はじめに
Apache Spark勉強用に、Windows上にSpark環境作ってアプリケーション(とりあえずScala)を作成/コンパイル/実行する、という所までやってみます。
色々眺めていると開発環境としてはIntelliJ, Eclipseあたりが主流なようです。あとはJupyter Notebook? 合わせてビルドツールとしてsbt, mavenなどが使われたりするようです。が、素人には初モノの要素が盛りだくさんすぎてアワアワしはじめたので、最低限sbtだけ使ってまずは動かす所までの手順を整理しておきます。
環境構築
Apache Sparkのインストール
この辺の記事を参考にSparkをインストールします。
Sparkアプリケーションの基本と、はじめに押さえておきたい重要な概念
まずはApacheのサイトからダウンロード。
https://spark.apache.org/downloads.html
2017年2月時点では2.1.0が最新ですが、ターゲットとする環境の都合により、2.0.2を使いたいので、Sparkのバージョンは2.0.2を選択してtgzファイルをダウンロードします。
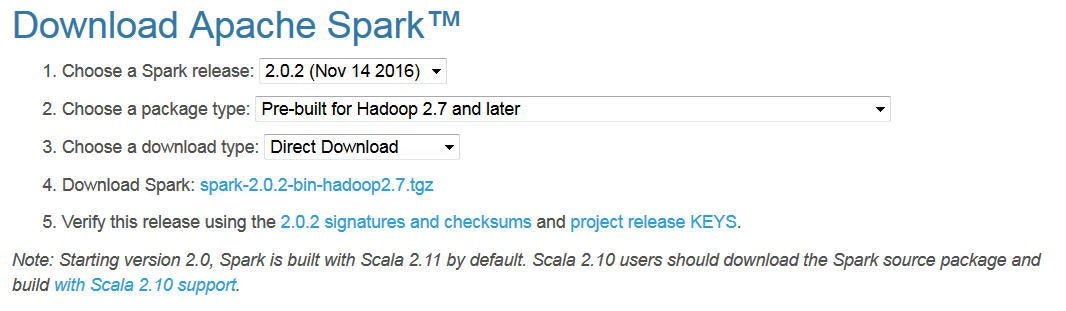
7zipなどを使って、配置先のフォルダにtgzを展開します。
(例えば、C:\x\spark-2.0.2-bin-hadoop2.7\に展開します)
先のリンク先の記事に従って、以下からwinutils.exeをダウンロードします。
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
ダウンロードしたwinutils.exeは、Sparkインストール先\binに配置します。
(C:\x\spark-2.0.2-bin-hadoop2.7\bin\winutils.exe)
環境変数設定
以下の環境変数を設定しておくとよいでしょう。
- PATH: Sparkインストール先\bin(c:C:\x\spark-2.0.2-bin-hadoop2.7\bin)を追加
- HADOOP_HOME: Sparkインストール先 (C:\x\spark-2.0.2-bin-hadoop2.7)
動作確認
インストールの確認用に、spark shellを動かしてみます。
コマンド・プロンプトを開いて、spark-shellを実行します。
c:\>spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
17/02/02 14:35:12 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java cl
asses where applicable
17/02/02 14:35:13 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.47.1:4040
Spark context available as 'sc' (master = local[*], app id = local-1486013713576).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
spark-shellが起動しました。
簡単なコードを実行してみます。
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@240a2619
scala> val test=sc.parallelize(List("str01","str02","str03","str04","str05"))
