はじめに
昨日夜2時からGoogle I/Oのキーノートを見ていて寝不足の今日。
最近Googleの発表も面白いので、リアルタイムで見てみたが、
僕はやっぱMicrosoftのBuildとかde:codeとかの方が心躍るなと思いました。
なんか実際に動作させるデモとか少ないよね?
ビデオとか実際にやってないデモばっかに感じました。
Microsoftのイベントだと新しいデバイス出したら、
その場で試して見せるのがお約束になってるのに。
で、そのGoogle I/O見ていて、
AI技術の一部としてでていた画像認識APIを見て、
Microsoftのすご過ぎ画像認識と比べてどっちがすごいか試したくて
しかたくなくなりやってみました。
使ったサービス
・Google Cloud Vision API
https://cloud.google.com/vision/
・Microsoft Computer Vison API
https://www.microsoft.com/cognitive-services/en-us/computer-vision-api
利用手順
・Google Cloud Vision API
こっちはGoogle Cloud ServicesのStorageに写真を配置しろってことだったので、
めんどくさいがCloudを無料体験で登録し、利用。
手順は↓のサイトにある。
https://cloud.google.com/vision/docs/quickstart
・Microsoft Computer Vision API
こっちは簡単に試せるデモサイトをMSが用意してくれているので、それを利用。
https://www.microsoft.com/cognitive-services/en-us/computer-vision-api
試した結果
とりあえず5つくらい試してみました。
●1つ目●

----Google------------
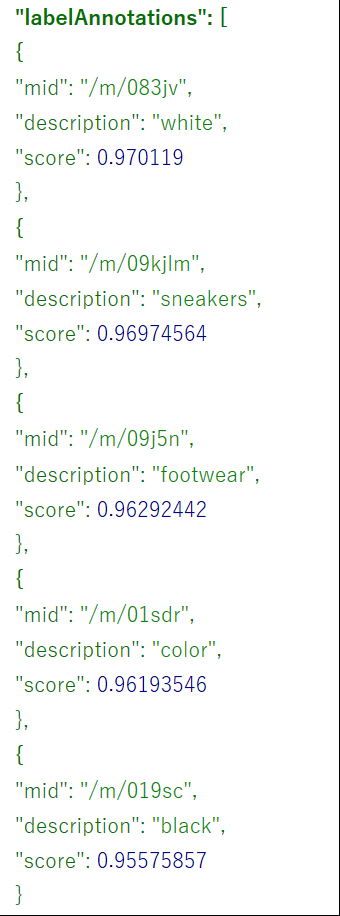
※scoreは確信度合い
----Google-------------
----Microsoft----------

----Microsoft----------
●2つ目●

----Google------------
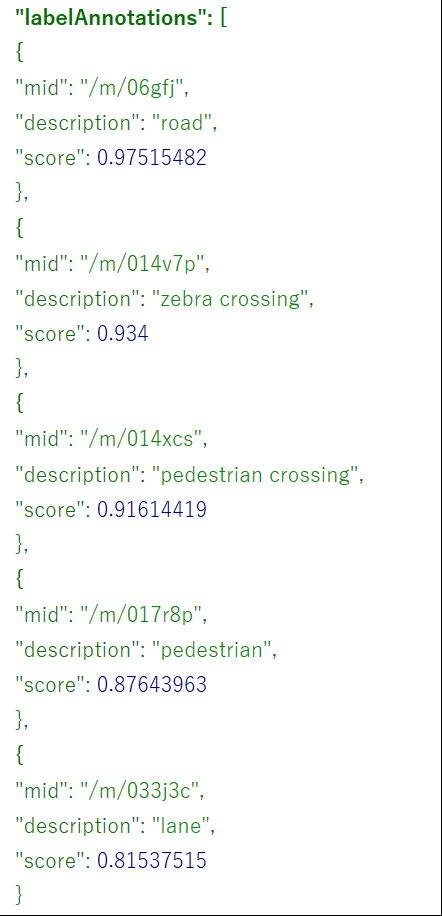
----Google-------------
----Microsoft----------

