Sparkの環境をWindows上で構築したくて
インストールしていたが、どうしてもバッチ起動でエラーになってしまったので、
対処方法をメモします。
̻■環境
Windows10 64bit
̻■インストール手順
○Apache Spark をインストールする
http://spark.apache.org/downloads.html
※バージョンは最新を取得(spark-2.1.1-bin-hadoop2.7)
tgzが解凍できるソフトで任意のディレクトリに解凍しとく
○winutils.exeのダウンロード
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
※WindowsでSparkを実行するために、Hadoopの依存関係を解決するためのexe
別のバージョンのHadoopや32bit OSを利用する場合は、当該するバージョンのwinutilsのダウンロードが必要らしい。。
今回は2.7なのでこちら。
ダウンロードがすんだら、解凍した
Apache Sparkのbin直下に配置します。
̻■環境変数
○HADOOP_HOME
ApacheSparkを解凍したディレクトリ
D:\tools\spark-2.1.1-bin-hadoop2.7\
○path追加
%HADOOP_HOME%\bin
̻■実行
今回はScalaを起動します。
Windowの32bitだと
このまま下記ファイルを管理者権限で実行すればいいみたいなんですが、
D:\tools\spark-2.1.1-bin-hadoop2.7\bin
spark-shell.cmd
※管理者として起動しないとアクセスエラーが出ます。。
64bitだとパスで怒られてなんだかうまくいかない現象が発生しました。。
調べると、javaを実行する際にパス指定がよくないことがわかったので、
下記ファイルを修正。。
D:\tools\spark-2.1.1-bin-hadoop2.7\bin
spark-class2.cmd
rem Figure out where java is.
set RUNNER=java
if not "x%JAVA_HOME%"=="x" (
set RUNNER=%JAVA_HOME%\bin\java :★ココのパスから""を除外してあげる
) else (
where /q "%RUNNER%"
if ERRORLEVEL 1 (
echo Java not found and JAVA_HOME environment variable is not set.
echo Install Java and set JAVA_HOME to point to the Java installation directory.
exit /b 1
)
)
そうすると無事起動完了!
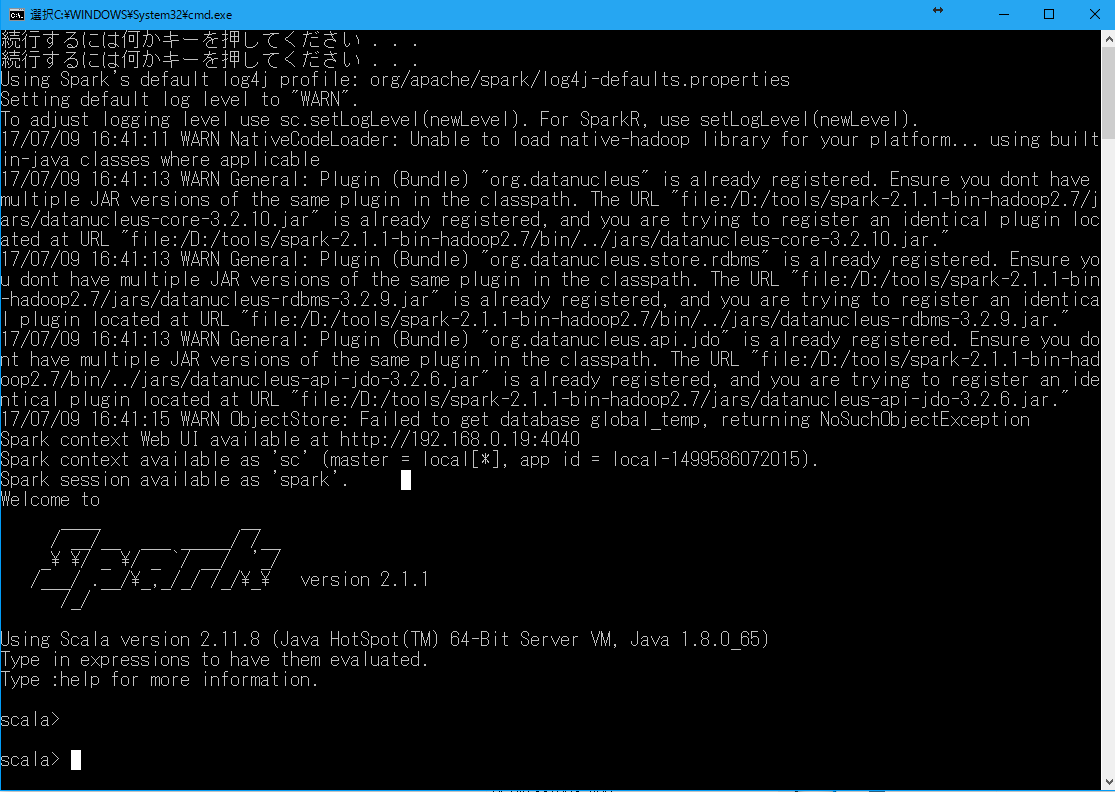
これでsparkいじれる~。
参考になれば幸いです。