背景
Python製のスクレイピングフレームワークであるScrapyの存在を最近知ったのですが、ちょっと触ってみた感じ最強でした。
具体的な良い所としては以下が挙げられます。
- いくつかの設定+簡潔な記述だけでスクレイピング処理が書ける
- プログラムベースなのでいざとなれば複雑な処理も書ける
- Scrapy Cloud というクラウドサービスと連携しているため、作成したクローラをコマンド一つでデプロイ&実行できる
- クラウドサービスを使えばスケールも簡単、スケジューリング機能、統計情報や監視もついている
概要と導入には以下の記事が大変参考になります。
- Scrapy + Scrapy Cloudで快適Pythonクロール+スクレイピングライフを送る - Gunosyデータ分析ブログ
- 手間をかけずに実務で使えるクローラーの作り方 - ITANDI BLOG
この記事の目的
概要と導入に関しては上記の記事で必要十分なのですが、いざ自分でいろいろやろうとしてみた時に追加で必要になるポイントをいくつかまとめました。
上記の記事にある内容はあえて書いていないため、まずそちらを読んでもらうと良いかと思います。
公式のリファレンスの該当ページの紹介と、それに補足していく形で書いています。
アーキテクチャ
フレームワークは便利ですが内部構造を知らないで使っていると非常にもやもやするので、まずは概要だけ抑えましょう。
こちらのページに概要が書かれています。
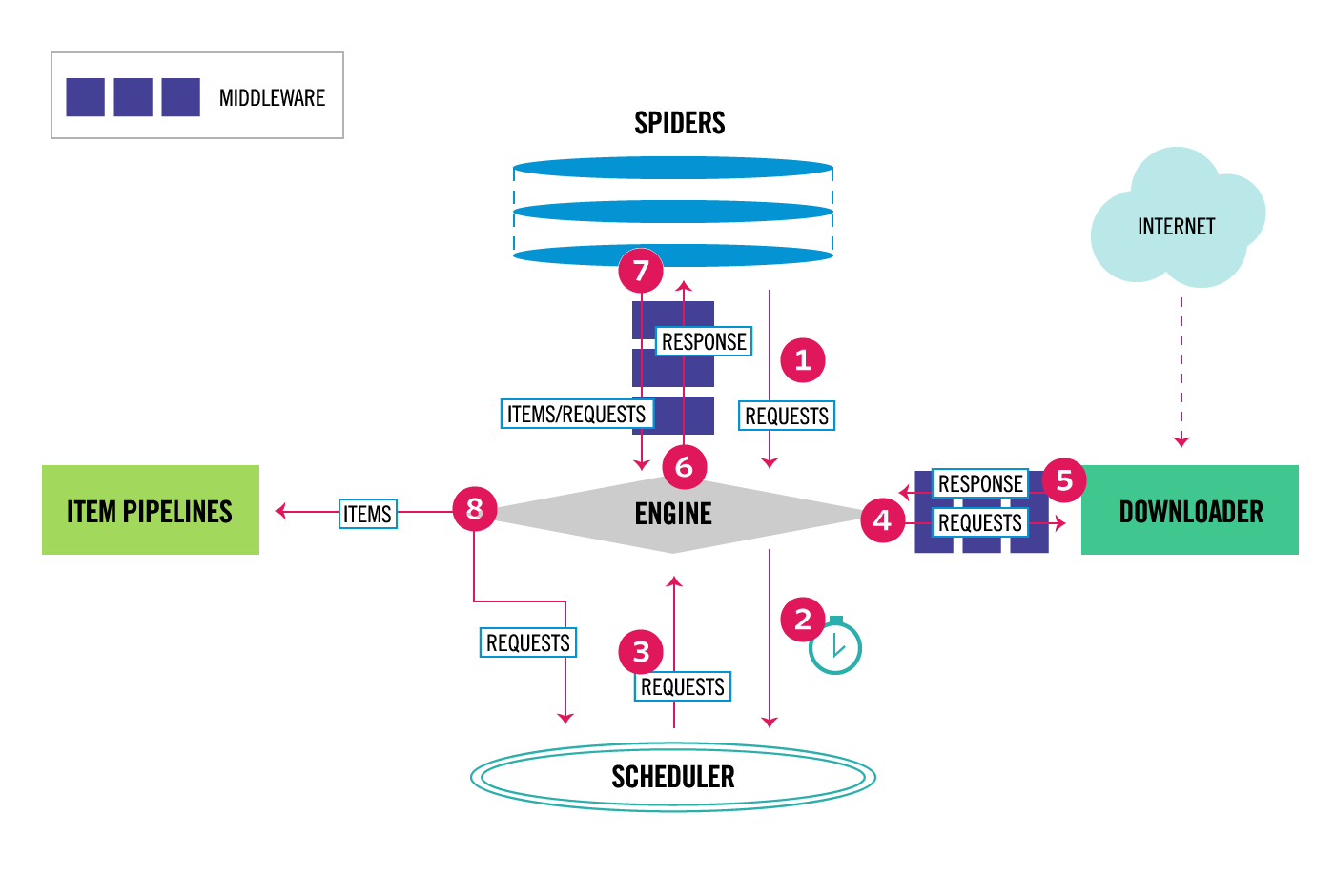
Component
Scrapy Engine
フレームワーク全体のデータ処理をコントロールする部分。
Scheduler
ページヘのリクエストをキューとして管理する部分。
scrapy.Request オブジェクト(urlとcall back関数を持つオブジェクト)を受け取ってキューに積み、Engineから要求があった時にキューを返す。
Downloader
実際のWebページヘのアクセスを行う部分。
WebページをフェッチしてきてSpiderに渡す。
Spiders
フェッチしてきたWebページのデータを処理する部分。
ユーザはこの部分の処理を自分でカスタマイズする必要がある。
書ける処理は大きく分けて下記の2種類がある
- Webページの要素からデータを抽出してItemオブジェクトに代入し、そのオブジェクトを Item Pileline に渡す
- Webページから新たにクロールしたいURLを抜き出し scrapy.Request オブジェクトを作成し、Schedulerに渡す
Item Pipeline
Spiderによって抽出されたItemのデータを処理する部分。
データクレンジング、バリデーション、ファイルやDBへの保存を行う。
Middlewares
DownloaderとSpiderの前後にMiddlewareレイヤがあるため、そこに処理を挟みこむことも出来る。
抑えておきたいこと
基本的に自分で記述するのは Spider内の処理、Itemクラスの定義、Item Pipeline用の設定、その他基本的な設定だけです。(もちろん拡張したければ他もいじれますが)
また、「Webページからデータをダウンロードしてどこかに保存し、さらに次のページを辿る」という一連の流れがコンポーネント化され非同期に処理されるような作りになっています。
ここを意識していると、Spider内で scrapy.Request オブジェクトを作成し Scrapy Engine に渡すことで次のページを指定する部分の処理が理解できます。
データフロー
全体のデータフローは以下のようになります。
- まずEngineがスタートURLを取得し、スケジューラにそのURLを持つRequestオブジェクトを渡す
- Engineがスケジューラに次のURLを聞く
- スケジューラが次のURLを返し、EngineがそれをDownloaderに渡す
- Downloaderがページのデータを取得し、ResponseオブジェクトをEngineに返す
- EngineがResponseを受け取り、それをSpiderに渡す
- Spiderがページのデータを解析し、データが入ったItemオブジェクトと次にスクレイピングするURLを持つResponseオブジェクトをEngineに返す
