※170606追記しました。
人工知能(機械学習)を使って、創作支援をするシリーズを連載します。
とりあえず第一弾として機械にキャラクターの設定を自動生成させたいと思います。
背景
近年、売上が急増するソーシャルゲームでは、キャラクター数が過去のコンテンツと比べ爆発的に増加している傾向にあります。
例えば、艦隊これくしょんでは350、Fate/GrandOrderでは150以上のキャラクターが確認されています。[要出典]
多様化するキャラクターの設定創出を、機械学習で行うモデルの構築と検証を行います。
手法
1. LSTMVAE
使用したのはLSTMVAEです。
VAEはニューラルネットによる生成モデルです。
musyokuさんが詳しく説明されているので、解説はこちらをどうぞ。
Auto-Encoding Variational Bayes
雑に説明しますと、オートエンコーダー(入力と出力を同じにしたモデル)において、中間層の分布をガウス分布に近づけることで、入力が無くても、ガウス分布自体から(つまり乱数から)データを生成できるようになるというわけです。
Kingmaの論文から引用した式を載せます。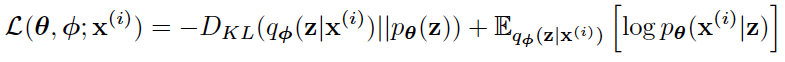
潜在変数モデルでは尤度が直接最大化できないので上記の変分下界を最大化しますが、右側のE〜で表される期待値は普通のオートエンコーダーの損失関数で、それに、左側のDKLで表される「中間層zをガウス分布に近づけるためのKLDivergence」を足しています。これで中間層zがガウス分布に従うオートエンコーダーが作れるわけです。
通常VAEは画像生成においてよく用いられていますが、言語においても応用可能です。
2015年に
Generating Sentences from a Continuous Space
という論文が出ています。
こちらではLSTMを使って言語のVAEモデルを構築しています。
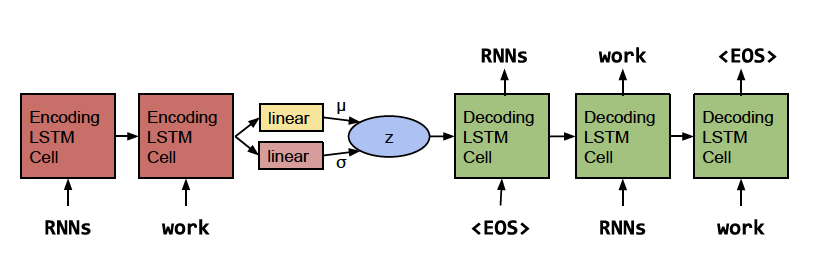
モデルの概要は上記です(引用)。
これはLSTMEncoderDecoderモデルのEncoder部分の最後の隠れ層から、ガウス分布のパラメータ(μとσ)を出力するネットワークを構築し、そのパラメータのガウス分布から生成されるデータをDecoderに渡して、Encoderで入力した文章を復元します。
ただ、普通にやってもうまくいかないと、この論文には書いてあります。
まず、2つの損失関数の内、KLDivergenceの方の係数を最初0にして、徐々に上げるようにしています。
そうしないと、KLDivergenceだけで学習してしまうようです。
次に、Decoderだけで学習してしまう問題があるので、Decoderに単語を入力する際は、ランダムで、unkベクトル(無情報ベクトル)に置き換えるようにした、とあります。(その割合は3分の1程度とあります。この手法はWordDropOutと言うそうです)
なので、それを真似して、やってみます。
epochは40で最初の15epochではKLDivergenceの係数を0にして学習させました。
ガウス分布からサンプル数は5で、
BiDirectionalLSTMの最後の隠れ層を結合して、ガウス分布のμとσを生成するネットワークを構築しています。
単語ベクトルの次元は300。
SentencePieceで形態素解析しています。単語数は約16000。
encoderのLSTMの隠れ層の次元は600。decoderは1200です。
中間層zの次元は1200です。(今思うと多すぎるかも)
WordDropの割合は0.2です。
コードは
https://github.com/ashwatthaman/LSTMVAE
に上げて置きました。
実装はchainerでやってます。1.24で動くはず。
./each_case/sampleTrainTest.py
から実行できます。
モデルはdownload_model.shでダウンロードしてください。
Read.meは後日書きます。(書かないフラグ
2. RNN言語モデルでの生成との違い
