前回 (Optimizer : 深層学習における勾配法について) の続きです。
はじめに
今回は前回紹介した各最適化手法の比較を、簡単なモデルを用いて検証してみました。
使用した学習データはおなじみMNISTの手書き数字画像で、簡単なCNN (Convolutional Neural Network) によって分類精度を指標に比較しました。前回も軽く触れましたが、あくまでこのモデルにおける最適化手法を検証する内容になるため、他のモデルに用いる場合は参考にする程度に留めた方が良いと自分は考えています。
MNISTについて
今回用いる学習データはMNIST (Mixed National Institute of Standards and Technology database) という手書き数字の画像が保管されているデータベースです。このデータベースには8bit (画素値 : 0-255) のグレースケール28×28ピクセルの画像が70000サンプル格納されています。数字の種類は0-9の10クラス存在し、画像は一次元配列 (784要素) として用意されており、全てに正解ラベルが付加されています。どのような画像か確認するため、MNISTの中からランダムに取り出した画像を以下に示します。画像の上に表示された値が正解ラベルです。

手書き数字とだけあって、結構人の目でも判別しにくい画像があったりします。
このデータを用いて分類タスクを各最適化手法を用いたCNNで行いたいと思います。
CNNの構造について
今回のニューラルネットワーク構造についてです。概略図を以下に示しました。
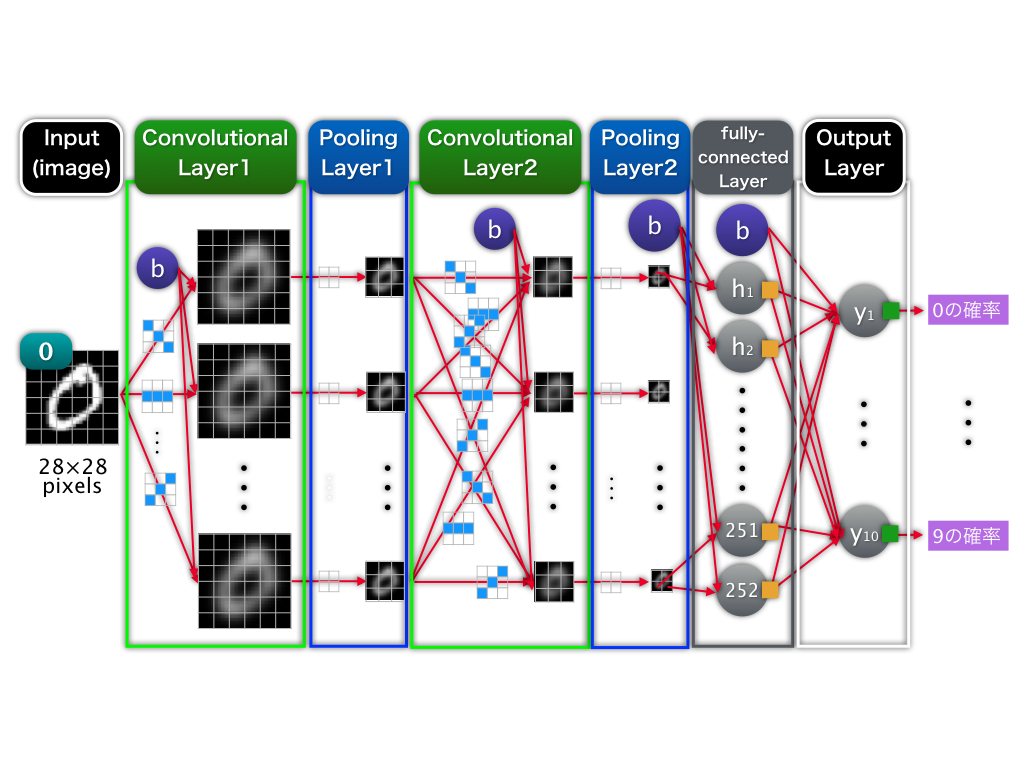
活性化関数はLeRU、出力関数はSoftMaxを用いています。畳み込み層(Convolutional Layer)は、どちらもfilter = 28, kernel size = 5、プーリング層(Pooling Layer)は、一層目がkernel size = 2, stride = 2、二層目がkernel size = 3, stride = 3です。全結合層(fully-connected Layer)は1層で252unitsです。
ニューラルネットワークの構造をどのように決めるかということに関して、未だにごりごりのローラー作戦で最適化してます。。画像の大きさや特徴によって、畳み込み層やプーリング層のカーネルサイズはある程度経験的に決めることができるのですが、層数やユニット数などに関しては未だにこれといった経験的な指標も掴めていないです。最近様々なハイパーパラメータの最適化手法が提唱されているので、勉強してみたいと思っています。
評価
各Optimizer (SGD, Momentum SGD, AdaGrad, RMSprop, AdaDelta, Adam)について5交差検定による評価を行いました。各Optimizerのハイパーパラメータはデフォルトの値を用いています。結果は以下となります。
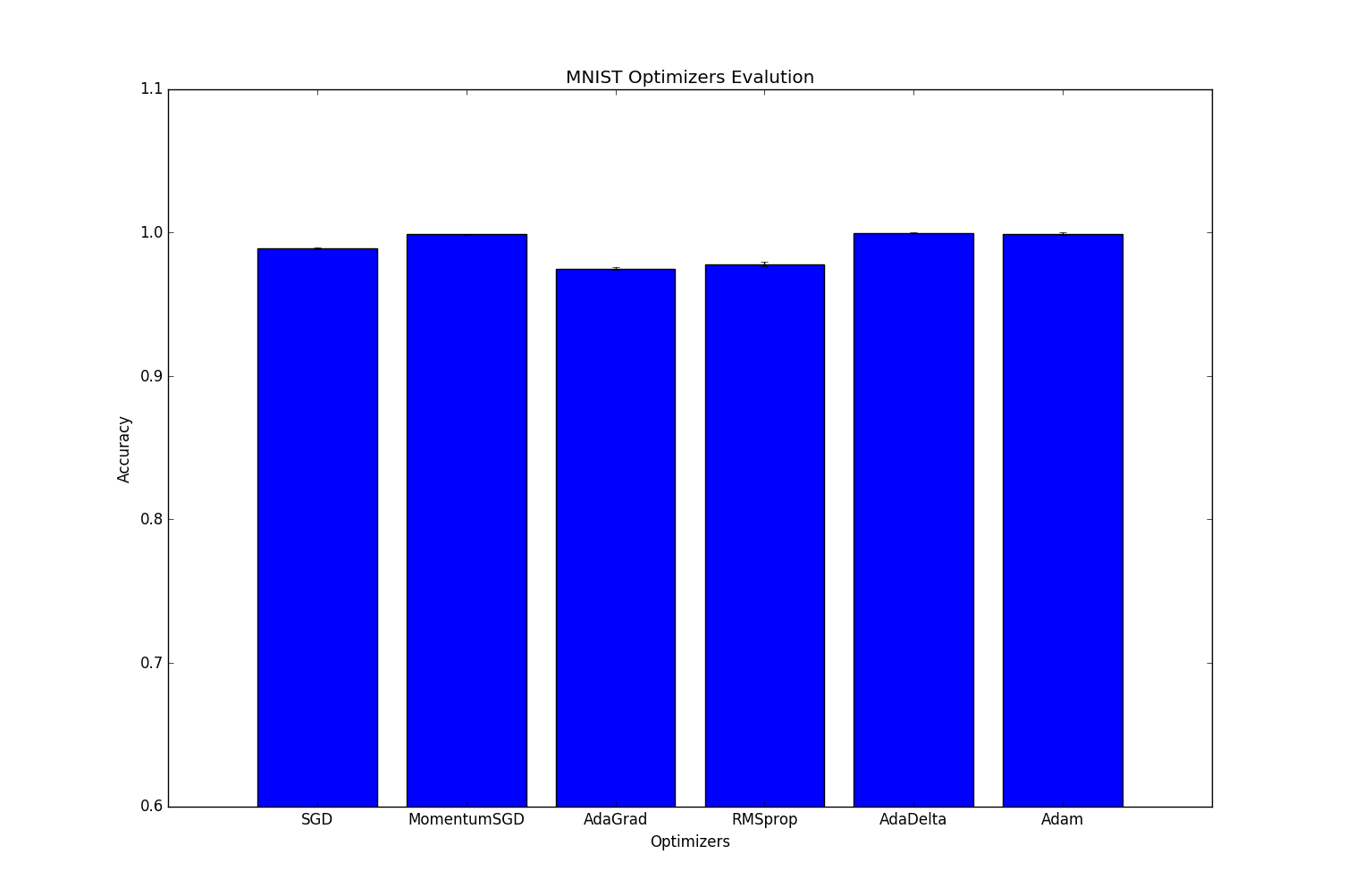
| Optimizers | Accuracy | Variance |
|---|---|---|
| SGD | 0.989 | 3.571443e-07 |
| MomentumSGD | 0.998685714286 | 6.785714e-08 |
| AdaGrad | 0.974685714286 | 8.229592e-07 |
| RMSprop | 0.981014285714 | 3.247449e-06 |
| AdaDelta | 0.999828571429 | 6.632653e-09 |
| Adam | 0.999471428571 | 7.918367e-07 |
結果はAdaDeltaが一番高い精度を出し、次点でAdamでした。一応分散も出したのですが、これもAdaDeltaが一番小さいことから安定していることがわかります。
以上のことから、今回の手書き数字10クラス分類というタスクにおいては、分散・精度ともにAdaDeltaが最も適していることがわかりました。
