はじめに
Azure Data LakeというAzureのBigData系サービスがプレビューとなり、一部で話題となっていたので使ってみました。Azure Data Lakeのコンセプトは、
Bringing Big Data for everybody
だそうで、これは直訳すると
「Big Dataを誰でも使えるようにする」
なんですが、
もう少し補足していうと
使い方をめちゃ簡単にして、誰でもBig Dataを使えるようにする
といった内容です。
大事なポイントは
使い方が簡単
というところ。
Big Dataがこれを使って簡単に扱えそうなので、
いろいろ大変なHadoopは学ぶ必要はもうないんじゃないかと思えてきました。
Azure Data Lakeの裏側はHadoop系技術なのでHadoopは間接的に使うのですが、
使う側のエンジニアとしては意識しなくていいんじゃなかろうかと。
Big Dataを扱う際に障壁となること
Big Dataを扱うということは、
大量ノード(サーバー)で分散処理を行い、高いスケーラビリティを持つ必要があるということであり、
それを実現するテクノロジーとしてHadoop関連技術がデファクトスタンダードになっています。
そのため、私もせっせとHadoopを勉強し、利用してきました。
しかし、Hadoopを使い始めるのって障壁が大きいなーって感じています。
スキル習得が難しい
「コスト面」や「技術的難易度の面」で、スキル習得の難易度が高いなーって思います。
コスト面での問題は、学ぶための環境を用意するのが大変すぎる!ってことです。
Hadoopを使うには最低3台くらいのハイスペックマシンがいるので、
AzureでHDInsight (HadoopのAzure版)を組んだとしても
最低価格で月20万円くらいになってしまいます。
勉強する時だけAzureに環境を作って使うとか工夫して、コストを抑え利用していくのですが、
毎回インスタンス作るのに、30分以上かかってイライラして集中が途切れ、やる気がなくなってしまいます。
※たぶんマネージャの人から見たら、「30分くらい待てよ!」思うかもしれないですが、
エンジニア的にはそんなに待たされたら違うことやり出して戻ってこれないのではないでしょうか。僕だけかな。
またOnPremiseでやろうとしたらマシン調達から考えて、時間と手間がかかりすぎて、
