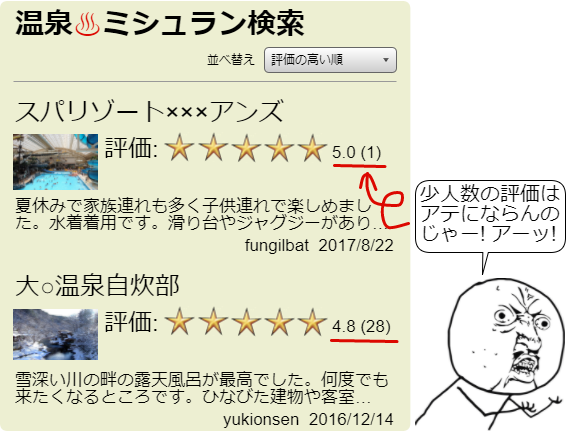
こんなことよくありません? 私、3 人以下の評価点数は考慮しないようにしているんですけど ![]() まだ少人数しかレビューしていない評価の信用が極端に低いのは直感的に分かると思いますが、ではどうすれば良いのでしょうか? 3人以上になるまで出さない? 調整して順位を落とす?
まだ少人数しかレビューしていない評価の信用が極端に低いのは直感的に分かると思いますが、ではどうすれば良いのでしょうか? 3人以上になるまで出さない? 調整して順位を落とす?
こういった評価ランキングを最尤推定と MAP 推定で考えてみましょう。なおこの画像は実在する特定のサイトのキャプチャではなく手作りです。
想定
商品ごとに1~5点のレビュー評価を付けることができて、その得点に基づいてランキングするシステムを考えます。単純に実装すれば商品ごとに評価点の算術平均 (相加平均) を計算して並び順を決めますよね。
ここで商品に付けられたレビュー数を $n$、レビューごとの評価点を $(x_1, x_2, \cdots, x_n)$ とします ($x_i \in {1,2,3,4,5}$)。算術平均での $\mu$ は以下のように表すことが出来ます。
\mu = \frac{1}{n} \sum_{i=1}^n x_i
商品に対して 1~5 までのどこかに「真の評価点」があると仮定して、ユーザレビューで付けられる評価点それぞれは「真の評価点」を平均 $\hat{\mu}$ とした正規分布に従って得点しているものとします。つまりある1つのレビューで評価に $x$ (${1,2,3,4,5}$ のいずれか) が付けられる確率は $\mu$ と分散 $\sigma^2$ をパラメータとした正規分布:
P(x| \mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} {\rm exp}\left\{\frac{(x-\mu)^2}{\sqrt{2\sigma^2}}\right\}
で得られます。さらに商品には $n$ 人のレビューが付けられています。すべて人の評価が $(x_1, x_2, \cdots, x_n)$ の組み合わせになる同時確率は:
\begin{eqnarray}
P(x_1,\cdots,x_n| \mu,\sigma^2)
& = P(x_1| \mu,\sigma^2)\times P(x_2| \mu,\sigma^2)\times \cdots \times P(x_n| \mu,\sigma^2) \\
& = \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^n {\rm exp}\left\{-\sum_{i=1}^n \frac{(x-\mu)^2}{\sqrt{2\sigma^2}}\right\}
\end{eqnarray}
で表されます (確率変数 $x$ が観測されていてパラメータの方を求めようとしている確率関数を尤度関数と呼びます)。ただこのままでは指数が含まれていてちょっと計算が面倒そうですね。
対数 $\log$ は単調増加ですので確率分布 $P$ の対数をとってもピークの位置は変わりません。必要なのは一番確率が高くなる位置の $\mu$ ですので計算の単純化のため対数をとります (これを対数尤度関数と呼びます)。
\log P(x_1,\cdots,x_n| \mu,\sigma^2) = n \log \frac{1}{\sqrt{2\pi\sigma^2}} - \sum_{i=1}^n \frac{(x-\mu)^2}{\sqrt{2\sigma^2}}
推定とは
ちょっと筆休め。確率分布はパラメータが決まればその形が決まります。例えば正規分布の場合は平均 $\mu$ と分散 $\sigma^2$ が決まれば分布が決まりますよね。一様分布は平均がパラメータ、多項分布は各区画の確率 $p_k$ と個数 $N$ がパラメータ、といったように。
確率関数は確率分布のパラメータ (分布の形) が先に決まっているところから「あるデータ $x$ が観測される確率」を表すものでした。推定はその逆で、すでに何らかのデータが観測されている状況から、そのデータの組み合わせが出現するのに一番確度の高い確率分布を決める (つまり確率分布のパラメータを求める) ことを行います。
最尤推定で解く
最尤推定 (maximum likelihood estimation; MLE) は前述の対数尤度関数 $\log P(x_1,\cdots,x_n|\mu,\sigma^2)$ が最も大きくなる位置の $\mu$ を求めます。最も高くなる位置とは極値 ─ つまり $\mu$ で微分して 0 となる位置ですね。この位置を求めてみましょう。