テキスト生成系の話題で以前よく見たのはRNN言語モデルを使っています。
RNN言語モデルは、これまで入力された単語(あるいは文字)を元に次の単語(あるいは文字)を生成します。つまり、最初の単語を何か決めないといけない制約があります。また、最初の単語を入れた、というだけの情報では、表現できる文章にも限りがあります。
これに対して、VAEでは文章全体の情報をベクトルとして、ガウス分布から生成するので、より多様な文章が生成できるという仕組みです。
データ
データはwikiのキャラ解説データを用いました。
約46000キャラ分あります。文長が長すぎると学習しないので、キャラ解説を文単位で区切っていって、単語数が50以上になる時は、後続の文を除去しました。
例文:
| 作品名 | キャラ名 | プロフィール |
|---|---|---|
| ShowByRock! | シアン | プラズマジカでヴォーカル、ギターを担当。伝説の名楽器と噂される「ストロベリーハート」と言うハート型のギターを愛用している。 |
さぁ生成してみましょう。
結果
1.キャラ設定を生成する
まず15epoch目までは中間層zをガウス分布に近づけていないので、うまく生成できません。
- 三井自らの意思で篝見抜いているオートボットで、
- メスの双子。
- 猿狐の二人の息子。
- キラーラ星人。
- 但好きな花は幼い頃に他界しており、16歳。
- シャルロット竪好きな花は竪プロレスピッコロ大魔王実際全員眼鏡をかけた金色の少女。
- そういうその反面これは良く...?
- 鈍感。第56歳。
なんかよくわかりませんね。文章として破綻してます。
これが30epochになると……、
- パッパラ隊のその他大勢の人間をベースに町の人。自分の死の真相を探るため、怪異調査部へ入学した。現在は父親が出張中で、母子の父という女性の発掘犯をしていた。
- 一年中では女学校・短位魔で、イカロスの着ぐるみの中に入っていた人物。TVアニメではジャムおじさんと恋仲だったが、後に♀になったようになった。
- 女の子で、ポジションはMF。背番号6番。色白で、紫色のドレッドヘアを束ね、後ろに流している。少林寺に似ており、空手で鍛えた足技で相手のボールを奪う。
- アサシンのもう1人、見合いをする野原家用貨屋の主人。息子に痴女さんがいる。
- 27歳。身長172cm。体重78kg。長い髭を蓄えた左眼が隻眼。
- 菜子と同じクラスの女子。バスケットボール部所属。ツインテールに眼鏡と、短めのスカート丈が特徴。天馬とは小学校からの幼馴染であり、また入学したまではへ行った。
- 一夏の友人で、部活仲間の副担任に就任する。常に眠たげで、笑った気風である。
- 小学5年生→中学受験を控えている写真好き。大先生とハムちゃんにデートを申し込んだことを告白したが、すぐに仲良くなった。
- 惑星ベジータ消滅時に古代インド人となっている。
まぁ、これもよくわからないけど(笑)。
前のよりは、文章らしいものを生成するようになります。
2.キャラ設定の加減算をする
先述した論文
Generating Sentences from a Continuous Space
には、文章の加減算の話も出ています。
この論文によると、RNN言語モデルやオートエンコーダーで得られた文の分散表現を加減算したベクトルから文を生成しても、文法的に破綻した文しか生成されないと書かれています。
VAEは中間層zでガウスノイズを追加しているので、ベクトルの値を連続的に変化させても破綻しない文章が生成できるというロジックのようです。
なのでキャラの加減算をやってみたいと思います。
キャラ二人の間のプロフィールを生成するので、キャラ二人の子供みたいなものができるとイメージしたいところ。
使用した文はとりあえず以下の文です。
| 作品名 | キャラ名 | プロフィール |
|---|---|---|
| ShowByRock! | シアン | プラズマジカでヴォーカル、ギターを担当。伝説の名楽器と噂される「スト ロベリーハート」と言うハート型のギターを愛用している。 |