test: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> test.take(3).foreach(println)
str01
str02
str03
spark-shell起動時に「Spark context Web UI available at http://192.168.47.1:4040 」というメッセージがでています。このアドレスにブラウザからアクセスすると、Web UIにて状況確認等行うことができます。
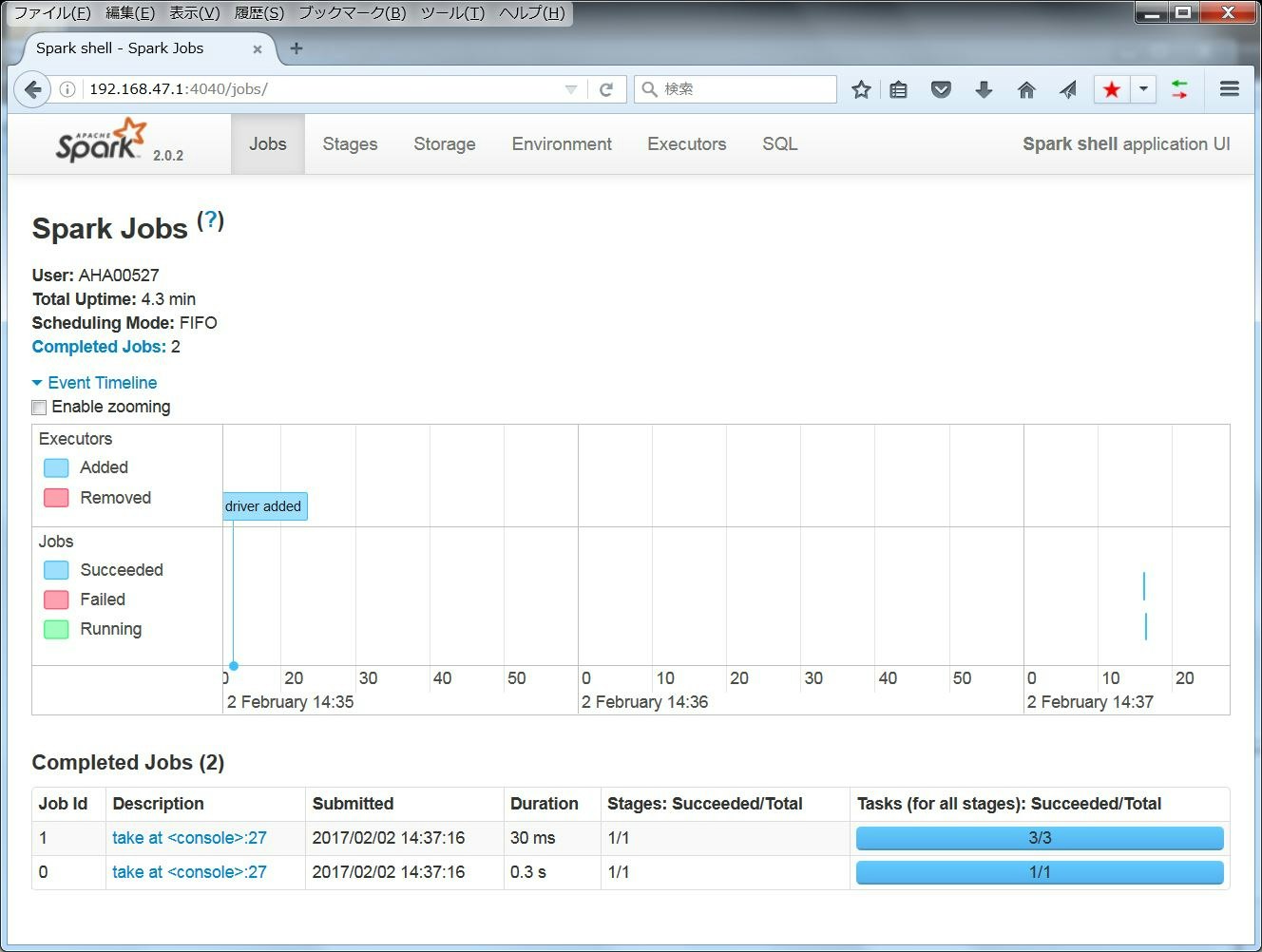
一通り動いているようなので、一旦spark-shellは 「:quit」で抜けます。
sbtのインストール
スタンド・アローンのアプリケーションとしてSparkのコードを動かしたいので、そのためのビルドツールをインストールします。ここではビルドツールとしてsbtを使うことにします。
参考: sbt
上のサイトからは見つけられなかったが、sbtというのは噂によるとsimple build toolの略らしい。
インストールの手順はこちらを参考に。
http://www.scala-sbt.org/release/docs/Manual-Installation.html
Windowsの場合、Cygwinを使う方法と使わない方法があるらしいが、ここではCygwin使わない方法を選択します。
インストールとは言っても、sbt-launch.jar をココからダウンロードして、同じフォルダに以下のバッチを作成するだけです。
set SCRIPT_DIR=%~dp0
java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M -jar "%SCRIPT_DIR%sbt-launch.jar" %*
例えば、sbt.bat, sbt-launch.jarを、c:\sbt\bin に配置して、このパスをPATH環境変数に追加すればOKです。
動作確認
コマンド・プロンプトから、sbt aboutコマンドを実行してみます。
C:\Users\IBM_ADMIN>sbt about
C:\Users\IBM_ADMIN>set SCRIPT_DIR=C:\x\sbt\bin\
C:\Users\IBM_ADMIN>java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M -jar "C:\x\sbt\bin\
sbt-launch.jar" about
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] Set current project to ibm_admin (in build file:/C:/Users/IBM_ADMIN/)
[info] This is sbt 0.13.13
[info] The current project is {file:/C:/Users/IBM_ADMIN/}ibm_admin 0.1-SNAPSHOT
[info] The current project is built against Scala 2.10.6
[info] Available Plugins: sbt.plugins.IvyPlugin, sbt.plugins.JvmPlugin, sbt.plugins.CorePlugin, sbt.plugins.JUnitXmlRepo
rtPlugin, sbt.plugins.Giter8TemplatePlugin
[info] sbt, sbt plugins, and build definitions are using Scala 2.10.6