なかなか始められないですよね。
次に技術的難易度の面としてですが、
HadoopはLinuxネイティブなので、Linux知らない人には学びにくいように感じます。
あとPythonとBashとかWindows系エンジニアに馴染みが比較的薄い言語は、
Windows系エンジニアには少し遠く感じてしまいますね。
Azure Data Lake ってどういうもの?
Azure Data Lake には大きく二つの機能があります。
・Data Lake Store
・Data Lake Analysis
Storeの方はHDFSのストレージで、ポイントは「置けるデータ量がNo Limit」ってところですね。
あとAzure AD認証できるとかいろいろ機能がありますが、驚きの機能はなかったので割愛します。
驚きだったのはAnalysisの方です。
使う側からの視点で手順を書きますが、以下のように使います。
手順① Data Lakeのサービスを追加する
手順② 「Add DataSource」でデータのInputとOutputで使うストレージを設定する
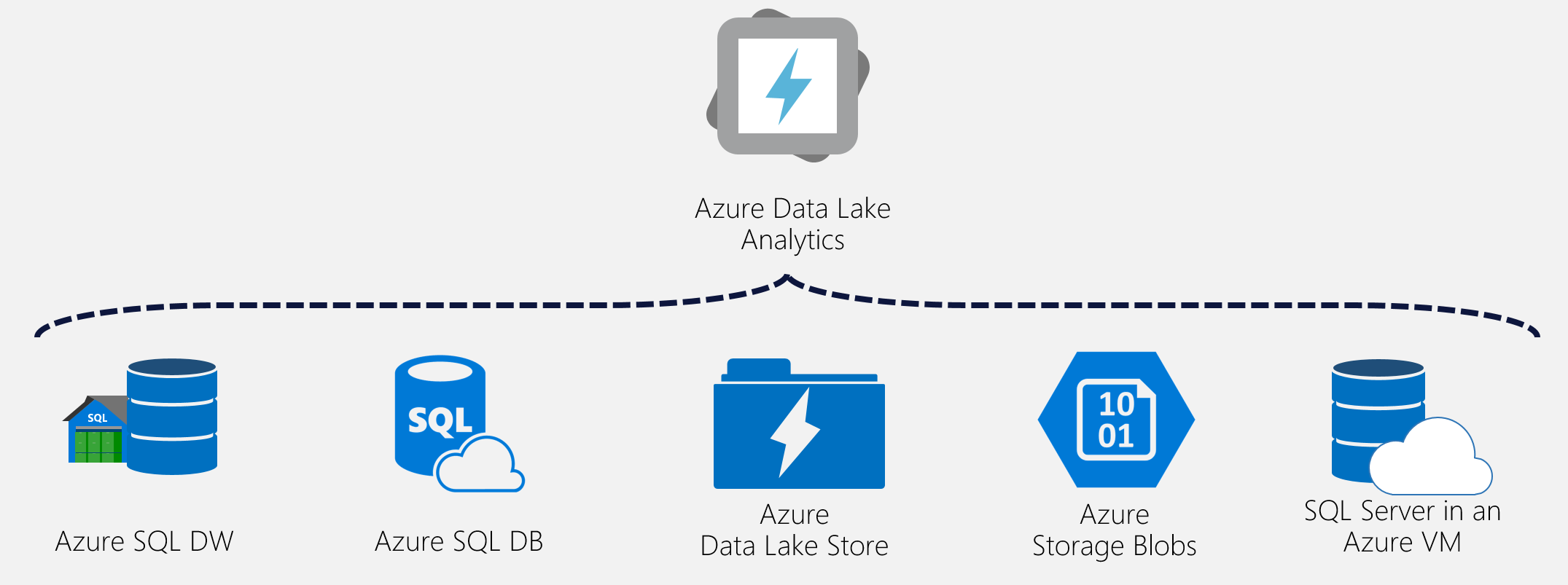
データソースは以下の図のようになるらしいですが、今はAzure BlobとData Lake Storeだけ選べるようになってました。※おそらくPreviewだからと思います。
手順③ Add Jobで処理を追加する
処理はU-SQLというSQLをData Lake用に拡張した感じの言語を使う。
//--TSVファイルを型指定して変数へセット
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @"/Samples/Data/SearchLog.tsv"
USING Extractors.Tsv();
//--一時的に利用するRDBっぽいテーブルを作る
CREATE TABLE IF NOT EXISTS SampleDBTutorials.dbo.SearchLog
(
UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string,
INDEX idx1 //Name of index
