この記事は Akatsuki Advent Calendar 2016 の1日目です。
はじめに
アカツキで、ソーシャルゲームのバックエンドやサーバーアプリ、その他つらみなどを担当している@the40sanです。
この記事では、実際に開発/運用されているソーシャルゲームインフラのアーキテクチャや、Ruby on Railsで構築された中〜大規模なAPIサーバーに関するtipsを紹介したいと思います。
インフラ構成
アカツキのソーシャルゲームは、バックエンドにAWSを利用しています。
構成例(全体)
弊社プロダクトの構成の例です。全体でみるとこんな感じになります。
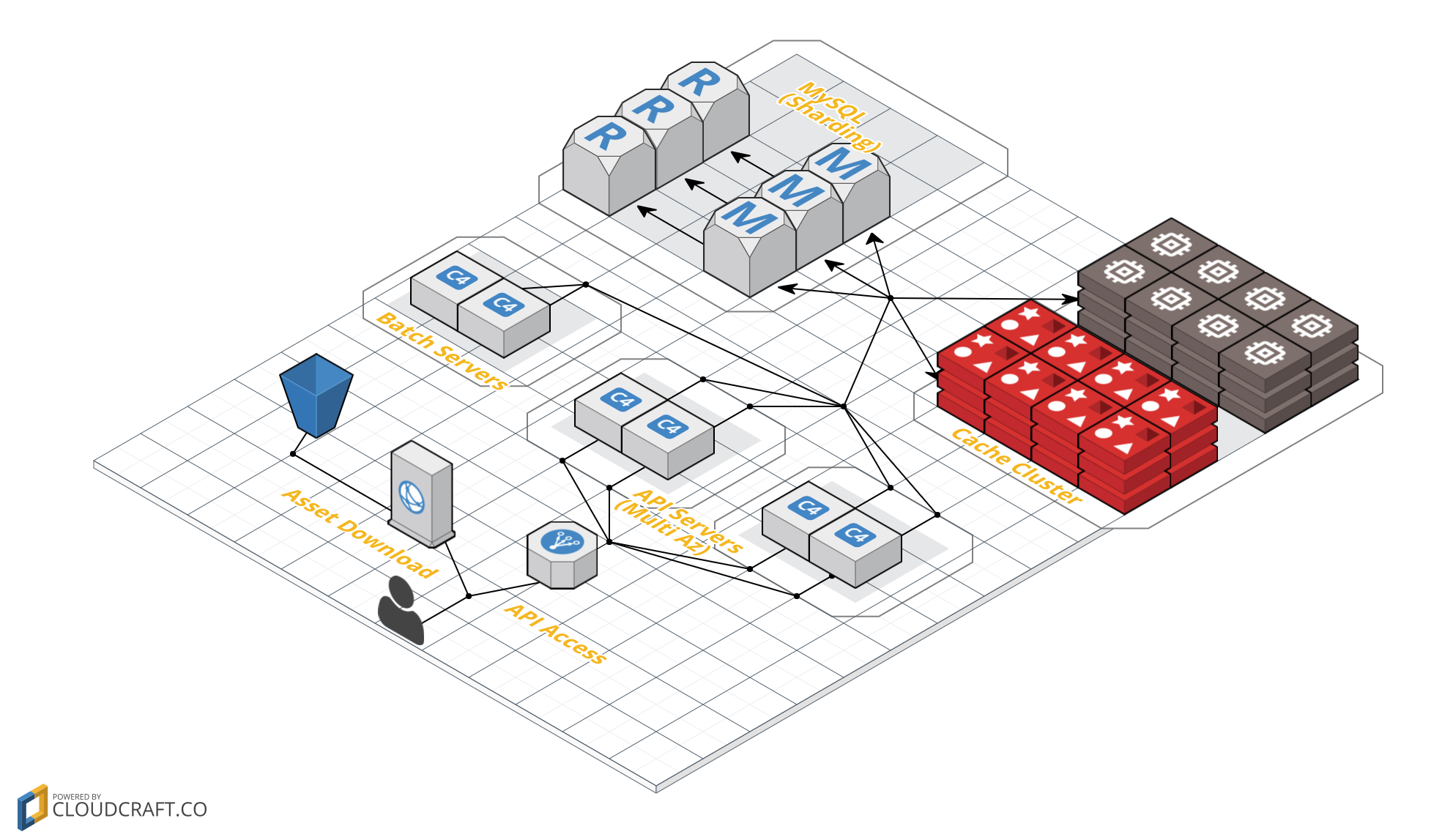
APIサーバー
ゲームのロジックなどが実装されたサーバーアプリが動いているサーバーです。
WebAPIによってアクセスします。
アカツキでは、Ruby on Rails + Unicorn + nginxの構成がほとんどです。
APIサーバーは主にEC2で構成されます。
1つのAZが落ちてしまうだけでサービス全体が落ちてしまわないよう、必ず2つ以上のAZで運用します。
APIサーバーは外部からは直接アクセスできず、ELBを通したアクセスのみ受け付けるようにSecurityGroupを設定しています。
ソーシャルゲームでは、定刻に始まるイベントやランキング戦終盤の追い込みなどで短時間に急激な負荷がかかるため、APIサーバーはいつでもスケールできるように用意されています。
APIサーバーへのデプロイは、
- 必要なソフトウェアがインストールされたプロダクト専用のAMIにCapistranoを利用してデプロイするやり方
- ECSとECRを利用してdockerでデプロイするやり方
等があります。ECSを利用する場合は、AutoScalingを併用して簡単にサーバー台数の増減ができるようになっています。
バッチサーバー
バッチ処理が必要な場合のみ存在します。
APIサーバーと同様にEC2で構成されます。
APIサーバーとの違いは、外部からのリクエストを受け付けず、バッチ処理に必要なプロセスのみが動作していることです。
データベース
ゲームのユーザーデータを管理するサーバーです。
データベースは、RDS for MySQLを利用したゆるふわ運用を行っています。
ボトルネックになったときに最もつらみを発揮するのがデータベースです。
データベースインスタンス1台辺りの性能には限界があるため、ピーク時の負荷が見積もれないのであればスケールする構成を取るべきでしょう。
