深層学習の発達は凄まじいもので、1年半くらい前までは一枚の顔の写真の口や目を動かすだけで精一杯だったにも関わらず、最近は自分の顔に合わせて目、口、顔の動きや向きまでも同期できるようなモデルが登場した。それがFirst Order Motion Model(FOMM)といい、従来の研究と比べても逸脱した研究成果を見せて、世界中から注目されたモデルでもある。

次のツイートの動画を見てほしい。これは学会NeurIPS 2019でのFirst Order Motion Modelについての研究発表の映像である。なんと発表者の顔と同期して、オバマ、トランプ、モナリザなどの写真が動いているのである。音声ありで再生すれば発音とオバマたちの口の動きが同じになっていることが分かる。これほど衝撃的な研究発表は今までにあっただろうか。当時は写真の顔を違和感なく動かすだけでもかなり革新的であり、しかもリアルタイムで動いた顔を生成できるというのはかなり衝撃的な内容だった。
今まで見た中で最も衝撃的な研究発表
— Toshiki Tomihira (@tommy19970714) August 28, 2020
オバマ「We present our work...」
トランプ「We present our work...」
モナリザ「We present our work...」
発表者の代わりに、モナリザたちが発表している..!🤔 pic.twitter.com/9Dv7zLuuAQ
このFOMMは、次のGithubで公開されている。論文だけではなく、レポジトリもしっかりまとめているということもあって7.3kものスターがついている。
https://github.com/AliaksandrSiarohin/first-order-model
本記事では、FOMMの簡単な解説と実際に動かしてみるところまで解説を行うことをする。これを使えば、Zoomでモナリザになって会話できるし、プロモーションムービーとして面白い演出を作ることもできるし、さらには展示している絵が自分の顔と連動して動くメディア・アートだって作れるかもしれない。なのでこの技術を誰でも使えるように実装されているレポジトリの使い方をメインに解説していこうと思う。
First Order Motion Model(FOMM)の仕組み
このモデルについての論文はこちら。
Siarohin, Aliaksandr, et al. "First Order Motion Model for Image Animation." Advances in Neural Information Processing Systems. 2019.
https://papers.nips.cc/paper/8935-first-order-motion-model-for-image-animation
次の図がFOMMの手法についてまとめたものである。主にMotion Module、Generation Moduleの2つの要素から構成されている。
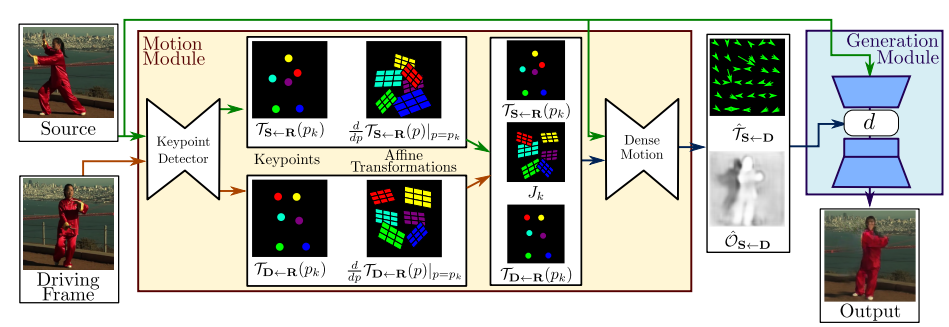
上の図と照らし合わせながら、解説を読んでほしい。
Motion ModuleはSource画像(動かしたい画像)とDriving Frame(動画の1フレーム)を入力としている。Keypoint Detectorで、その2つの画像のキーポイントを推定し、Affine Transformationを作成する。Affine Transformationというのは簡単に言うとSource画像のキーポイントをDriving Frameのキーポイントの位置に変換するために行列のようなものである。
そして、Dense MotionでSourceの画像とキーポイント、Affine Transformationを入力として、深度情報を含むOcclusion maskを生成する。
Generation ModuleではSource画像とOcclusion maskを入力として、最終的なアウトプットとしてSource画像をDriving Frame画像と同じ動きになっている画像を生成する。ここのネットワークはPixel to PixelのGenerative Adversarial Networks(GAN)となっている。
ここでポイントなのは動画のキーポイントの動きを使用して生成したAffine Transformation(変換行列)をGANの入力としていることである。先行研究として、単純な画像を入力としたGANはあったが口を開いたところで違和感があった。また3Dモデルベースの先行研究は生成画像の精度は高いが顔を動かす自由度がなかった。このAffine Transformationを使ったやり方がすごいのは生成画像の精度と顔の動かす自由度の両方を達成しているところである。またこの方法を応用すれば、顔を動かすだけではなく体の手足を動かしたり、馬などの動物の写真も動かせてしまうというのがブレイクスルーであった。
より詳しい解説はこちらを参照してほしい。
実際にモナリザを動かしてみる
それではFOMMモデルを動かしてみよう。研究チームはPytorchで実装したモデルをGithub上で公開している。
実際に動くコードをGoogle Colaboratoryで作ってみた。次のURLから私の作成したnootebookを確認できる。このnotebookを自分のdriveにコピーして動かしてみてほしい。(ただ上から順番にセルを実行するだけで動かすことができる)
https://colab.research.google.com/github/AliaksandrSiarohin/first-order-model/blob/master/demo.ipynb
作成したColaboratoryのコードをQiitaでも解説していくことにする。
レポジトリのクローン
Githubからレポジトリ (https://github.com/AliaksandrSiarohin/first-order-model) をクローンする。
!git clone https://github.com/AliaksandrSiarohin/first-order-model
%cd first-order-model
Google Driveをマウント
学習済みモデルやtestデータなどがこちらのGoogle Driveで公開されている。
前までは他の人が公開しているGoole Driveを自分のGoogle Driveに追加する「ドライブに追加」という機能があったが、ショートカット機能のリリースで使用できなくなった。そのため、自分のGoogle Driveの直下にfirst-order-motion-modelというフォルダを作成し、公開されているGoogle Drive内のそれぞれのファイルのコピーを作成し、それをfirst-order-motion-modelフォルダに移動する。
colabでのGoogle Driveのマウントは次のコードでできる。
from google.colab import drive
drive.mount('/content/gdrive')
Source画像と動かすための動画を読み込む
今回はSource画像として、Google Drive内にあるモナリザの画像first-order-motion-model/05.pngと、動かすための動画としてトランプの動画first-order-motion-model/04.mp4'を使用することとする。
次はGoogle Drive内の画像と動画を読み込み、256x256にリサイズした上でcolab上で表示するコードである。
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from skimage.transform import resize
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
source_image = imageio.imread('/content/gdrive/My Drive/first-order-motion-model/05.png')
driving_video = imageio.mimread('/content/gdrive/My Drive/first-order-motion-model/04.mp4')
#Resize image and video to 256x256
source_image = resize(source_image, (256, 256))[..., :3]
driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video]
def display(source, driving, generated=None):
fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6))
ims = []
for i in range(len(driving)):
cols = [source]
cols.append(driving[i])
if generated is not None:
cols.append(generated[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000)
plt.close()
return ani
HTML(display(source_image, driving_video).to_html5_video())
上記のコードを実行したら、次の動画(左は静止画、右は動画)をcolab上で確認することができる。