バージョン情報などが確認できればOKです。
サンプル・アプリケーション
アプリケーション作成
以下の記述を参考に、サンプル・アプリケーションを作成して動かしてみます。
Quick Start - Self-Contained Applications
sbtを使う場合、フォルダの構造にある程度縛りがあるようなので、事前に規則に従ったフォルダ構造を作っておきます。
適当なフォルダ(ここではscala-test01)を作成して、その配下に以下のようなフォルダを作ります。
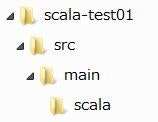
scala-test01\src\main\scala\に、ソースを作成します。(上のQuick Startのリンク先にあるソースのサンプルをコピーして、logFileの指定部分だけ修正。)
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "testData01/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
sc.stop()
}
}
testData01/README.md ファイルを読み込むようにしているので、このパスにファイルを配置します。
(scala-test01\testData01フォルダを作成して、Spark導入時に提供されるREMADME.mdファイルをコピーします。)
scala-test01\に、sbtファイルを作成します。
name := "SimpleProject01"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.2"
ディレクトリ、ファイルの構造を確認すると以下のようになっています。
c:\y\temp\Spark\scala-test01>dir /s
ドライブ C のボリューム ラベルがありません。
ボリューム シリアル番号は A8F7-9750 です
c:\y\temp\Spark\scala-test01 のディレクトリ
2017/02/02 16:21 <DIR> .
2017/02/02 16:21 <DIR> ..
2017/02/02 16:12 144 simple.sbt
2017/02/02 15:20 <DIR> src
2017/02/02 16:19 <DIR> testData01
1 個のファイル 144 バイト
c:\y\temp\Spark\scala-test01\src のディレクトリ
2017/02/02 15:20 <DIR> .
2017/02/02 15:20 <DIR> ..
2017/02/02 15:20 <DIR> main
0 個のファイル 0 バイト
c:\y\temp\Spark\scala-test01\src\main のディレクトリ
2017/02/02 15:20 <DIR> .
2017/02/02 15:20 <DIR> ..
2017/02/02 15:20 <DIR> scala
0 個のファイル 0 バイト
c:\y\temp\Spark\scala-test01\src\main\scala のディレクトリ
2017/02/02 15:20 <DIR> .
2017/02/02 15:20 <DIR> ..
2017/02/02 16:21 643 SimpleApp.scala
1 個のファイル 643 バイト
c:\y\temp\Spark\scala-test01\testData01 のディレクトリ
2017/02/02 16:19 <DIR> .
2017/02/02 16:19 <DIR> ..