この結果が出るまでは、どうせAdamの圧勝だろーなーって軽く考えていただけに面白い結果が出てしまいました。今回のようなモデルの場合、Adamのバイアスを打ち消す項が逆に学習の収束まで足を引っ張ってしまうのでしょうか。そもそもChainerのAdamが自分が考えている動き方をしているのかも不安なのですが、、
単純にAdamを使っておけばいいという訳ではなさそうですね。
まとめ
最初にも述べましたが、今回の手書き数字分類問題に関してはこのような結果が出ましたが、あくまでこの問題における結果であるということは念頭に置かなければならないと思います。他の問題に適用する際に、参考になればいいかなと。Optimizerのハイパーパラメータもふっているわけではないので。
ちなみに今回の実行結果は出力し終わるまで1週間以上かかっています。GPUに対応しなければということもあるのですが、最適化をどこまで行うか、ひいてはどの程度で妥協するか、ということも学習させる上で気をつけなければならないポイントだと思います。学習は、正答率をあげようと思えばいくらでもふれるパラメータが存在するため、学習させる上で何が重要であるかしっかりと見極めることが大事だということです。時間が足りなさすぎる。。
最後に、間違いや指摘する点が何かありましたらコメントしていただけると助かります。
Appendix
今回評価するにあたって実装したコードを以下に載せます。Chainer1.1.1の知識しかないため実装が遅れている部分が多いです。。
https://github.com/tokkuman/MNIST_Opitmizer_Evaluation
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.datasets import fetch_mldata
from chainer import cuda, Variable, FunctionSet, optimizers
import chainer.functions as F
import sys
import cv2
import copy
import csv
import pylab as plt
plt.style.use('ggplot')
def cross_split(data, label, k_cross, n, perm, N, length):
x, y = [], []
for i in range(k_cross):
x.append(mnist.data[perm[i*N/cross:(i+1)*N/cross]])
y.append(mnist.target[perm[i*N/cross:(i+1)*N/cross]])
x_train, y_train = [], []
for i in range(k_cross):
if i == n:
x_test = copy.deepcopy(x[i])
y_test = copy.deepcopy(y[i])
else:
x_train.append(copy.deepcopy(x[i]))
y_train.append(copy.deepcopy(y[i]))
x_train = np.array(x_train).reshape(N*(k_cross-1)/k_cross, 1, length, length)
y_train = np.array(y_train).reshape(N*(k_cross-1)/k_cross)
x_test = x_test.reshape(N/k_cross, 1, length, length)
return copy.deepcopy(x_train), copy.deepcopy(x_test), copy.deepcopy(y_train), copy.deepcopy(y_test)
def forward(x_data, y_data, train=True):
x, t = Variable(x_data), Variable(y_data)
h1 = F.max_pooling_2d(F.relu(model.conv1(x)), ksize=2, stride=2)
h2 = F.max_pooling_2d(F.relu(model.conv2(h1)), ksize=3, stride=3)