- Engineがそれらを受け取り、ItemオブジェクトをItem Pipelineに、Requestオブジェクトをスケジューラにそれぞれ渡す
- ステップ2から7をキューがなくなるまで繰り返す
アーキテクチャを理解していると全体の流れがすっきり理解できますね。
Selector
Scrapyではクロールしたページの要素を取得するためにCSSセレクタとXPathを使用できます。
公式リファレンスはこちら。
XPathの方が柔軟な指定ができるため、私はこちらを使っています。以下の記事、公式リファレンスが参考になります。
デバッグ方法
公式リファレンスはこちら。
Scrapy Shell
Scrapyには Scrapy Shell という便利なデバッグ機能があります。
取得したいWebページのURLを指定して Scrapy Shell を起動すると、DownloaderからのresponseなどいくつかのScrapy Objectを保持した状態でipythonが起動します。
この状態でSpider内に記述するSelectorのコードなどをデバッグできます。
% scrapy shell "https://gunosy.com/"
2016-09-05 10:38:56 [scrapy] INFO: Scrapy 1.1.2 started (bot: gunosynews)
2016-09-05 10:38:56 [scrapy] INFO: Overridden settings: {'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'gunosynews.spiders', 'DOWNLOAD_DELAY': 3, 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['gunosynews.spiders'], 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'BOT_NAME': 'gunosynews'}
---
2016-09-05 10:38:56 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-09-05 10:38:56 [scrapy] INFO: Spider opened
2016-09-05 10:38:57 [scrapy] DEBUG: Crawled (200) <GET https://gunosy.com/robots.txt> (referer: None)
2016-09-05 10:39:01 [scrapy] DEBUG: Crawled (200) <GET https://gunosy.com/> (referer: None)
## ↓Scrapy Shell内で利用できるScrapy objects
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x10ff54fd0>
[s] item {}
[s] request <GET https://gunosy.com/>
[s] response <200 https://gunosy.com/>
[s] settings <scrapy.settings.Settings object at 0x110b0ef28>
[s] spider <GunosynewsSpider 'gunosy' at 0x110d40d68>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
## ↓期待通り取得できるか確認
>>> response.xpath('//div[@class="list_title"]/*/text()').extract()