CLUSTERED (Region ASC) //Column to cluster by
PARTITIONED BY HASH (Region) //Column to partition by
);
//--TSVからのデータを一時テーブルにインサート
INSERT INTO SampleDBTutorials.dbo.SearchLog
SELECT *
FROM @searchlog;
//--GroupByの集計処理をする
@athletes =
SELECT Region,SUM(Duration) AS TotalDuration
FROM SampleDBTutorials.dbo.SearchLog
GROUP BY Region;
//--結果をTSVに書き出す
OUTPUT @athletes
TO @"/Samples/Output/SearchLog_output.tsv"
USING Outputters.Tsv();
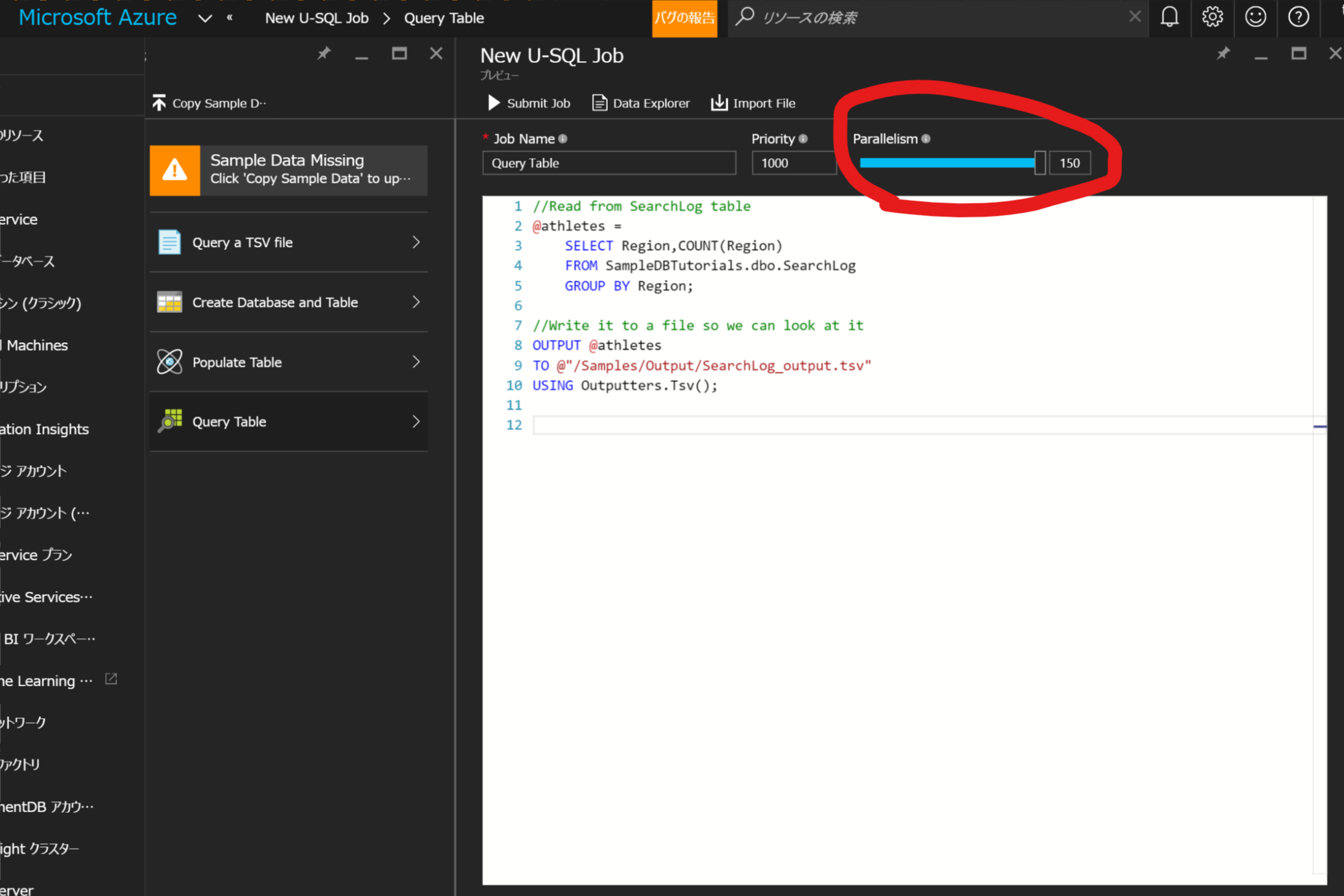
手順④ JOBを実行する。ポイントは、この実行画面で分散数を設定できるところ。
Parallelismという設定で、簡単に設定できる。
Hadoopだど事前にノードをたくさん起動しておかないといけないのに、
こんな簡単に分散数を変えられる点に驚きました。
いまさらですが、Cloudパワーってすごいですね。
実行状況が表示される
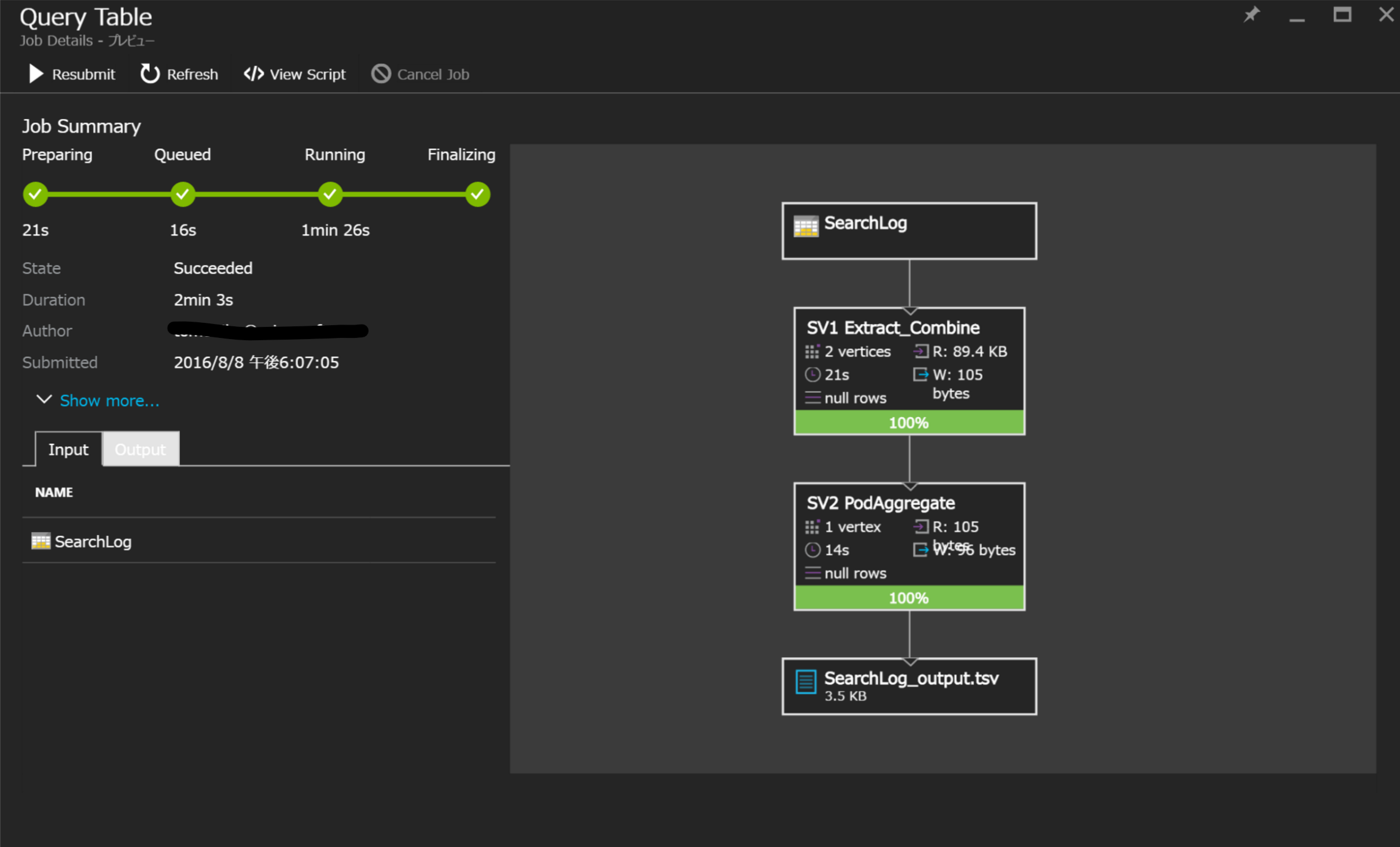
手順⑤ 結果ファイルのTSVがData Sourceに作成されている
手順は以上
コストについて
Azure Data Lakeは、サーバレス型の機能であり、
HDInsightやVitual Machineと違って、サーバ起動時間課金ではないです。
詳細は以下のようになっているらしい。

よくわからないですね。
ただ、サーバレスアーキテクチャの機能なのでたぶん激安だと思います。
今度、請求書みて確認してみます。
調査の残
GoogleのBig Queryの概要を見ると似た機能に見えますが、どう違うのだろう。
Big Queryは使ったことないが、評判はよいので比べてみたい。
おわりに
Azure Data Lakeを使えば、サーバマシンの数やOSやその上で動く各種機能、