h3 = F.dropout(F.relu(model.l3(h2)), train=train)
y = model.l4(h3)
return F.softmax_cross_entropy(y, t), F.accuracy(y, t)
def cross_optimizers(opt):
if opt == 'SGD':
optimizer = optimizers.SGD()
elif opt == 'MomentumSGD':
optimizer = optimizers.MomentumSGD()
elif opt == 'AdaGrad':
optimizer = optimizers.AdaGrad()
elif opt == 'RMSprop':
optimizer = optimizers.RMSprop()
elif opt == 'AdaDelta':
optimizer = optimizers.AdaDelta()
elif opt == 'Adam':
optimizer = optimizers.Adam()
return copy.deepcopy(optimizer)
if __name__ == '__main__':
mnist = fetch_mldata('MNIST original')
mnist.data = mnist.data.astype(np.float32)
mnist.target = mnist.target.astype(np.int32)
mnist.data /= mnist.data.max()
n_epoch = 50
batchsize = 100
cross = 5 # 5 Cross Validation
optimizer_list = ['SGD', 'MomentumSGD', 'AdaGrad', 'RMSprop', 'AdaDelta', 'Adam'] # Optimizers List
opt_train_loss = []
opt_train_acc = []
opt_test_loss = []
opt_test_acc = []
N, imagesize = mnist.data.shape
length = int(np.sqrt(imagesize))
cross_perm = np.random.permutation(N)
for opt in optimizer_list:
print '========================='
print 'Set Optimizer : ' + opt
cross_acc_sum = 0
cross_train_loss = []
cross_train_acc = []
cross_test_loss = []
cross_test_acc = []
for k in range(cross):
print '-------------------------'
print 'Cross Validation : ' + str(k + 1)
model = FunctionSet(
conv1 = F.Convolution2D(1, 28, 5),
conv2 = F.Convolution2D(28, 28, 5),
l3 = F.Linear(252, 252),
l4 = F.Linear(252, 10) )
optimizer = cross_optimizers(opt)
optimizer.setup(model)
x_train, x_test, y_train, y_test = cross_split(mnist.data, mnist.target, cross, k, cross_perm, N, length)
N_train = x_train.shape[0]
cross_acc = 0
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(1, n_epoch+1):
print 'epoch' + str(epoch)
loss_sum, acc_sum = 0, 0
perm = np.random.permutation(N_train)
for i in range(0, N_train, batchsize):