['真田丸「犬伏」に称賛殺到「すごい回」「涙止まらない」...大泉演技に感嘆の声', '10kmタマゴでカイロスが出たら泣いていいぞ!お前の歩いた10kmは無駄だったんだ!ポケモンGO1...', '「アメトーーク!」日曜ゴールデン進出 木曜深夜と異例の週2回', 'サガン鳥栖 豊田 地元学校文化祭にサプライズ登場 AKBと肝炎予防PR', 'マジプリのセンター・西岡健吾が「PON!」初の“お天気お兄さん”に「精一杯頑張ります!」', 'ベスト16進出の錦織のバックハンドに全米が注目!', 'イチロー2試合連続ヒット! 通算3016安打で歴代26位に「4」', '心晴れないKO防衛=腰痛めていた井上尚-WBO・Sフライ級', '高校日本最強投手陣は寺島、藤平ら7人がプロ志望', 'イチロー2季ぶり失策 米解説者はエースの怠慢プレーに激怒「ホセの責任」', '地球ちっぽけ過ぎ! 惑星の大きさを比較する動画での “宇宙の無限感” がヤバイ', '人気アカウント「桶川猫」がTwitterを停止。その理由がやり切れない...', 'どこで習得したの!? あらぬ方向で才能が開花した人々11選', '娘と彼氏が“イチャイチャドライブ”→ その後父親が驚きの行動に...!', '【ほわっほわ♡】小さな子猫と子犬のじゃれ合いの “あどけなさ” に、キュンキュンが止まらない!', '名門・出光の悲劇...突然に創業家が経営介入で混乱、国主導の業界再編が破綻寸前', '5日朝「大阪880万人訓練」実施 大阪にいたら音出る緊急メール受信', '16歳で、すでに“性獣”だった! 高畑裕太容疑者に「いずれ性犯罪でお縄になりそうだった」証言', '築地市場は一刻も早く移転せよ! 都民のことを思うなら答えは一つだ', '橋下徹「都議会との対決か協調か! 小池さんはそろそろ腹を括らなければならない」', 'パトロール中に撮影したカーセックス映像を外部に流出させた警官を拘束、撮影された女性は自殺―中国', '低品質の韓国ツアーに中国人旅行者の怒り噴出、日本へ―中国メディア', '中国から日本に伝わったお茶、「抹茶」として逆輸入で大人気に=中国報道', '中国の映画やドラマ、日本の影響を強く感じさせる演出に「日本すぎる!」', '米美術館が「歪曲地図」を展示、朝鮮半島まで延びる万里の長城=韓国ネット「日本もひどいが中国はさらに...', '脱ぐとすごい? 官能的な女性のカラダつきの特徴5つ', '学校の連絡網で「固定電話がない家庭」はいったい何が問題なのか?', 'そうだったのか!超意外「男性にあげてはいけないプレゼント」2つ', '触っちゃダメ! 生理中、敏感になってしまう部分4つ', '「絶望した...」海外の残念な宅配荷物の例いろいろ', '違和感ねぇ!ノンスタ井上とオカリナが顔を交換!全く違和感ないと話題に', 'サンコー、充電式で何度でも使えるエアダスター「SHUっとね」を提供開始', '指を受話器にしてスマホの通話が可能になるスマートストラップ「Sgnl」', 'AppleのSiriがMicrosoftのCortanaにあおられまくるムービー', 'Googleお役立ちテクニック - Googleドライブのファイルを整理する', '札幌駅で迷わずパッと買える!間違いのないお土産5選', '新宿で「美人すぎる弁当売り」を発見 → 400円弁当も激ウマで土日も出勤したくなるレベル!', 'ラーメン二郎の店主が本心を激白 / 一人が早く食べても他の客が遅いと意味ない「みんな頑張らないと」', '猫!猫!猫!ねこ好きさんが絶対喜ぶネコモチーフのギフト3選', 'ビールがすすむ!はんぺんとコンビーフの簡単おつまみを作ってみた', 'またしてもハマる♪新作『Six!』は大ヒット連発のチームが作った話題の落ちゲー【たった10秒で読めるゲームレビュー】', '【超厳選】Game8編集部が選ぶ今週のおすすめゲーム2選!今週は「Lost Maze」「Flip ...', '荒涼とした星を緑化していく癒やし系シミュレーションゲーム『みどりのほしぼし』【週末レビュー】', 'リリース4日で500万DLを達成した死にゲー「Mr.Jump(ミスタージャンプ)」', '最大16体の総攻撃が圧巻!RPGの醍醐味がここに極まる。『BLAZING ODYSSEY(ブレイジ...']
Parse コマンド
Spiderの実装が終わったらParseコマンドで確認しましょう。
% scrapy parse --spider=gunosy "https://gunosy.com/categories/1"
2016-09-05 10:57:26 [scrapy] INFO: Scrapy 1.1.2 started (bot: gunosynews)
2016-09-05 10:57:26 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'gunosynews.spiders', 'DOWNLOAD_DELAY': 3, 'BOT_NAME': 'gunosynews', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES':