分散のためのPythonのライブラリなどアプリ開発者からすれば、
めんどくさいことを考えなくて済むところが魅力かと思います。
まぁ、U-SQLは覚えないといけないけど、
パッと見、SQLに似てるから習得しやすそうな気がします。
Data Lake Analysisで処理するのは、加工されていないRowDataを
集計して小さくするところだけに割り切って使うようにした方がいいだろうと思う。
よくありそうなアーキテクチャとしては以下の感じ。
①大量データをTSVかCSVで、HDFS(Data Lake Store)にガンガン配置
②Data Lake Anlaysisで、簡易なクレンジングと集約 ※あまり加工はしない
③RDBに結果データを出力し、SQLで加工する
④加工後のデータをアプリで参照する
Hadoopとひとくくりに言ってしまいましたが、
Data Lake Analysisで対応できるのは、バッチ型のHadoop処理になります。
Sparkのようなリアルタイム系の処理は、いまのところ無理ですね。
ただたぶん、リアルタイム系もData Lakeに似たサービスが今後、必ずでてくると思います。
例えばSparkだと、分散処理できるPython(PySpark)や分散できるR(ScaleR)などが使えますが、
常時オンラインにして使い続ける類の機能じゃないので、
Sparkのインフラ基盤なんて作りたくなくて、サーバレス構成にしてほしいと考える人がほとんどだと思います。
欲を言えば、普通のPythonやRのコードのまま、勝手に裏で分散されてほしいところですね。
クラウドになって、急速にインフラ系の仕組みが隠蔽されていきますね。
エンジニアとしては、身につけていくスキルが世の中で使われなくなるというのは痛手なので、
今後必要なくなりそうな技術かどうかは注意して見ていかないとなって思います。
なんとなくですが、クラウド系の技術を学んでいるとコード(スクリプト系が多い)を書く必要のある状況が多くなってきているように感じます。コードを書く箇所ということは、ユーザニーズをきめ細やかに反映させる必要があるところということなので、自動化が進まない領域なんでしょう。
OnPremiseの時代はコードを書かないエンジニアが多くいましたが、これからはコードが書けることがより重要になっていくように感じています。