| ShowByRock! | レトリー | プラズマジカでヴォーカル、ベースを担当。普段はクールに装っているが 実は恥ずかしがり屋な性格。 |
| ドラえもん | ノビスケ | のび太と静香の間にできた一人息子。知能や容姿はのび太に似ており、髪の色、体力や運動神経については静香に似ている。のび太と比べ活発なためかのび太やその子孫であるセワシに比べ肌の色が少し黒い。 |
| ドラえもん | のび太のママ | のび太のママ。旧姓は片岡。やや厳しい専業主婦。極度の動物嫌いでのび太が犬や猫を拾ってきてもすぐに発見してあのセリフである。幼い頃は非常に勝ち気な女の子で0点も取っていたようである。 |
シアンとレトリーのプロフィールをベクトル化し、その中間(内分点)のベクトルから文章を生成します。
- プラズマジカでヴォーカル、ギターを担当。しっかり者の優等生タイプで、バンド相手がいない。
- プラズマジカでヴォーカル、ギターを担当。しっかり者の優等生タイプ。兄を慕っている。泣き虫で明るい性格。
- プラズマジカでヴォーカル、ベースを担当。他の2人と違って敬語口調。
- プラズマジカでヴォーカル、ベースを担当。普段はクールに装っているが実は恥ずかしがり屋な性格。一人称はあちょ。
こんな感じです。
次に、ノビスケとのび太のママのベクトルから新しいプロフィールを生成します。
- のび太とドラえもんの長女。両親の死後、兄と共に世界中で育つ。両親の病気を理由に性格はとても気さくで、人懐こい。男の産むは美人だが、嫌って食パンに弱く、酔っぱらうとサンタクロを使役している。
なんか知らんが、のび太とドラえもんの子供が生成されてしまった。
他の文章は……、
- のび太の父方の祖父。あつしとは逆に、少し丸坊主気味。一人暮らしをしている。マイペースでお気楽な性格。いつも物事を悪い方へ出す事がいくが、明るく優しい。
- のび太とドラえもんが発見した人物。カツオと同い年。小学生時代はいじめられっ子だったらしく、彼女のおさげは他の役人にひっついていっては素直になれないほうがなんだかんだ彼の存在が自由な感じ。
- のび太とドラえもんが発見したキャラクター。アニメでの年齢設定は不明。アニメでは放送作品でベスト8の人気が有り、名前にもなった。アニメ第1作では、なぜかあたるとの手紙でガンプラスクール女子校に編入したスポーツトレーナー。
- のび太のママ。旧姓は雨宮。心優しい性格。虎徹とは同じ高校のクラスメイトで、ヒーローマニアだった。また一時帰宅日が終わりだった。しかし、まっすぐな信念を持ち、何気ない一言で他人と話す事が出来る。
こんな感じになりました。
感想
- ハイパーパラメータの調整はかなりめんどいです。しかも、ガウス分布から複数サンプリングしているので結構時間がかかります。
- 文長が長すぎると、文をうまく復元できなくなります。長文を出力する場合は、VAEで最初の文を出力して、別のRNN言語モデルとかに渡すのが現実的かもです。
- キャラの加減算をするならKLDivergenceでガウス分布に近づける必要なかったんじゃあないか。とか思います。ノイズ加えるだけで良いのかなと。実際、KLDivergenceの損失関数を加えなくても2つの文の内分点から文章が生成できています。
今後する事
- ハイパーパラメータの調整をもっとがんばる。
- ConditionalVAEとか使って生成する文章を調整できるようにする。
追記170606
もっと良いモデルが作れました。
encoderとdecoderの隠れ層の次元を半分にしました。(600→300と1200→600)
中間層zの次元は1200から200に減らしました。
その代わり、中間層zからのサンプリング数を5から10に増やしました。
こうすると、文の加減算と、オートエンコーダーによる文の復元の両方が達成できました。
モデルは、
https://github.com/ashwatthaman/LSTMVAE
の
each_case/prof/model/download_model.sh
からダウンロードできます。
サンプルの実行は
each_case/prof/sampleTrainTest.py
からお願いします。
コードが汚いので週末にでも直します。