---
'start_time': datetime.datetime(2016, 9, 5, 1, 57, 26, 384501)}
2016-09-05 10:57:30 [scrapy] INFO: Spider closed (finished)
>>> STATUS DEPTH LEVEL 1 <<<
# Scraped Items ------------------------------------------------------------
[{'subcategory': '映画',
'title': '佐々木蔵之介×深田恭子 『超高速!参勤交代 リターンズ』は「恩返し」',
'url': 'https://gunosy.com/articles/R07rY'},
{'subcategory': '芸能',
'title': '出生不明のインド人が優勝、ムチャムチャが凄い「食戟のソーマ弐ノ皿」10話',
'url': 'https://gunosy.com/articles/Rb0dc'},
{'subcategory': 'テレビ',
'title': '謎解き「あすなろ抱き」。木村拓哉から西島秀俊に繋がる線「とと姉ちゃん」132話',
'url': 'https://gunosy.com/articles/RrtZJ'},
{'subcategory': '芸能',
'title': '『はだしのゲン』と90年代クラブカルチャーを組み合わせたTシャツがやばい',
'url': 'https://gunosy.com/articles/aw7bd'},
{'subcategory': '漫画',
'title': '日本の現代史そのもの・・・「こち亀」完結に、台湾のファンからも惜別の声=台湾メディア',
'url': 'https://gunosy.com/articles/Rmd7L'},
---
{'subcategory': 'テレビ',
'title': 'アメトーーク!週2回に!!日曜ゴールデン進出',
'url': 'https://gunosy.com/articles/afncS'},
{'subcategory': '漫画',
'title': 'ちょっと“普通じゃない”女子高生たちの日常を描く『亜人ちゃんは語りたい』アニメ化決定',
'url': 'https://gunosy.com/articles/aan1a'}]
# Requests -----------------------------------------------------------------
[]
この他にもResponseの内容を直接ブラウザから確認できる Open in browser や、Loggingを追加する方法もあります。
アウトプットの指定方法
公式リファレンスはこちら。
フォーマット(json, jsonlines, xml, csv)
settings.py内のFEED_FORMATの項目を指定すればOKです。
FEED_FORMAT = 'csv'
以前はPython2しか対応されていなかったため、出力されるファイルやログ内の日本語がエンコードされてしまっていたのですが、2016年5月にScrapy/Scrapy Cloud共にPython3に対応したため、各フォーマットでエンコードされずに出力するようにScrapy自体も順次対応されていっているようです。
※2016/9/5時点ではxmlとcsv形式はユニコードのencode無し対応されているので出力ファイルの日本語がそのまま読めますが、jsonとjsonlinesは未対応なので使いたい場合は以下の記事のように自分で拡張する必要があります。
Python: Scrapy と BeautifulSoup4 を使った快適 Web スクレイピング
保存先(local, ftp, s3)
settings.py内のFEED_URIを適切に設定すればOKです。
FEED_URI = 'file:///tmp/export.csv'
S3を使う場合は追加でIDとKEYを指定する必要がありますが、とても簡単に利用できます。
FEED_URI = 's3://your-bucket-name/export.csv'