\frac{\partial}{\partial \mu} \left\{n\log \frac{1}{\sqrt{2\pi\sigma^2}} - \sum_{i=1}^n \frac{(x-\mu)^2}{\sqrt{2\sigma^2}}\right\} = \frac{n}{\sigma^2}\mu -\sum_{i=1}^n \frac{x_i}{\sigma^2} = 0 \\
よって
\hat{\mu}_{\rm mle} = \frac{1}{n} \sum_{i=1}^n x_i
なんと! 算術平均と同じ形になりました! そうです、我々が算術平均と言っていたのは最尤推定の観点で「観測データからするとこれが一番確度高いんじゃね?」という値だったわけです。
MAP 推定で解く
最尤推定には欠点があります。というか元々の問題に帰ってしまいますが、観測したデータ数 $n$ が小さい場合には極端にその観測値 $x_i$ にフィットしてしまう点です (つまり最尤推定は過学習 over fitting しやすいと言えます)。1人目の評価者が5をつければ ![]() 「この商品の評価は5! それ以外はありえない!」という判断になるわけですね。
「この商品の評価は5! それ以外はありえない!」という判断になるわけですね。
ここで MAP 推定 (事後確率最大化; maximum a posteriori estimation) を見てみましょう。MAP 推定はベイズ定理を利用します。
P(\mu|x_1,\cdots,x_n) = \frac{P(x_1,\cdots,x_n|\mu) P(\mu)}{P(x_1,\cdots,x_n)}
この左辺値を事後確率とよび、この値を最大化する $\mu$ を求めるのが MAP 推定です。
右辺値分子左の $P(x_i|\mu)$ は前述の尤度関数です。その右 $P(\mu)$ は事前確率、分母の $P(x_i)$ はエビデンスと呼ばれます。エビデンスはすでに観測済みの $x_i$ についての確率ですので決定済みで $P(\mu|x_i)$ を最大化する $\mu$ の算出には関与しないため無視します。すると:
P(\mu|x_1,\cdots,x_n) \propto P(x_1,\cdots,x_n|\mu) P(\mu)
最尤推定では尤度関数のみを使用しましたが、MAP 推定では 尤度関数 $\times$ 事前確率 で $\mu$ の分布も加味した式になっています。つまり
![]() 最尤推定「尤度関数で求めた $\mu$ 一択! それ以外はありえない! 考えない!」
最尤推定「尤度関数で求めた $\mu$ 一択! それ以外はありえない! 考えない!」
![]() MAP推定「同じ $\mu$ でもサンプル数 1 と 100 では信憑が違うはず。その確かさを表す分布も考慮しよう」
MAP推定「同じ $\mu$ でもサンプル数 1 と 100 では信憑が違うはず。その確かさを表す分布も考慮しよう」
というちょっとした、だけどとても大きな違いの 1 歩。
さて、正規分布の尤度関数は前述の通りです。$P(\mu)$ は正規分布の共役事前分布である正規分布とします (共役分布が何であるかは長くなるので省略)。
P(\mu) = {\rm Norm}(\mu_\mu=0, \sigma_\mu^2) = \frac{1}{\sqrt{2\pi\sigma_\mu^2}} {\rm exp}\left\{-\frac{\mu^2}{2\sigma_\mu^2}\right\} \\
\log P(\mu) = - \log \sqrt{2\pi\sigma_\mu^2} - \frac{\mu^2}{2\sigma_\mu^2}
上記を適用した $\log P(x_i|\mu) P(\mu) = \log P(x_i|\mu) + \log P(\mu)$ を最大化する $\mu$ が求めるべき $\hat{\mu}_{\rm map}$ です。
\hat{\mu}_{\rm map} = {\rm argmax}\left\{
n\log \frac{1}{\sqrt{2\pi\sigma^2}} - \sum_{i=1}^n \frac{(x_i-\mu)^2}{2\sigma^2} - \log\sqrt{2\pi\sigma_\mu^2} - \frac{\mu^2}{2\sigma_\mu^2}
\right\}
ゴッツい式ですが最大値となる $\mu$ の位置を求めるだけなので、以下の式が最小となる $\mu$ を求めることと等しくなります。
