PyStructを使ってHMMでラベル系列の事後確率最大推定.
準備
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from pystruct.inference import inference_dispatch
データは以下のもの.時系列データの整数化・平滑化を試す.
データ
d = '17.2 19.7 21.6 21.3 22.1 20.5 16.3 18.4 21.0 16.1 17.5 18.5 18.4 18.3 16.0 21.2 18.8 24.3 23.3 20.5 16.9 22.4 20.1 24.5 24.2 22.7 19.6 23.6 23.3 24.6 25.0 24.3 22.2 22.7 19.5 20.5 17.3 17.2 22.0 20.9 21.5 22.3 24.0 22.4 20.2 15.7 20.4 16.3 17.7 14.3 18.4 16.6 13.9 15.2 14.8 15.0 11.5 13.4 13.5 17.0 15.0 17.5 12.3 11.8 14.5 12.4 12.9 15.8 13.8 11.4 6.5 5.9 7.2 5.6 4.6 7.5 8.9 6.6 3.9 5.7 7.3 6.1 6.8 3.1 2.6 7.9 5.2 2.0 4.0 3.4 5.7 8.1 4.7 5.4 5.9 3.6 2.9 5.7 2.1 1.6 2.3 2.4 1.2 4.2 4.2 2.4 5.6 2.5 3.0 6.1 4.9 7.1 5.0 7.2 5.2 5.1 10.4 8.3 6.9 6.8 7.8 4.2 8.0 3.2 7.9 5.9 9.5 6.4 9.2 11.7 11.6 15.5 16.7'
d = np.array([ float(c) for c in d.split()])
ではHMMモデルの構築と推論の実行.
- データ項 (unary term) は (ノード数,クラス数) のndarray
- ペアワイズ項 (pairwise term) は (クラス数, クラス数) のndarray.エッジ毎に変えるなら,(エッジ数, クラス数, クラス数) のndarray(API reference manualが間違っている場所あり.注意.).
実行!
nClasses = 20 # 離散クラスの数.20
p = 10 # 隣接するノードのクラスが異なった場合のコスト.(同じなら0)
# データ項.ラベルとの差の絶対値
unaries = np.array([ [ abs(i-j) for j in range(nClasses) ] for i in d ])
# ペアワイズ項.同じラベルなら0,異なるならp
pairwise = np.array((np.ma.ones((nClasses, nClasses)) - np.eye(nClasses)) * p)
# ノードを連結するエッジの設定.HMMなので1次元.
edges = np.array([ [i, i+1] for i in range(unaries.shape[0]-1) ])
# 推論実行.この関数は最大化するので,unaryiesとpairwiseにマイナスをつける.
res = inference_dispatch(-unaries, -pairwise, edges, inference_method='max-product')
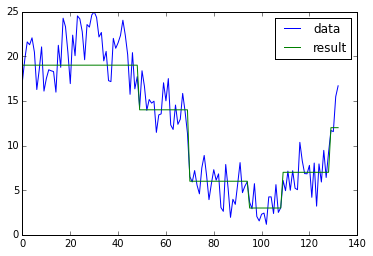
# プロット.
plt.plot(d, label="data")
plt.plot(res, label="result")
plt.legend()