あるSlackでの会話
何がおきているのか
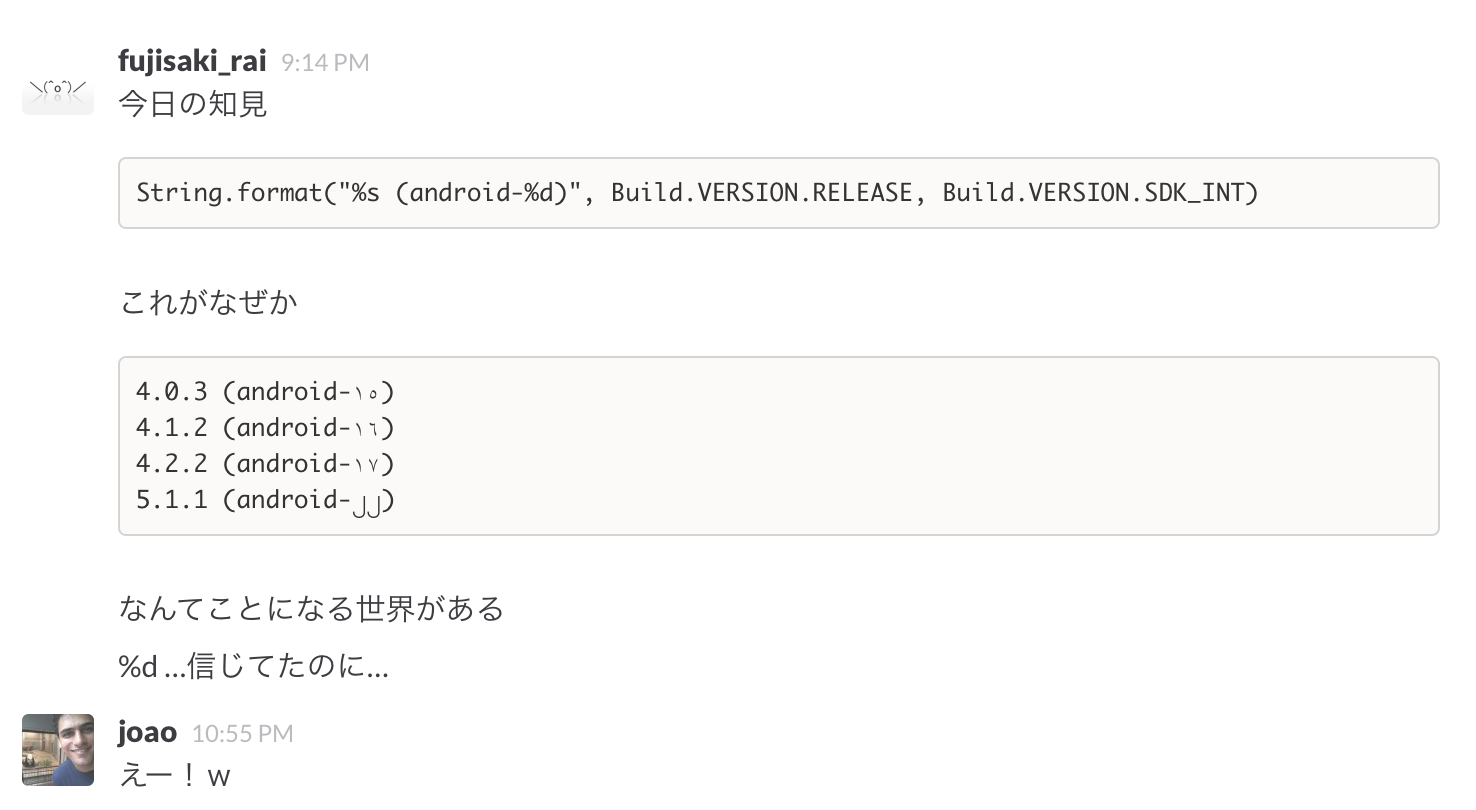
Android 端末でプラットフォームの API バージョンを出すのに、ちょっと色気を出して、
String.format("android-%d", Build.VERSION.SDK_INT)
なんて書いたりします。で、だいたい android-22 みたいな感じになるんですけど、でもやっぱり世界ってのは広くて、ふと見たらなんか android-١٦ とか android-၂၂ とか不思議なやつがいるんですよ。 何それ読めない。
もしかして SDK_INT が変な端末がいるのかな??と一瞬考えたんですが、 Build.VERSION.SDK_INT は名前通りプリミティブな public static final int なので疑いようがなかった。
AndroidじゃなくてJavaの仕様
でよくよく調べると、 java.util.Formatter のドキュメントに [Number Localization Algorithm](http://docs.oracle.com/javase/7/docs/api/java/util/Formatter.html#l10n algorithm) なんてものが書かれていて、
- Each digit character d in the string is replaced by a locale-specific digit computed relative to the current locale's zero digit z; that is d -
'0'+ z.