2016/11/08 10:58 3,828 README.md
1 個のファイル 3,828 バイト
ファイルの総数:
3 個のファイル 4,615 バイト
14 個のディレクトリ 65,465,180,160 バイトの空き領域
コンパイル
scala-test01\に移動し、sbt packageコマンドでコンパイルします。
c:\y\temp\Spark\scala-test01>sbt package
c:\y\temp\Spark\scala-test01>set SCRIPT_DIR=C:\x\sbt\bin\
c:\y\temp\Spark\scala-test01>java -Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M -jar "C:\
x\sbt\bin\sbt-launch.jar" package
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] Set current project to SimpleProject01 (in build file:/C:/y/temp/Spark/scala-test01/)
[info] Updating {file:/C:/y/temp/Spark/scala-test01/}scala-test01...
[info] Resolving jline#jline;2.12.1 ...
[info] Done updating.
[info] Compiling 1 Scala source to C:\y\temp\Spark\scala-test01\target\scala-2.11\classes...
[info] Packaging C:\y\temp\Spark\scala-test01\target\scala-2.11\simpleproject01_2.11-1.0.jar ...
[info] Done packaging.
[success] Total time: 19 s, completed 2017/02/02 16:35:36
1度目は必要なファイルが色々ダウンロードされるので時間がかかるかもしれません。
target\scala-2.11\simpleproject01_2.11-1.0.jar にコンパイルされた結果のjarが生成されます。
実行
コンパイルされたアプリケーションを実行してみます。
Sparkのアプリケーションを実行する際は、Spark提供のspark-submitコマンドを使います。
c:\y\temp\Spark\scala-test01>spark-submit --class SimpleApp --master local[*] target\scala-2.11\simpleproject01_2.11-1.0
.jar
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/02/02 16:47:51 INFO SparkContext: Running Spark version 2.0.2
17/02/02 16:47:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java cl
asses where applicable
17/02/02 16:47:52 INFO SecurityManager: Changing view acls to: AHA00527
17/02/02 16:47:52 INFO SecurityManager: Changing modify acls to: AHA00527
17/02/02 16:47:52 INFO SecurityManager: Changing view acls groups to:
17/02/02 16:47:52 INFO SecurityManager: Changing modify acls groups to:
17/02/02 16:47:52 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view per
missions: Set(AHA00527); groups with view permissions: Set(); users with modify permissions: Set(AHA00527); groups with
modify permissions: Set()
17/02/02 16:47:52 INFO Utils: Successfully started service 'sparkDriver' on port 57316.
17/02/02 16:47:52 INFO SparkEnv: Registering MapOutputTracker
17/02/02 16:47:52 INFO SparkEnv: Registering BlockManagerMaster
17/02/02 16:47:52 INFO DiskBlockManager: Created local directory at C:\Users\IBM_ADMIN\AppData\Local\Temp\blockmgr-68343
452-a98d-4f76-af91-3554f86d5fff
17/02/02 16:47:52 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
17/02/02 16:47:53 INFO SparkEnv: Registering OutputCommitCoordinator
17/02/02 16:47:53 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/02/02 16:47:53 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.47.1:4040
17/02/02 16:47:53 INFO SparkContext: Added JAR file:/c:/y/temp/Spark/scala-test01/target/scala-2.11/simpleproject01_2.11
-1.0.jar at spark://192.168.47.1:57316/jars/simpleproject01_2.11-1.0.jar with timestamp 1486021673260
17/02/02 16:47:53 INFO Executor: Starting executor ID driver on host localhost
17/02/02 16:47:53 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on
port 57337.