学習済みモデルを読み込む
次のコードでGoogle Drive内にある学習済みモデルを読み込むことができる。
解説のセクションで説明したように、FOMMにはMotion ModuleとGeneration Moduleがあるため、学習済みモデルも2つが存在する。
from demo import load_checkpoints
generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml',
checkpoint_path='/content/gdrive/My Drive/first-order-motion-model/vox-cpk.pth.tar')
実行してみる
次のコードで先程読み込んだ学習済みモデルを使用して、モナリザが動くようにPredictionすることができる。
from demo import make_animation
from skimage import img_as_ubyte
predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True)
#save resulting video
imageio.mimsave('../generated.mp4', [img_as_ubyte(frame) for frame in predictions])
HTML(display(source_image, driving_video, predictions).to_html5_video())
また実行するとColab上でモナリザが動いた結果を確認することができる。
口の動きだけではなく、しっかり目の瞬きもしているし、顔を動かしてもその通りに追従することができている。

エンハンスについて
後発で3D ModelベースでMotion AnimationができるモデルHead2Head++がでたのだが、精度はFirst Order Motion Modelより高いが、顔の動きの追従の部分ではやはりMotion Animationが優れていた。
ちなみに現状のコードでは255x255のサイズで通常の動画を置き換えるには解像度が足りないだろう。実用的なことを考えると、解像度だけでなく、フレームレートも足りなかったりする。そこで超解像やフレーム補間の技術を使用して、変換した動画をエンハンスできるColabもある。こちらを使ってほしい。
https://colab.research.google.com/drive/1YCkY9Cngj8Djl9RTgOOJD6Hi28Ikde5h?usp=sharing
まとめ
今回は、FOMMモデルについて解説から、実際に動かすところまで解説を行った。画像生成形の深層学習モデルの分野は日々新しい論文がでてくるため驚きの連続で、こういった最新の技術をチェックするのはとても楽しいものだ。
最近zoomでモナリザになって会話できたら面白いなと思い、趣味でmacosの仮想カメラアプリを開発し始めた。顔になりきるだけはなく、snowみたいなフィルターや加工もできるようになる予定である。興味ある人はTwitterでDMをもらえたら嬉しい。
最高にzoom映えするZoomで使えるsnowみたいなアプリを作っています!
— Toshiki Tomihira (@tommy19970714) August 4, 2020
色々なフィルターや肌加工ができます!
今後は顔の輪郭、目の大きさ等を変えられるようになる予定ですー!
開発のきっかけはフォロワーさんからの要望でした。
多くの人に知ってもらえたら嬉しいです! pic.twitter.com/lFlz9pw1v1