要するに数字は DecimalFormatSymbols#getZeroDigit() を基準に計算した文字に置き換えられますと。アラビア語(ar)だったら ٠ で、 ビルマ語(my)だったら ၀ ですよと。ああ ၀ ってゼロだったのか……
[Androidの String.format のドキュメント](http://developer.android.com/reference/java/lang/String.html#format(java.lang.String, java.lang.Object...))にはこう書いてあって、わずかな優しさが垣間見えます。
If you're formatting a string other than for human consumption, you should use the
format(Locale, String, Object...)overload and supplyLocale.US. See "Be wary of the default locale".
デフォルトのロケールは人間以外が扱うのには使うべきじゃないぞと。
The default locale is not appropriate for machine-readable output. The best choice there is usually
Locale.US– this locale is guaranteed to be available on all devices, and the fact that it has no surprising special cases and is frequently used (especially for computer-computer communication) means that it tends to be the most efficient choice too.
すべてのデバイスに存在が保証されていて、驚くような特殊な仕様もなくて、コンピュータ間のやりとりに特によく使われる、つまり一番効率的な選択であるところの、 String.format(Locale.US, "%d", 0) を使えよ、って話ですね。
いろんなロケールで数字を出してみた
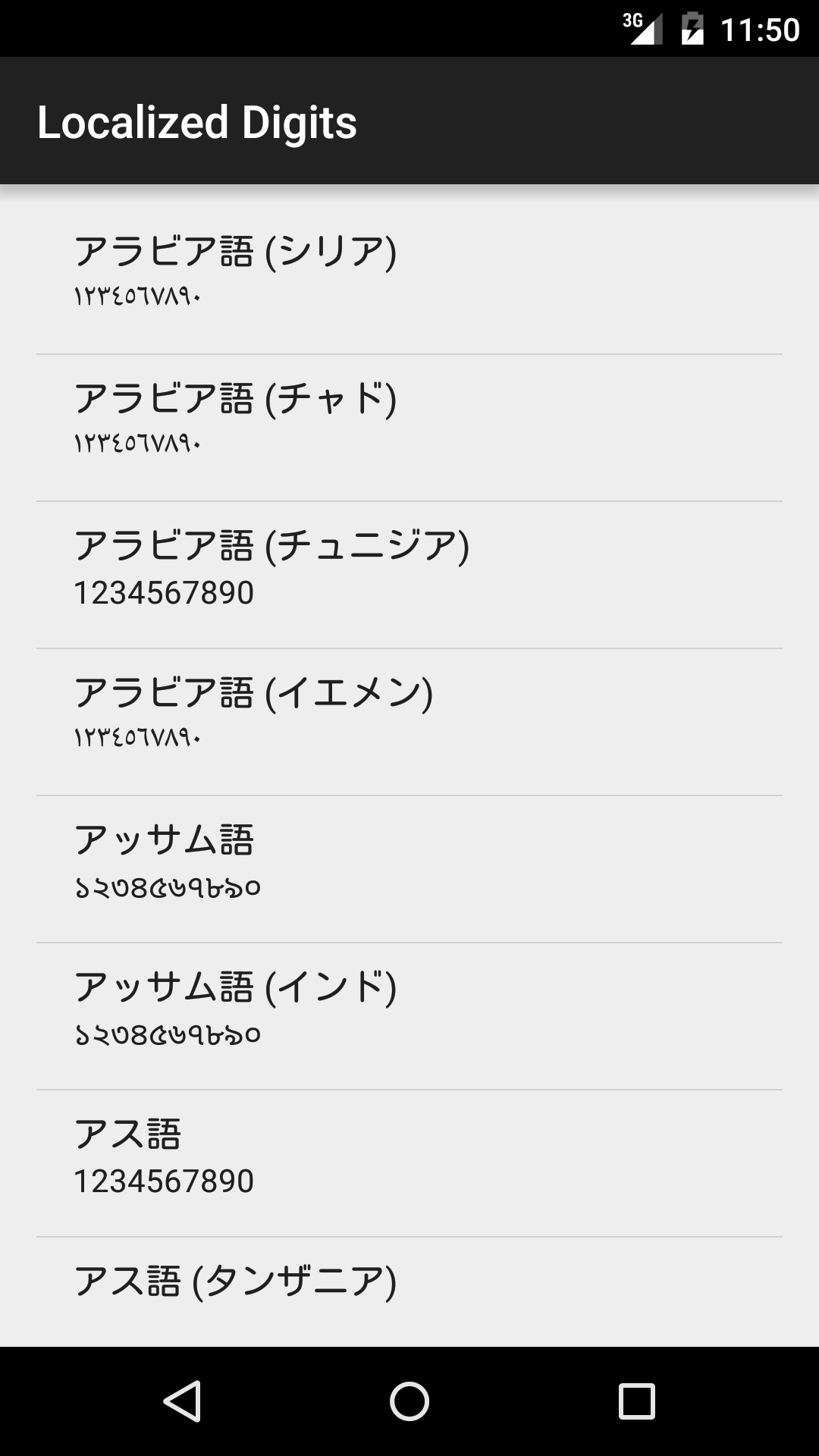