17/02/02 16:47:53 INFO NettyBlockTransferService: Server created on 192.168.47.1:57337
17/02/02 16:47:53 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.47.1, 57337)
17/02/02 16:47:53 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.47.1:57337 with 366.3 MB RAM, Block
ManagerId(driver, 192.168.47.1, 57337)
17/02/02 16:47:53 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.47.1, 57337)
17/02/02 16:47:54 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 236.5 KB, free 366.1 MB
)
17/02/02 16:47:54 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.9 KB, free 366
.0 MB)
17/02/02 16:47:54 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.47.1:57337 (size: 22.9 KB, free:
366.3 MB)
17/02/02 16:47:54 INFO SparkContext: Created broadcast 0 from textFile at SimpleApp.scala:11
17/02/02 16:47:54 INFO FileInputFormat: Total input paths to process : 1
17/02/02 16:47:54 INFO SparkContext: Starting job: count at SimpleApp.scala:12
17/02/02 16:47:54 INFO DAGScheduler: Got job 0 (count at SimpleApp.scala:12) with 2 output partitions
17/02/02 16:47:54 INFO DAGScheduler: Final stage: ResultStage 0 (count at SimpleApp.scala:12)
17/02/02 16:47:54 INFO DAGScheduler: Parents of final stage: List()
17/02/02 16:47:54 INFO DAGScheduler: Missing parents: List()
17/02/02 16:47:54 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[2] at filter at SimpleApp.scala:12), whi
ch has no missing parents
17/02/02 16:47:54 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.1 KB, free 366.0 MB)
17/02/02 16:47:54 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1892.0 B, free 36
6.0 MB)
17/02/02 16:47:54 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.47.1:57337 (size: 1892.0 B, free:
366.3 MB)
17/02/02 16:47:54 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1012
17/02/02 16:47:54 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[2] at filter at Sim
pleApp.scala:12)
17/02/02 16:47:54 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
17/02/02 16:47:54 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0, PROCESS_LOCAL, 540
8 bytes)
17/02/02 16:47:54 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, partition 1, PROCESS_LOCAL, 540
8 bytes)
17/02/02 16:47:54 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
17/02/02 16:47:54 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
17/02/02 16:47:54 INFO Executor: Fetching spark://192.168.47.1:57316/jars/simpleproject01_2.11-1.0.jar with timestamp 14
86021673260
17/02/02 16:47:54 INFO TransportClientFactory: Successfully created connection to /192.168.47.1:57316 after 28 ms (0 ms
spent in bootstraps)
17/02/02 16:47:54 INFO Utils: Fetching spark://192.168.47.1:57316/jars/simpleproject01_2.11-1.0.jar to C:\Users\IBM_ADMI
N\AppData\Local\Temp\spark-223955fa-cadd-4f8b-81a9-29404e141304\userFiles-7459d042-01ce-4726-81a6-6380c7349084\fetchFile
Temp9218846672522341371.tmp
17/02/02 16:47:55 INFO Executor: Adding file:/C:/Users/IBM_ADMIN/AppData/Local/Temp/spark-223955fa-cadd-4f8b-81a9-29404e
141304/userFiles-7459d042-01ce-4726-81a6-6380c7349084/simpleproject01_2.11-1.0.jar to class loader
17/02/02 16:47:55 INFO HadoopRDD: Input split: file:/c:/y/temp/Spark/scala-test01/testData01/README.md:0+1914
17/02/02 16:47:55 INFO HadoopRDD: Input split: file:/c:/y/temp/Spark/scala-test01/testData01/README.md:1914+1914
17/02/02 16:47:55 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
17/02/02 16:47:55 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
17/02/02 16:47:55 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
17/02/02 16:47:55 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
17/02/02 16:47:55 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
17/02/02 16:47:55 INFO MemoryStore: Block rdd_1_1 stored as values in memory (estimated size 5.7 KB, free 366.0 MB)
17/02/02 16:47:55 INFO MemoryStore: Block rdd_1_0 stored as values in memory (estimated size 5.5 KB, free 366.0 MB)
17/02/02 16:47:55 INFO BlockManagerInfo: Added rdd_1_1 in memory on 192.168.47.1:57337 (size: 5.7 KB, free: 366.3 MB)
17/02/02 16:47:55 INFO BlockManagerInfo: Added rdd_1_0 in memory on 192.168.47.1:57337 (size: 5.5 KB, free: 366.3 MB)