\hat{\mu}_{\rm map} = {\rm argmin}\left\{
\frac{\mu^2}{\sigma_\mu^2} + \sum_{i=1}^n \frac{(x_i-\mu)^2}{\sigma^2}
\right\}
これも極値を求める問題なので $\mu$ で微分して 0 となる $\mu$ を求めましょう。
\frac{\partial}{\partial \mu}\left\{
\frac{\mu^2}{\sigma_\mu^2} + \sum_{i=1}^n \frac{(x_i-\mu)^2}{\sigma^2}
\right\}
= -\frac{2}{\sigma^2}\left(\sum_{i=1}^n x_i - n\mu\right) + \frac{2\mu}{\sigma_\mu^2} = 0
よって
\hat{\mu}_{\rm map} = \frac{\sigma_\mu^2}{n\sigma_\mu^2 + \sigma^2} \sum_{i=1}^n x_i
おっと、算術平均ではない計算式になりましたね。長々と数式を書いてきましたがこの結論だけ見れば良いです。
ここで $\mu$ の分散 $\sigma_\mu^2$ をどう置くかですが、$x_i$ の分散 $\sigma^2$ と同様に $n$ が増えれば小さくなるように連動する想定して $\sigma_\mu^2 = \sigma^2$ とすれば以下のように表せます。
\hat{\mu}_{\rm map} \mid_{\sigma_\mu^2 = \sigma^2} = \frac{1}{n+1} \sum_{i=1}^n x_i
また $\sigma_\mu^2 \to \infty$ の極限を取ると $\hat{\mu}_{\rm mle}$ と等しくなります。
\lim_{\sigma_\mu^2 \to \infty} \hat{\mu}_{\rm map} = \frac{1}{n} \sum_{i=1}^n x_i = \hat{\mu}_{\rm mle}
正規分布の分散 $\sigma_\mu^2$ を $\infty$ にすると真っ平らな分布 ─ つまり一様分布になります。つまり最尤推定とは MAP 推定の「尤度関数 $P(x|\mu)$ $\times$ 事前確率 $P(\mu)$」で事前確率 $P(\mu)$ を一様分布 (まだ事前に分かっていることが何もない状態) と置いたケースと見なすことができます。
評価ランキングに適用する
さて MAP 推定で得られた $\hat{\mu}_{\rm map}$ から特に $\frac{1}{n+1}\sum x_i$ がどういう値になるか調べてみます。ここで評価ランキングの 1~5 を (悪い)⇄(普通)⇄(良い) となるような -1~+1 に置き換えます。
一人目が最高点 +1 を付けると $n=1, x_1=1$ より $\frac{1}{2} = 0.5$ になります。つまり最初の一人目が最高点を付けてもランキングの得点としてはまだ上位 1/4 のスコアです。3 人が +1 を付けると $n=3, x=(1,1,1)$ ですので $\frac{3}{4} = 0.75$ となり +1 に近づいてきます。逆に、最初の一人目が -1 を付けた場合は $\frac{-1}{2} = -0.5$ になります。こちらも多数が -1 を付けてゆくと -1 に近づいてゆきます。
サンプル数が少ないうちは評価値が過度に反映されず中央の(普通)に近い位置に寄っていて (これは最大エントロピー法の考えにも準じています)、サンプルが多くなるにつれ尤も正しいと思われる位置に漸近するという振る舞いは直感とも一致します。スコアの信頼度としては最尤推定に基づく算術平均よりも感覚的に妥当なのでランキングの調整に使えそうです。
レビュー人数が増えるにつれての値の収束具合を調整したい場合は $\sigma_\mu^2 = \alpha \times \sigma^2$ と置くと良いかも知れません。パラメータ $\alpha \gt 1$ とすると収束が速くなり (すぐに算術平均に近似し)、$\alpha \lt 1$ で収束が遅くなります (中央に強く粘着します)。
ところで ![]()
今回、確率変数 $x_i$ が従う分布に正規分布を使用しましたが、モデルの分布としては二項分布の方が近い気がします。つまり「ある商品に対するユーザレビュー = コイントスを 4 回行ってもらって表が出た回数 + 1」を評価点とするモデルです (二項分布は極限で正規分布に近似します)。この場合、共役事前分布はベータ分布になりますので同じように数式を解いてみてください。