アカツキのデータベースのアーキテクチャには以下の2パターンがあります。
Master-Slave
MySQLのレプリケーションを利用したSlaveを複数用意し、可能な限りReadをSlaveへ分散するアーキテクチャです。
書き込みや、書き込んだ直後のデータはMasterから取得するしか無いため、Masterがボトルネックになりやすいです。
水平分割 + Slave
データをユーザーのユニークIDやサロゲートキーなどで複数のインスタンスへ振り分けて、分割する方式です。
水平分割する場合は、サービス開始の時点で、予め16~32分割しておきます。
サービスの規模が小さい段階やサービス開始直後は1台のサーバーに複数CREATE DATABASEして仮想的に分割しておき、スケールが必要になった時点で別のインスタンスにデータを移動させることでスケールさせます。
Slaveは緊急時の昇格や、Read分散のために構築することがあります。
これからデータベースを設計する場合は迷わずこちらを選択していいと思います。
ただし、一部垂直分割が必要になったり、データベースを利用するサーバーアプリの実装難易度が上がる場合があります。
キャッシュ
インメモリのデータストアです。
データベースのデータの一部をキャッシュして負荷分散に利用したり、
Redisのソート済みセット型を利用したランキング戦のデータや、セッション情報など揮発して良いデータを格納します。
アカツキでは、ElastiCacheを利用してRedisとMemcachedを運用しています。
Redis
Redisはシングルスレッドで動作するため、インスタンスは必ずR3シリーズ(メモリ安め)を利用します。
また、メトリクスは1/コア数で監視する必要があります。(4コアでCPU使用率25%なら100%使い切ってるかも、ということです。)
ElastiCache限定の話題ですが、Redisのmaxclientsが65000までしか設定できないため(本家はuint32が上限)、大規模環境ではredisのdbを同居させないなど、コネクション数に気をつける必要があります。
アクセス頻度や、各コマンドの計算量を確認するようにしましょう。意図せず、高負荷に陥る場合があります。
Memcached
Redisと比較してMemcachedはマルチスレッドなので複数のコアを利用することができます。
Redisと違いデータ構造を保存できないので、Stringで表現できるようなデータやRailsのcache_storeに利用します。
多少雑に扱っても落ちたこと無いので、、、キャッシュアウトにさえ気をつけていれば大丈夫なんじゃないでしょうか?
