Tensorflowが機械学習ライブラリという誤解がまかり通っているので,理解を深めるために平均を求めるコードを書いてみた.
- 0から100までの一様乱数を100個生成.とうぜん平均は50.
- 学習係数をいつくか変更
Gradient decent
import matplotlib.pylab as plt
%matplotlib inline
import numpy as np
import tensorflow as tf
x_train = np.random.randint(0,100, size=100)
n_itr = 100
m = tf.Variable([30.0], tf.float32) # 推定する変数
x = tf.placeholder(tf.float32) # 与えるデータ
loss = tf.reduce_sum(tf.square(x - m)) # 二乗誤差和
for lr in [0.009, 0.001, 0.0001]:
optimizer = tf.train.GradientDescentOptimizer(lr) # ベタな勾配法
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
est = []
for i in range(n_itr):
_, est_m = sess.run([train, m], {x:x_train})
est.append(est_m)
est = np.array(est)
plt.plot(est.reshape(n_itr), label="lr={}".format(lr))
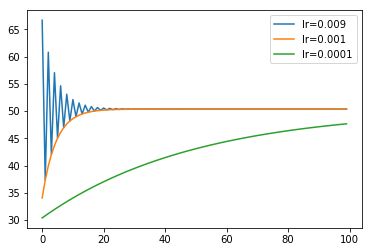
plt.title("batch gradient decent")
plt.legend()
plt.show();
真の平均に収束しているけど
- 学習係数が大きいと,とうぜん振動する
- 0.01よりも大きいと発散
- 学習係数が小さいと,収束も遅い
RMS Prop
optimizerと
学習率の範囲を変えただけ.
for lr in [5, 1, 0.1, 0.01]:
optimizer = tf.train.RMSPropOptimizer(lr)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
est = []
for i in range(n_itr):
_, est_m = sess.run([train, m], {x:x_train})
est.append(est_m)
est = np.array(est)
plt.plot(est.reshape(n_itr), label="lr={}".format(lr))
plt.title("batch RMS Prop")
plt.legend()
plt.show();
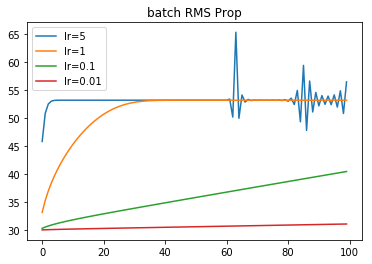
- 学習率が大きすぎると,収束した後に振動する.
- gradient decentに比べて学習率がかなり大きい
Adam
for lr in [5, 1, 0.1, 0.01]:
optimizer = tf.train.AdamOptimizer(lr)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
est = []
for i in range(n_itr):
_, est_m = sess.run([train, m], {x:x_train})
est.append(est_m)
est = np.array(est)
plt.plot(est.reshape(n_itr), label="lr={}".format(lr))
plt.title("batch Adam")
plt.legend()
plt.show();
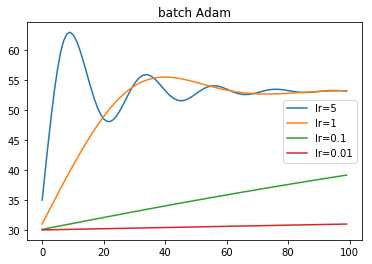
- 振動が緩やか.過渡現象の振動グラフを思い出す.
- 学習率が大きいとオーバーシュートする.
AdaGrad
for lr in [20, 10, 5, 1, 0.1, 0.01]:
optimizer = tf.train.AdagradOptimizer(lr)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
est = []
for i in range(n_itr):
_, est_m = sess.run([train, m], {x:x_train})
est.append(est_m)
est = np.array(est)
plt.plot(est.reshape(n_itr), label="lr={}".format(lr))
plt.title("batch AdaGrad")
plt.legend()
plt.show();
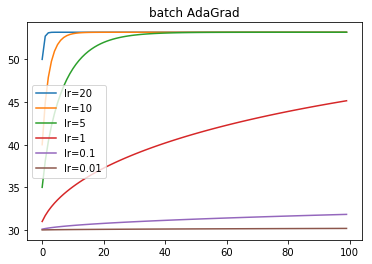
- 優秀.学習率を大きくすると良い.大きくても発散せず,急速に収束する.(100を試してみると面白い)
AdaDelta
for lr in [20000, 10000, 1000, 100, 10]:
optimizer = tf.train.AdadeltaOptimizer(lr)
train = optimizer.minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
est = []
for i in range(n_itr):
_, est_m = sess.run([train, m], {x:x_train})
est.append(est_m)
est = np.array(est)
plt.plot(est.reshape(n_itr), label="lr={}".format(lr))
plt.title("batch AdaDelta")
plt.legend()
plt.show();
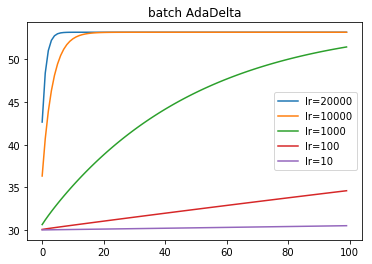
- 振る舞いはAdaGradとほとんど同じ.
- 学習率がかなり大きい.