AWS_ACCESS_KEY_ID = 'YOUR_ACCESS_KEY_ID'
AWS_SECRET_ACCESS_KEY = 'YOUR_SECRET_ACCESS_KEY'
S3への保存をlocal環境で利用する場合はbotocoreもしくはbotoをインストールしてください。Scrapy Cloud には元からインストールされているようなので対応不要です。
% pip install botocore
ファイル名を動的に指定する方法
さらにファイル名を動的に指定することができます。
デフォルトでは以下の2つの変数が定義されています。
- %(time)s - gets replaced by a timestamp when the feed is being created
- %(name)s - gets replaced by the spider name
また、Spiderのコード内で定義することで自分で変数を追加することも出来ます。
デフォルトの%(time)sは日本時間ではないので、日本時間でディレクトリやファイル名を指定して出力する例を載せておきます。
# -*- coding: utf-8 -*-
import scrapy
from pytz import timezone
from datetime import datetime as dt
from gunosynews.items import GunosynewsItem
class GunosynewsSpider(scrapy.Spider):
name = "gunosy"
allowed_domains = ["gunosy.com"]
start_urls = (
'https://gunosy.com/categories/1', # エンタメ
'https://gunosy.com/categories/2', # スポーツ
'https://gunosy.com/categories/3', # おもしろ
'https://gunosy.com/categories/4', # 国内
'https://gunosy.com/categories/5', # 海外
'https://gunosy.com/categories/6', # コラム
'https://gunosy.com/categories/7', # IT・科学
'https://gunosy.com/categories/8', # グルメ
)
# For output path
# ここで動的に定義できる
now = dt.now(timezone('Asia/Tokyo'))
date = now.strftime('%Y-%m-%d')
jst_time = now.strftime('%Y-%m-%dT%H-%M-%S')
FEED_URI = 's3://your-bucket-name/%(name)s/dt=%(date)s/%(jst_time)s.csv'
FEED_FORMAT = 'csv'
AWS_ACCESS_KEY_ID = 'YOUR_ACCESS_KEY_ID'
AWS_SECRET_ACCESS_KEY = 'YOUR_SECRET_ACCESS_KEY'
Scrapy Cloud 上の環境の指定方法
python3 を指定する方法
Python3対応に関して詳しくはこちらに書かれています。
2016/9/5時点では特に指定をしないと Scrapy Cloud 上ではPython2が使用されます。
Scrapy Cloud 上でPython3で実行するためにはshub deployコマンドを実行した際に出来る scrapinghub.yml に以下の設定を追加する必要があります。
projects:
default: 99999
stacks:
default: scrapy:1.1-py3
依存パッケージを含める方法
Scrapyプロセス内でライブラリを使いたい場合は、requirements.txt に依存パッケージ名を書き、scrapinghub.yml でそれを指定する必要があります。
pytz
projects:
default: 99999
stacks:
default: scrapy:1.1-py3
requirements_file: requirements.txt
以上です。