x_batch = x_train[perm[i:i+batchsize]]
y_batch = y_train[perm[i:i+batchsize]]
optimizer.zero_grads()
loss, acc = forward(x_batch, y_batch)
loss.backward()
optimizer.update()
real_batchsize = len(x_batch)
loss_sum += float(cuda.to_cpu(loss.data)) * real_batchsize
acc_sum += float(cuda.to_cpu(acc.data)) * real_batchsize
print 'Train Mean Loss={}, Accuracy={}'.format(loss_sum / N_train, acc_sum / N_train)
train_loss.append(loss_sum / N_train)
train_acc.append(1 - (acc_sum / N_train))
N_test = x_test.shape[0]
loss_sum, acc_sum = 0, 0
for i in range(0, N_test):
x_batch = x_train[i].reshape(1, 1, length, length)
y_batch = np.array(y_train[i]).reshape(1)
loss, acc = forward(x_batch, y_batch)
loss_sum += float(cuda.to_cpu(loss.data))
acc_sum += float(cuda.to_cpu(acc.data))
print 'Test Mean Loss={}, Accuracy={}'.format(loss_sum / N_test, acc_sum / N_test)
test_loss.append(loss_sum / N_test)
test_acc.append(1 - (acc_sum / N_test))
if cross_acc <= acc_sum / N_test:
cross_acc = acc_sum / N_test
cross_acc_sum += cross_acc
cross_train_loss.append(train_loss)
cross_train_acc.append(train_acc)
cross_test_loss.append(test_loss)
cross_test_acc.append(test_acc)
print '====Cross Validation===='
print opt + ' 5 Cross Validation Mean Accuracy : ' + str(cross_acc_sum / cross)
opt_train_loss.append(cross_train_loss)
opt_train_acc.append(cross_train_acc)
opt_test_loss.append(cross_test_loss)
opt_test_acc.append(cross_test_acc)
f = open('opt_train_loss.csv', 'ab')
csvWriter = csv.writer(f)
csvWriter.writerow(opt_train_loss)
f.close()
f = open('opt_train_acc.csv', 'ab')
csvWriter = csv.writer(f)
csvWriter.writerow(opt_train_acc)
f.close()
f = open('opt_test_loss.csv', 'ab')
csvWriter = csv.writer(f)
csvWriter.writerow(opt_test_loss)
f.close()
f = open('opt_test_acc.csv', 'ab')
csvWriter = csv.writer(f)
csvWriter.writerow(opt_test_acc)
f.close()