんだかんだ、一番お金がかかるのは人件費だったりします。
サーバー費を減らすために、優秀な人の時間を消費することを考えると、そこそこ現実的な選択肢になるのではないか、と思いました。
ということで。GCP楽しそうですね!また来年!