17/02/02 16:47:55 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1676 bytes result sent to driver
17/02/02 16:47:55 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1676 bytes result sent to driver
17/02/02 16:47:55 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 421 ms on localhost (1/2)
17/02/02 16:47:55 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 390 ms on localhost (2/2)
17/02/02 16:47:55 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/02/02 16:47:55 INFO DAGScheduler: ResultStage 0 (count at SimpleApp.scala:12) finished in 0.437 s
17/02/02 16:47:55 INFO DAGScheduler: Job 0 finished: count at SimpleApp.scala:12, took 0.630785 s
17/02/02 16:47:55 INFO SparkContext: Starting job: count at SimpleApp.scala:13
17/02/02 16:47:55 INFO DAGScheduler: Got job 1 (count at SimpleApp.scala:13) with 2 output partitions
17/02/02 16:47:55 INFO DAGScheduler: Final stage: ResultStage 1 (count at SimpleApp.scala:13)
17/02/02 16:47:55 INFO DAGScheduler: Parents of final stage: List()
17/02/02 16:47:55 INFO DAGScheduler: Missing parents: List()
17/02/02 16:47:55 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[3] at filter at SimpleApp.scala:13), whi
ch has no missing parents
17/02/02 16:47:55 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.1 KB, free 366.0 MB)
17/02/02 16:47:55 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1897.0 B, free 36
6.0 MB)
17/02/02 16:47:55 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.47.1:57337 (size: 1897.0 B, free:
366.3 MB)
17/02/02 16:47:55 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1012
17/02/02 16:47:55 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (MapPartitionsRDD[3] at filter at Sim
pleApp.scala:13)
17/02/02 16:47:55 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
17/02/02 16:47:55 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, partition 0, PROCESS_LOCAL, 540
8 bytes)
17/02/02 16:47:55 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, localhost, partition 1, PROCESS_LOCAL, 540
8 bytes)
17/02/02 16:47:55 INFO Executor: Running task 0.0 in stage 1.0 (TID 2)
17/02/02 16:47:55 INFO Executor: Running task 1.0 in stage 1.0 (TID 3)
17/02/02 16:47:55 INFO BlockManager: Found block rdd_1_0 locally
17/02/02 16:47:55 INFO BlockManager: Found block rdd_1_1 locally
17/02/02 16:47:55 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 875 bytes result sent to driver
17/02/02 16:47:55 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 867 bytes result sent to driver
17/02/02 16:47:55 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 32 ms on localhost (1/2)
17/02/02 16:47:55 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 32 ms on localhost (2/2)
17/02/02 16:47:55 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
17/02/02 16:47:55 INFO DAGScheduler: ResultStage 1 (count at SimpleApp.scala:13) finished in 0.032 s
17/02/02 16:47:55 INFO DAGScheduler: Job 1 finished: count at SimpleApp.scala:13, took 0.071460 s
Lines with a: 61, Lines with b: 27
17/02/02 16:47:55 INFO SparkUI: Stopped Spark web UI at http://192.168.47.1:4040
17/02/02 16:47:55 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/02/02 16:47:55 INFO MemoryStore: MemoryStore cleared
17/02/02 16:47:55 INFO BlockManager: BlockManager stopped
17/02/02 16:47:55 INFO BlockManagerMaster: BlockManagerMaster stopped
17/02/02 16:47:55 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/02/02 16:47:55 INFO SparkContext: Successfully stopped SparkContext
17/02/02 16:47:55 INFO ShutdownHookManager: Shutdown hook called
17/02/02 16:47:55 INFO ShutdownHookManager: Deleting directory C:\Users\IBM_ADMIN\AppData\Local\Temp\spark-223955fa-cadd
-4f8b-81a9-29404e141304
--classオプションでは実行するクラス名を指定します。
--masterオプションでは実行環境を指定します。(local[*]の場合、ローカルモードでスレッド数はCPUのコア数)
最後にコンパイルして生成されたjarファイルを指定しています。
出力結果はINFOのメッセージがたくさん出ていて見にくいですが、最後から10行目くらいに、「Lines with a: 61, Lines with b: 27」という行が出力されています。
これが、プログラムで集計した結果を出力している部分です。
(読み込んだテキストファイルから、"a"を含む行数と、"b"を含む行数をカウントして出力しています。)
これで一通りアプリケーションを動かす所まで確認できました。
おわりに
プロジェクトの管理とかデバッグとか開発ツールを使ってスマートにやりたいのですが、IntelliJにしろEclipseにしろJupyter Notebookにしろ、なかなかローカルに環境を作ろうとしても一筋縄ではいかないことが多く、ちょっとハードルが高い感じです。開発環境として何をどう整備するのがよいのか今ひとつ自分なりの正解が見つけられていません。その辺は悩みながらぼちぼちやっていこうと思います。