----Microsoft----------
●3つ目●

----Google------------

----Google-------------
----Microsoft----------

----Microsoft----------
●4つ目
ちょっと画質が悪い写真

----Google------------
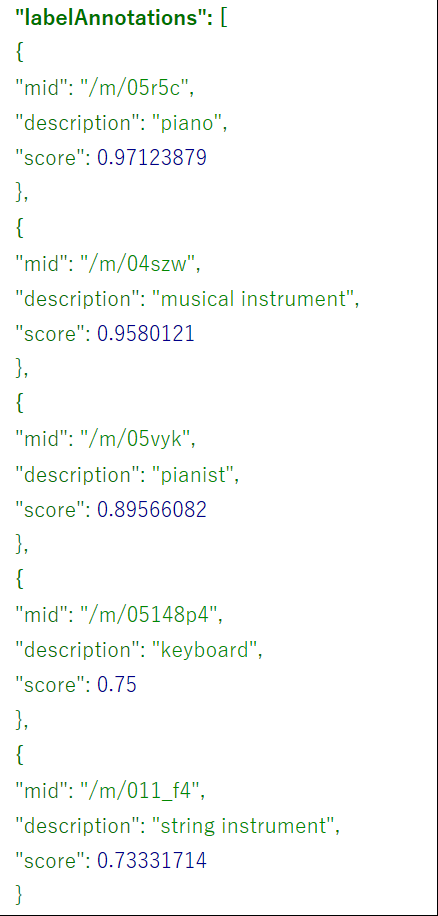
----Google-------------
----Microsoft----------

----Microsoft----------
考察
Microsoft側のDescription内のtextがすげぇ。
3つ目の写真を見て、「a brown and white dog sitting in a field(地面に座っている茶色と色の毛並みの犬)」だって!
5つ目の写真を見て、「a young boy sitting in front of a piano(ピアノの前に座った若い少年)」だって!
タグの部分についてはまぁまぁ互角かと思いましたが、
MicrosoftのDescriptionは圧倒的にすごいと感じました。
・まず1物体を個別に判断するのではなく、「ピアノの前に」など位置関係を理解して説明している
・人や動物については座っているや道を横切るなど、活動状態を説明している
・写真の中でもっとも目立つものについて説明している
人が写真を見たときに把握しようとする状況を
簡潔に説明できているように思う。
上記4つ以外にも10写真ほど試してみたが、どれもまずまずな説明力だった。
なのでMicrosoftの画像認識の勝ちかなと思います。
かなり偏った評価ではありますが。。。
おわりに
このMicrosoft側のDescriptionの部分を使って
何か楽しいものが作れないか考え中です。
ロボットのおもちゃとか作ってみたいな。
ロボットの目にカメラがついていて、
「今何が見えてる?」って声をかけると
その音声をトリガーにして写真をとり、
その写真をComputer Vision APIに投げて結果を受け取り、
次に英語を日本語に翻訳するAPIを投げて結果を受け取り、
Yamahaのボカロのような機能に日本語を音声出力させる。
処理時間中とかは「う~んとね、う~んとね。」ってしゃべらせて、
「ピアノに前に座ってる男の子がいるよ!」って答えさせたい。
でも、ほとんどの人間ができることをロボットにさせたってビジネス的に需要ないかもなー。
だから、目の前にある状況を言葉で説明できるロボットって使い道は
エンターテイメントしかなさそうだけど、
みんなびっくりしそうで、興味もってくれるんじゃないのかなー、とも思う。
今度、息子と作ってみよっ。
※【続】機械学習 画像認識のGoogle 対 Microsoftに続き、IBM Watsonやってみた
http://qiita.com/tomohiku/items/c133341653e728f73cbf