**見てるだけでなぜか辛い気持ちになれる!不思議!**ちなみに Android のバージョンごとに標準で存在するロケールが違います。
手元で見てみたい方はこちら:

ソースコードはこちら:
https://github.com/tnj/localized-digits
まとめ
- Java の
String.formatで ASCII な数字を出したかったらString.format(Locale.US, "%d", ...)を使うこと。 - こいつは
sprintf(3)の単なる代替じゃなかった
おまけ
というかこれを読めないのは俺だけじゃなくて君も Integer.parseInt() できないでしょ。と思ったんですが、
Integer.parseInt("၁၂၃၄၅၆၇၈၉၀"); // => 1234567890
Integer.parseInt("༡༢༣༤༥༦༧༨༩༠"); // => 1234567890
できるのかよ!
おまけ2: Japanese OK?
Integer.parseInt("1234567890"); // => 1234567890
Integer.parseInt("①②③④⑤⑥⑦⑧⑨⓪"); // => java.lang.NumberFormatException: Invalid int: "①②③④⑤⑥⑦⑧⑨⓪"
Integer.parseInt("一二三四五六七八九〇"); // => java.lang.NumberFormatException: Invalid int: "一二三四五六七八九〇"
全角数字は見た目も同じということもあって読めるようですが(適当なことをいう)、丸数字や漢数字は読めないようです。まあ「十二億三千四百五十六万七千八百九十」とか「壱拾弐億参千四百五拾六万七千八百九拾」とか渡されても困るもんね……
ざっと見たところ Character.digit で一文字ずつ見て正の値が返ってくる ( Character.getType で DECIMAL_DIGIT_NUMBER が返ってくる ) 文字を数字と見なしているようなので、 Unicode でどう定義されているのか次第って感じですね。ローマ数字(Ⅶとか)もだめなので、 数字だけど文化の中で何らかの数値を表すために使われていないものはdigitではない って感じなんだと思う。たぶん。深追いはしない。今回formatの挙動が主題でparseはおまけなんだからね!