キャッシュサーバーのスケール
キャッシュを利用する場合、Consistent Hashingを利用してスケールを考えます。
「ノードの数が増減した際に、キーの移動が最小限になるようなキャッシュの格納」を行い、スケールの際のパフォーマンスの劣化を最小限にしましょう、ということです。
1つのキーに対して大量のアクセスがあったりすると1ノードに対して負荷が集中してしまいますが、そういった場合は、キー名にサフィックスを付けてアプリ側で振り分けする等で負荷を分散することができます。
このあたりは、最近Redis 3.2系がElastiCacheで利用可能になったそうなので、クラスタリング等で解決できるかもしれません。
ストレージサービス
ゲーム内部で利用する画像や音声などのデータを保存しておくためのサービスです。
Amazon S3を利用しています。
CDN(Contents Delivery Network)
ストレージサービスからデータをユーザーに対して配信する際に利用します。
アカツキでは、CloudFrontを利用しています。
ユーザーの物理的な位置に対して最適な場所からデータをダウンロードさせることができるようになり、より高速にダウンロードを行うことができるようになります。
日本でローンチするのがほとんどなので、海外からの大規模なアクセスを想定せず、料金クラスは200を利用しています。
ロードバランサ
APIサーバーへのアクセスを分散するためのものです。
アカツキではElastic Load Balancer(Classic Load Balancer)を利用しています
Railsで中~大規模なAPIサーバーを書くために…
Rubyのバージョンはできるだけ最新を使おう
Rubyはバージョンアップごとにパフォーマンス・チューニングが行われているため、新しいバージョンを利用することでパフォーマンスが上がることがあります。できるだけ最新を利用するようにしましょう。
パフォーマンス・チューニング
パフォーマンス・チューニングはサーバー費用を削減するためや、サービスを安定させるために逐次行う必要があります。
パフォーマンス・チューニングの基本は、ボトルネックの発見→解決になります。
例えば、以下の様なことを行います。
- rubyprofを利用してコード自体の実行速度を見直す
-
preload等 eager loadingを利用してN+1なクエリを修正する - 一般クエリログlog, slow log等を解析して、クエリ自体のチューニングや回数の最適化を行う
- キャッシュサーバーにデータを逃がす
- etc..
Unicornを再起動するとDBが落ちる場合
現象
デプロイ時、Unicornを再起動(kill -USR2)すると、DBに大量のSHOW FULL FIELDS table_nameが飛んでしまう。
小規模なら耐えられるが、大規模だとDBがそれだけで落ちてしまい、引きずられてAPIサーバーが落ちてしまう(大障害)
ある程度の規模のRailsアプリだと必ず通る道みたいです。
原因
ActiveRecordはロード時にスキーマ情報を取得する必要があるため、SHOW FULL FIELDS table_nameを実行するようです。
これがUnicornのワーカープロセス数×読み込んだモデル数だけ起こってしまっていました。
対策方法
rake db:schema:cache:dumpを行い、db/schema_cache.dumpを予め生成しておくことで解決できます。
db/schema_cache.dumpがあると、ロード時にDBへSHOW FULL FIELDS table_nameを発行しません。
もし、ActiveRecord::Base#establish_connectionを自前で呼んだり、OctopusやTakoを利用している場合は、以下のようにコネクション毎にキャッシュを設定します。
file_name = File.join(Rails.root, 'db', 'schema_cache.dump')
ActiveRecord::Base.connection.schema_cache = Marshal.load(File.binread(filename))
まとめ
簡単なバックエンドのアーキテクチャの例や、Railsのtipsでした!